前言 这学期的实验是使用 MongoDB 来处理豆瓣的电影信息,令人没想到的是,实验难点竟然是处理这些数据,在第一次做的时候,因为较为拘谨,不敢大改实验数据和结构,虽然也能做,但是做的很丑陋,在多次与老师交流意见之后,才较为满意的完成这个实验。
值得一提的是,实验顺序和课程顺序并不同步,例如,实验二要求的设计集合模式被安排在课程后期,因此不太方便按照实验顺序写报告,那么不如直接将所有实验整合到一起,这样需求更加明了,方便完成实验。
实验要求 实验一 熟悉实验环境和实验数据
熟悉 MongoDB 数据库的操作,下载并了解实验数据。
实验二 设计 MongoDB 数据库、集合和文档
根据实验数据的特点,设计集合模式。集合和文档要求能够科学地组织和存储数据、高效方便地获取和维护数据。
实验三 将实验数据插入数据库中
将实验数据导入实验二设计好的集合中,数据导入工具不限。
实验四 使用交互式命令完成查询
连接 MongoDB 数据库,使用交互式命令查询数据。需要完成以下查询:
查询评分高于8.0分的电影名称;
查询“制片国家或者地区”为“中国大陆”的电影数量;
查询“制片国家或者地区”为“中国香港”的评分最高的电影名称;
查询2022年6月以后上映的评分高于6.0的电影名称。
实验五 使用高级程序设计语言进行数据统计
自选高级程序设计语言,自行设计界面,完成以下数据统计并将统计信息进行展示。
展示电影评分的平均分、中位数、最高分、最低分,以数据集中“评分”属性为依据进行展示;
展示电影上映数量与月份的关系:按照数据集中 “上映日期”属性进行统计,统计每个月份上映电影的数量。
实验报告 根据实验要求,简而言之就是要重构所给文件里面数据的结构并进行四个查询,再设计一个前端展示页面。按照一般的业务流程,我将实验分为数据处理、数据查询、信息统计三个部分。
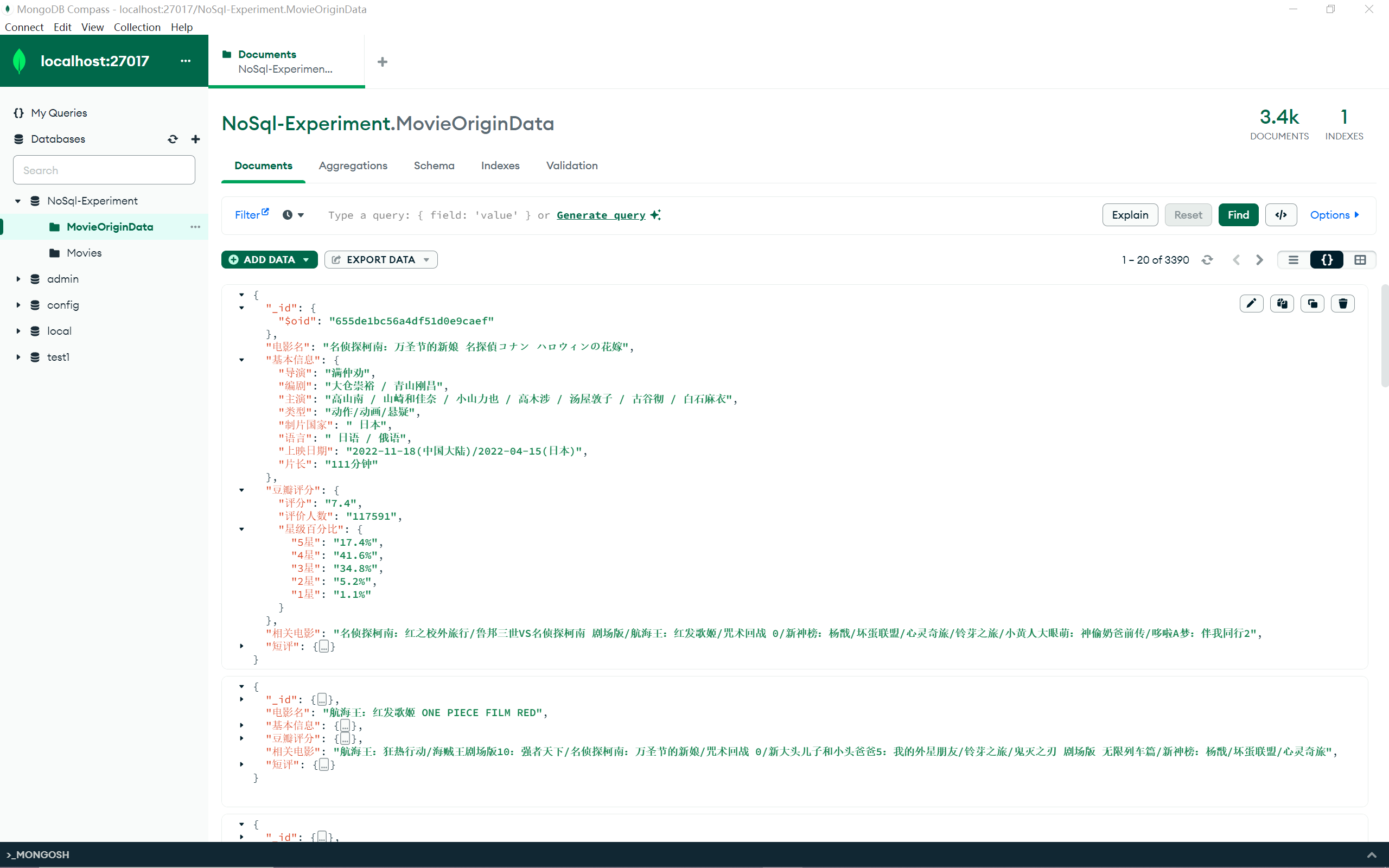
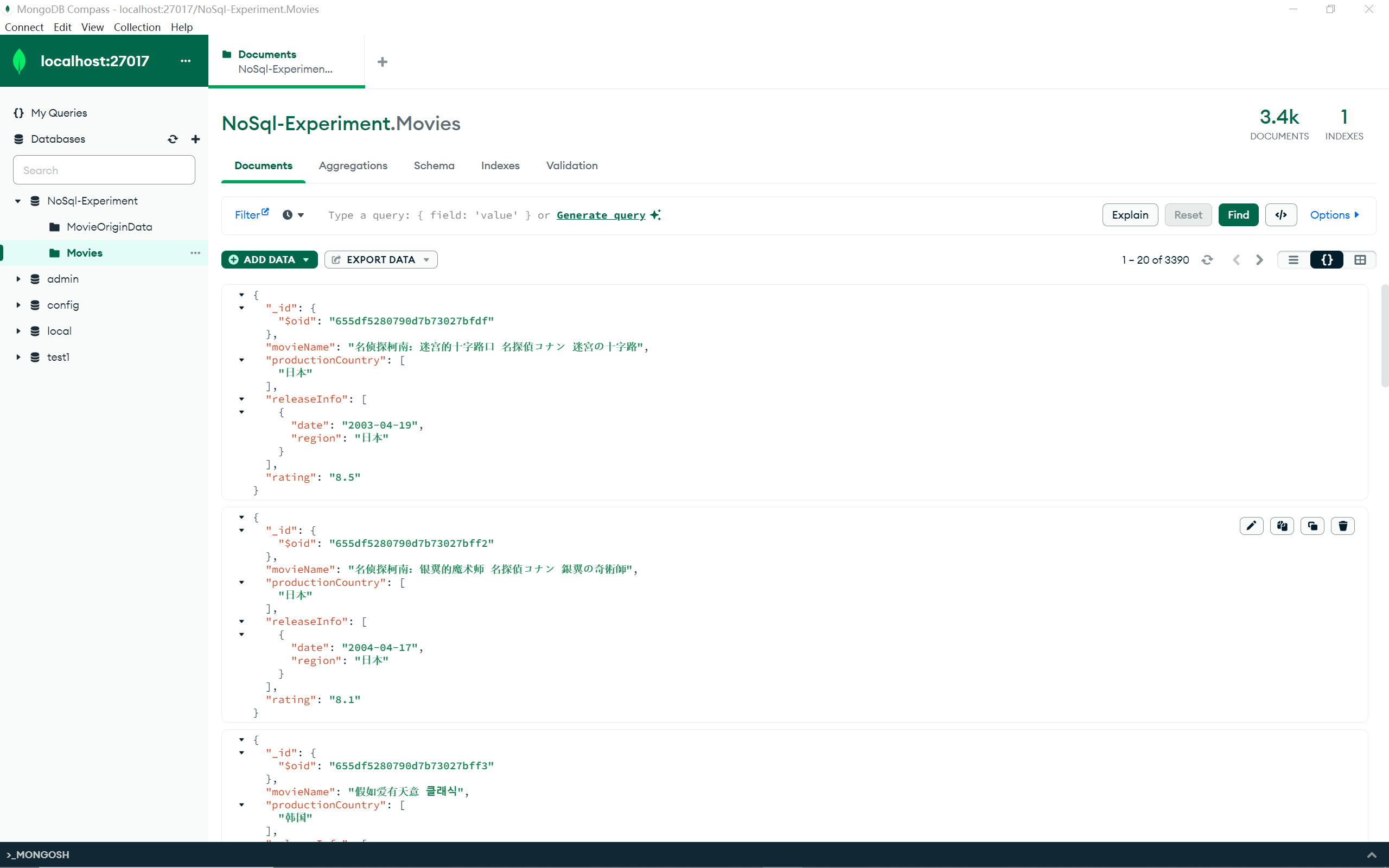
数据处理 建立 NoSql-Experiment 数据库,新建名为 MovieOriginData 的 Collection,导入 json 文件,观察数据,共有 3390 条格式相似的 Document ,选取第一个进行分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 { "_id" : { "$oid" : "65391efdd051477191e1f4d0" } , "电影名" : "名侦探柯南:万圣节的新娘 名探偵コナン ハロウィンの花嫁" , "基本信息" : { "导演" : "满仲劝" , "编剧" : "大仓崇裕 / 青山刚昌" , "主演" : "高山南 / 山崎和佳奈 / 小山力也 / 高木涉 / 汤屋敦子 / 古谷彻 / 白石麻衣" , "类型" : "动作/动画/悬疑" , "制片国家" : " 日本" , "语言" : " 日语 / 俄语" , "上映日期" : "2022-11-18(中国大陆)/2022-04-15(日本)" , "片长" : "111分钟" } , "豆瓣评分" : { "评分" : "7.4" , "评价人数" : "117591" , "星级百分比" : { "5星" : "17.4%" , "4星" : "41.6%" , "3星" : "34.8%" , "2星" : "5.2%" , "1星" : "1.1%" } } , "相关电影" : "名侦探柯南:红之校外旅行/鲁邦三世VS名侦探柯南 剧场版/航海王:红发歌姬/咒术回战 0/新神榜:杨戬/坏蛋联盟/心灵奇旅/铃芽之旅/小黄人大眼萌:神偷奶爸前传/哆啦A梦:伴我同行2" , "短评" : { } }
结合后续需要进行的查询,在这里对我们有用的信息只有电影名 、上映日期 、评分 ,所以第一步要做的就是将这三个数据取出并导入到一个新的 Collection 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use NoSql-Experiment db.MovieOriginData.aggregate([ { $project: { movieName: "$电影名" , productionCountry: "$基本信息.制片国家" , releaseInfo: "$基本信息.上映日期" , rating: "$豆瓣评分.评分" , _id: 0 } } , { $out: "Movies" } ] );
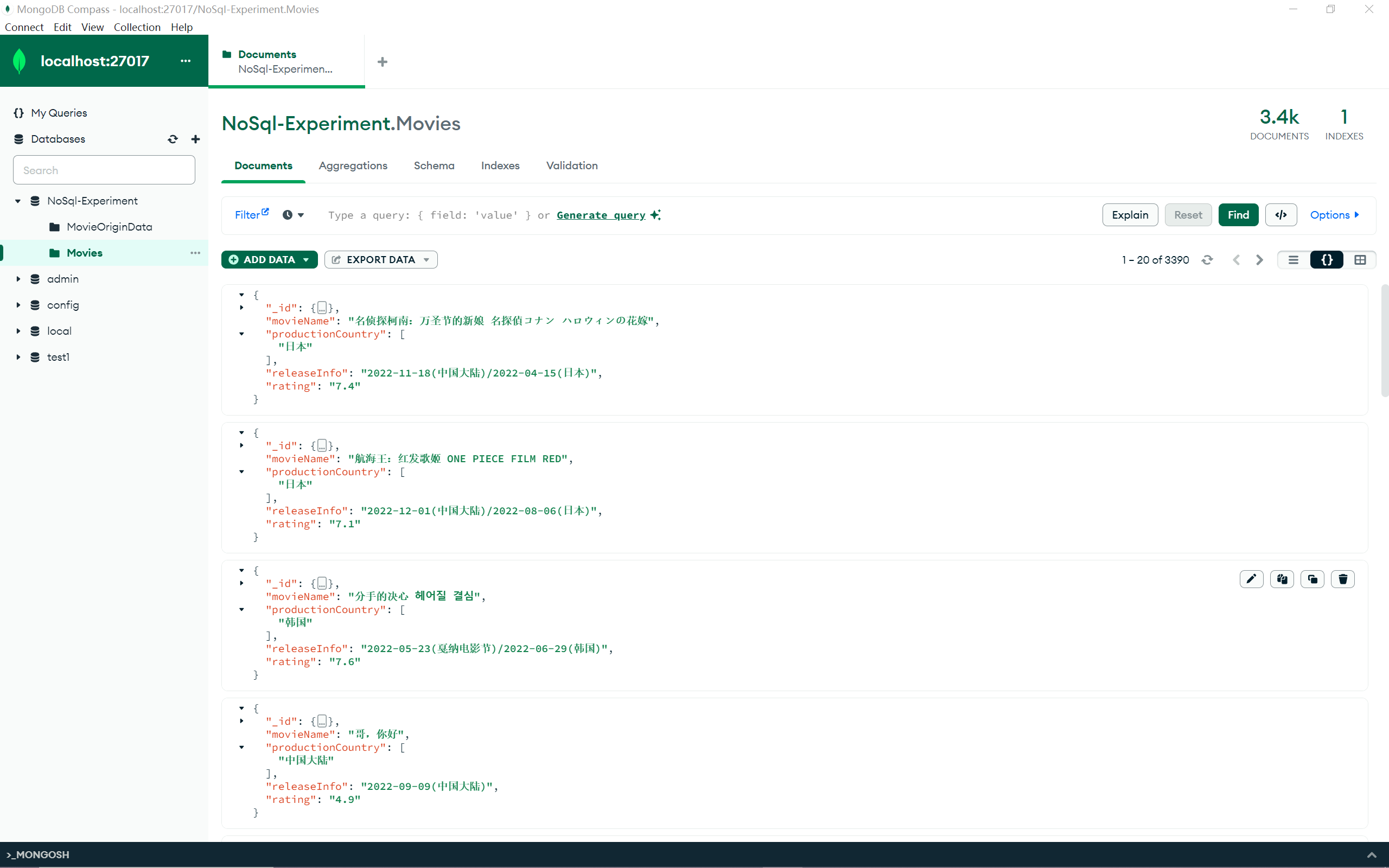
更改完成后查看一下数据样例,如下所示:
仍旧选择第一个进行查看,是我希望的格式。
1 2 3 4 5 6 7 8 9 { "_id" : { "$oid" : "655de1cf0790d7b730278a29" } , "movieName" : "名侦探柯南:万圣节的新娘 名探偵コナン ハロウィンの花嫁" , "productionCountry" : " 日本" , "releaseInfo" : "2022-11-18(中国大陆)/2022-04-15(日本)" , "rating" : "7.4" }
信息填补 按理来说我应该在前一步就审查有无缺失的数据,但是原始数据字段太多,懒得敲了,这里直接查一下筛选的有效信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 db.Movies .find ({ $or : [ { movieName : { $exists : false } }, { movieName : "" }, { productionCountry : { $exists : false } }, { productionCountry : "" }, { releaseInfo : { $exists : false } }, { releaseInfo : "" }, { rating : { $exists : false } }, { rating : "" } ] }).count ()
总计共有 21 条数据缺失,其中包括《您好,北京》共计一部电影评分缺失 ,《举起手来!》、《神奇四侠》、《犯罪分子》、《霹雳贝贝》、《阿凡提的故事之偷东西的驴》、《人蛇大战》、《一个和八个》、《老鼠嫁女》、《荒唐童话》、《西蒙娜·德·波伏娃:为什么我是女性主义者》、《道成寺》、《刺猬背西瓜》、《黑三角》、《贝尔斯通之狐》、《麦当劳桥上的未婚妻》、《女理发师》、《代用品》、《出港的船》、《机械芭蕾》、《拔萝卜》共计 20 部电影上映日期缺失 。
通过查询相关百科,按照 YYYY-MM-DD(地区) 的格式(注意:YYYY-MM-DD(地区)的括号为半角 ),人工补全缺失的信息,其中少数为爬取时缺失,在豆瓣上可以查询到该电影的完整资料,大多数为电影上映年代较为久远,在豆瓣上体现为 电影名(上映年份) 这种格式,从而导致数据缺失,顺带一提,在补足数据时遇到同名电影优先选取年份更早的 ,若没有具体的上映日期,补足的数据格式为 YYYY(地区) 。
初步处理 观察数据,发现 productionCountry 和 releaseInfo 作为 String 类型,其中却包含多条用 / 隔开的信息,接着设计集合模式,将这两个字段改为数组 来存储相关信息。
先切分较为简单的 productionCountry ,并去除切分后数组元素前后的空格:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 db.Movies .aggregate ([ { $addFields : { productionCountry : { $map : { input : { $split : [{ $trim : { input : "$productionCountry" } }, "/" ] }, as : "country" , in : { $trim : { input : "$$country" } } } } } }, { $out : "Movies" } ]);
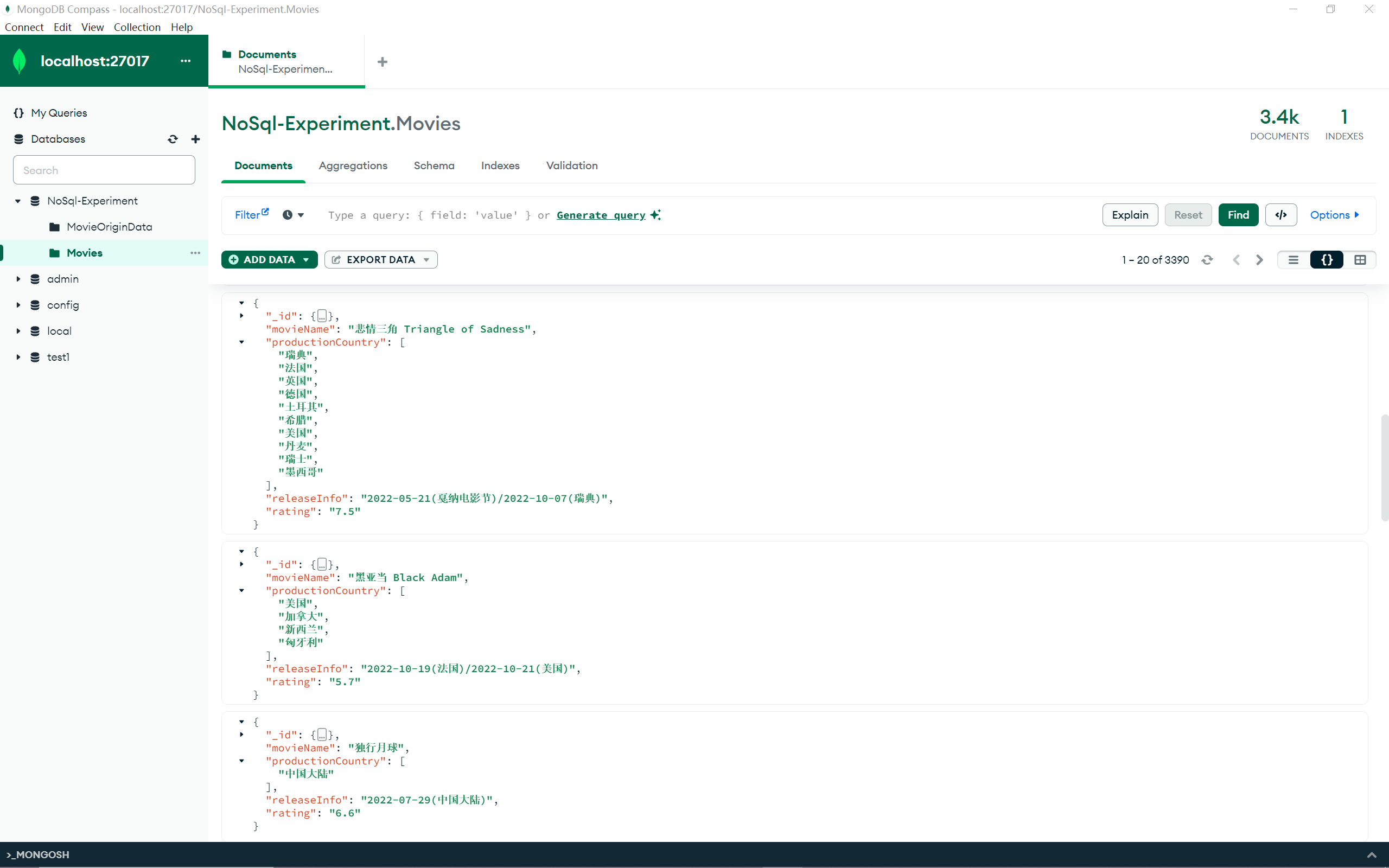
处理完成后结果如下:
上映日期的处理较为复杂,先简单梳理一下几种日期格式。首先是缺地区型 ,即只含有年份,可能含有月份和日期,即形如 YYYY(-MM)(-DD) 的数据。
1 2 3 4 5 6 db.Movies .find ({ "releaseInfo" : { $regex : /^(?:\d{4}(?:-\d{2}(?:-\d{2})?)?)$/ } }).count ()
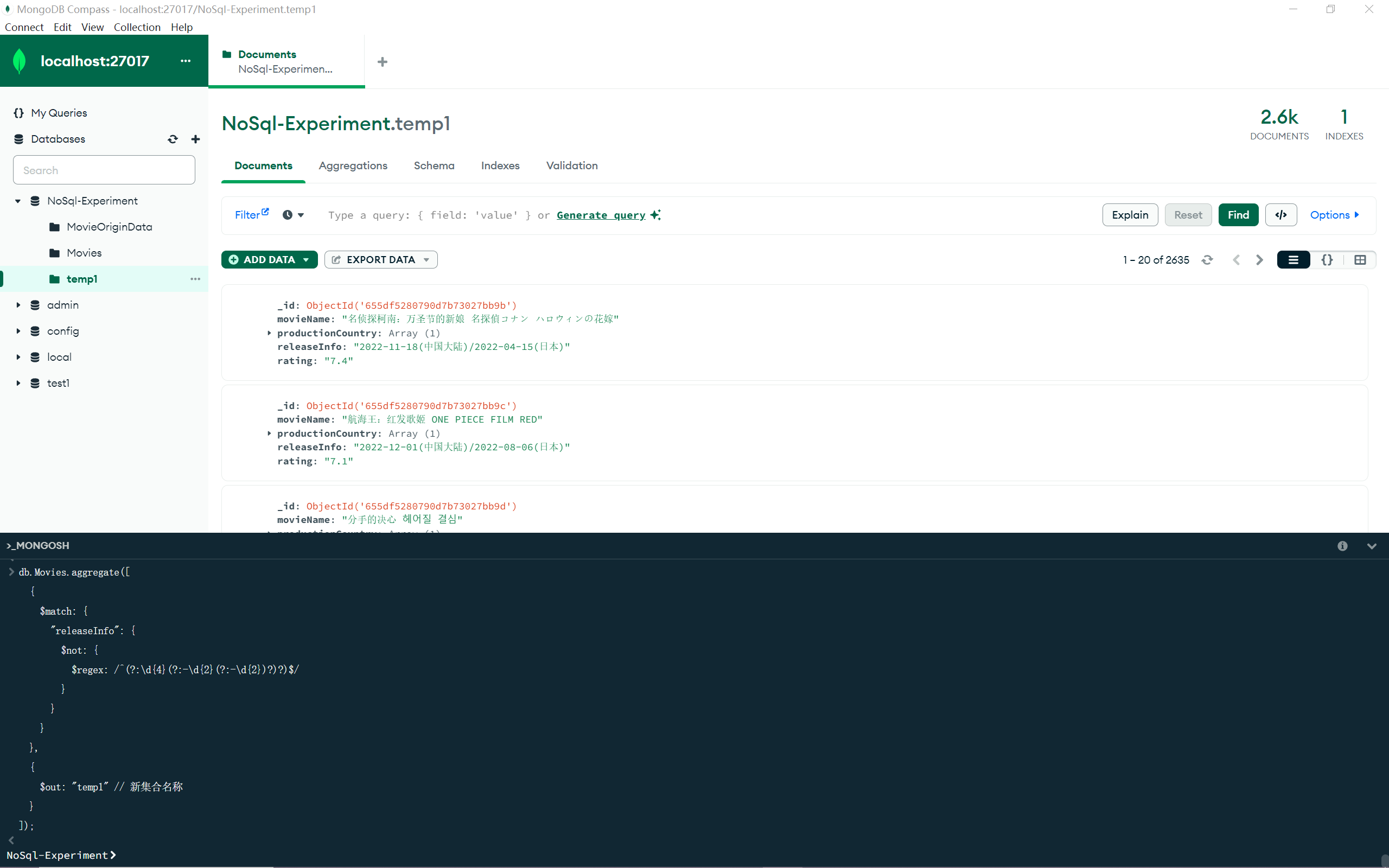
为方便后续处理,这里将剩下的 2635 个数据导出为 temp1,操作如图所示:
经过观察,其中绝大多数数据为标准型 ,即含有一个或多个形如 YYYY-MM-DD(地区) 的上映日期,但其中夹杂有多地区型 (形如 YYYY-MM-DD(地区/地区) )和缺日月型 (形如 YYYY(-MM)(-DD)(地区)),并且这两种格式的数据不会出现在一个 document 中(处理完才有底气说这话的,一开始并不知道)。
1 2 3 4 5 6 db.temp1.find({ "releaseInfo" : { $regex: /\d{ 4 } -\d{ 2 } -\d{ 2 } \([ ^\)] +\/[ ^\)] +\)/ } } )
同理,将其他的 2544 个数据导出为 temp2,操作如图所示:
在剩下的 2544 个数据中,筛选出缺日月型的数据
1 2 3 4 5 6 db.temp2 .find ({ "releaseInfo" : { $regex : /\d{4}(-\d{2})?\([^\)]+\)/ } }).count ()
此时还剩下 2402 条数据,理论上剩下的日期应全为只包含标准型的数据,下面来验证我的想法。先将 releaseInfo 按照 / 划分为数组。
1 2 3 4 5 6 7 8 9 10 11 12 db.temp3 .aggregate ([ { $addFields : { releaseInfo : { $split : ["$releaseInfo" , "/" ] } } }, { $out : "temp3" } ]);
在集合 temp3 中查询不符合 YYYY-MM-DD(地区) 的文档,并导出为 temp4,如下所示,temp4 为空,即为 temp3 中全为标准型数据。
统一日期 在了解上映日期可能有的格式之后,返回 Movies 处理数据、统一格式。当然,也可以直接处理 temp 文档再进行合并,但是想挑战自我,在更为复杂的环境中处理这些数据。
首先处理缺地区型的数据,我选择将 productionCountry 的第一个元素作为地区信息进行补足。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.collection .updateMany ( { "releaseInfo" : { $regex : /^(?:\d{4}(?:-\d{2}(?:-\d{2})?)?)$/ } }, [{ $set : { "releaseInfo" : { $concat : ["$releaseInfo" , "(" , { $arrayElemAt : ["$productionCountry" , 0 ] }, ")" ] } } }] )
然后处理多地区型的数据,将 YYYY-MM-DD(地区/地区)格式中地区之间的 / 替换为 & 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 db.temp1 .updateMany ( { "releaseInfo" : { $regex : /(?<![0-9])\/(?![0-9])/ } }, [{ $set : { "releaseInfo" : { $function : { body : function (releaseInfo ) { return releaseInfo.replace (/(?<![0-9])\/(?![0-9])/g , '&' ); }, args : ["$releaseInfo" ], lang : "js" } } } }] )
现在数据集中只含有缺日月型的数据,可以放心的使用 $split 根据 / 切分为数组。
1 2 3 4 5 6 7 8 9 10 11 12 db.Movies .aggregate ([ { $addFields : { releaseInfo : { $split : ["$releaseInfo" , "/" ] } } }, { $out : "Movies" } ]);
然后对缺少月和日的日期使用 01 补足,将格式统一为 YYYY-MM-DD(地区)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 db.Movies .aggregate ([ { $addFields : { releaseInfo : { $map : { input : "$releaseInfo" , as : "date" , in : { $let : { vars : { dateAndRegionSplit : { $split : ["$$date" , "(" ] } }, in : { $let : { vars : { dateParts : { $split : [{ $arrayElemAt : ["$$dateAndRegionSplit" , 0 ] }, "-" ] } }, in : { $concat : [ { $arrayElemAt : ["$$dateParts" , 0 ] }, "-" , { $cond : [{ $gte : [{ $size : "$$dateParts" }, 2 ] }, { $arrayElemAt : ["$$dateParts" , 1 ] }, "01" ] }, "-" , { $cond : [{ $gte : [{ $size : "$$dateParts" }, 3 ] }, { $arrayElemAt : ["$$dateParts" , 2 ] }, "01" ] }, { $cond : [{ $gte : [{ $size : "$$dateAndRegionSplit" }, 2 ] }, { $concat : ["(" , { $arrayElemAt : ["$$dateAndRegionSplit" , 1 ] }] }, "" ] } ] } } } } } } } } }, { $out : "Movies" } ]);
此时再次用正则进行筛选,将不符合的数据导出为 temp ,可以看到 temp 为空,也就是说 Movies 数据格式处理完成。
集合模式 此时我想将 releaseInfo 中的数据进行细分,初步想法是将上映日期分为 first ,second 等,于是查询了 releaseInfo 中最多元素的电影,结果为《新蝙蝠侠》等电影,有 4 个上映日期,我想对 releaseInfo 中的元素进行排序,保存为第n次上映的格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.Movies .aggregate ([ { $project : { movieName : 1 , releaseDateCount : { $size : "$releaseInfo" } } }, { $sort : { releaseDateCount : -1 } }, { $limit : 1 } ]);
可是,在与老师交流意见之后,老师建议我使用内嵌文档进行存储,理由如下:
查询效率 :由于相关数据被存储在同一个文档中,因此可以通过单个查询来检索完整的数据对象,这减少了需要多个查询来拼接数据的需求。这通常意味着更快的读取性能和简化的查询逻辑。数据一致性 :内嵌文档使得数据更新操作更加原子化和一致。当一个文档的多个部分需要一起更新时,内嵌文档的使用可以确保这些更新在单个操作中一起发生,减少了数据不一致的风险。文档模型的灵活性 :MongoDB 的文档模型提供了高度的灵活性,使得在文档中嵌入数组和其他文档成为可能。这种灵活性使得模型能够更好地表示复杂的数据结构。避免连接操作 :在关系型数据库中,经常需要使用连接操作来组合来自不同表的数据。在 MongoDB 中,通过内嵌文档,这种需求可以降低或消除,因为相关数据已经在同一个地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 db.Movies .aggregate ([ { $addFields : { releaseInfo : { $map : { input : "$releaseInfo" , as : "dateStr" , in : { $let : { vars : { dateParts : { $split : ["$$dateStr" , "(" ] } }, in : { date : { $arrayElemAt : ["$$dateParts" , 0 ] }, region : { $arrayElemAt : [ { $split : [{ $arrayElemAt : ["$$dateParts" , 1 ] }, ")" ] }, 0 ] } } } } } } } }, { $out : "Movies" } ]);
修改完成后,数据如下:
数据查询 在完成数据清洗的工作之后,就可以开始做查询实验了。
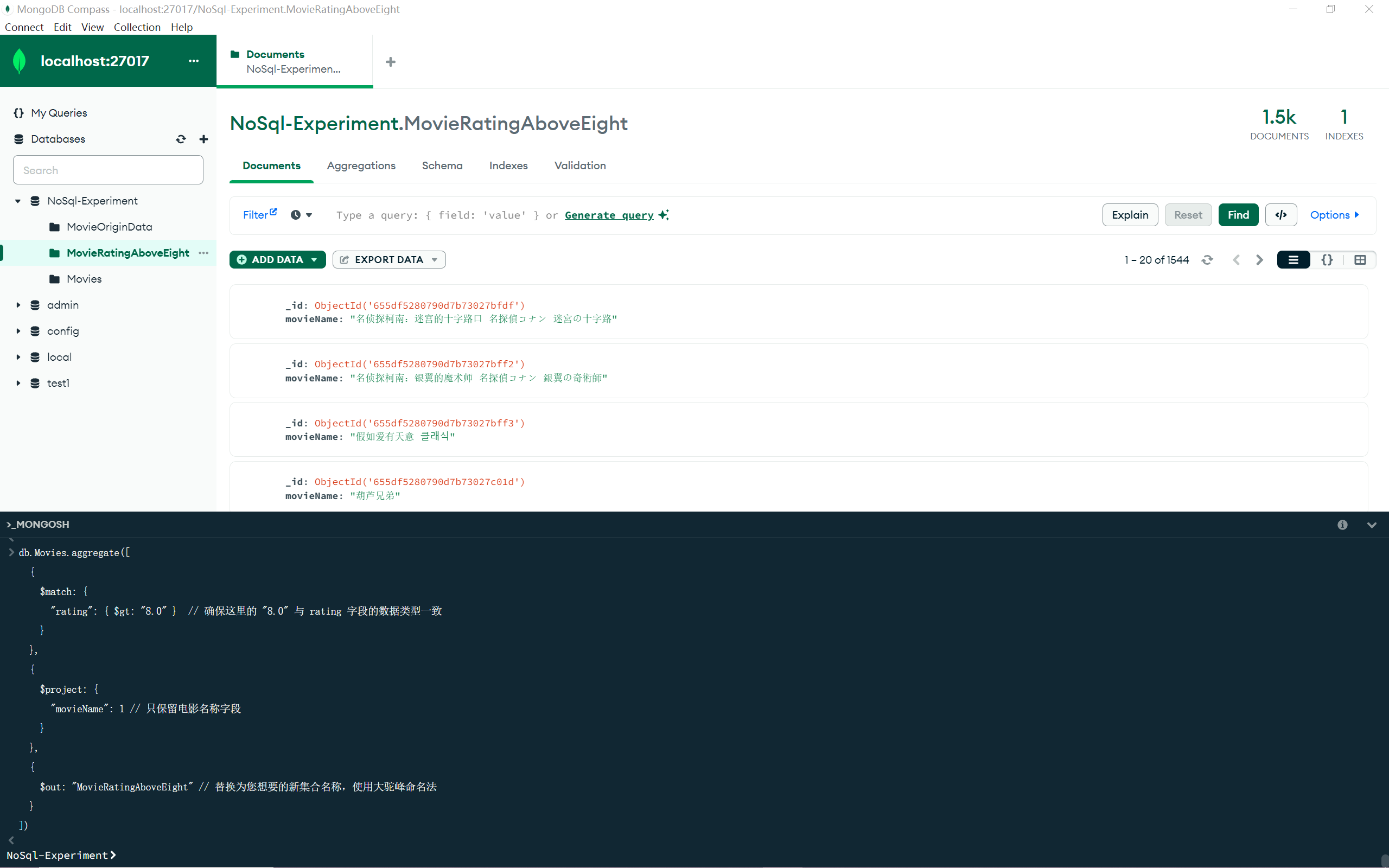
1.查询评分高于8.0分的电影名称;
1 2 3 4 5 6 7 8 9 10 db.Movies .aggregate ([ { $match : { "rating" : { $gt : "8.0" } } }, { $out : "MovieRatingAboveEight" } ])
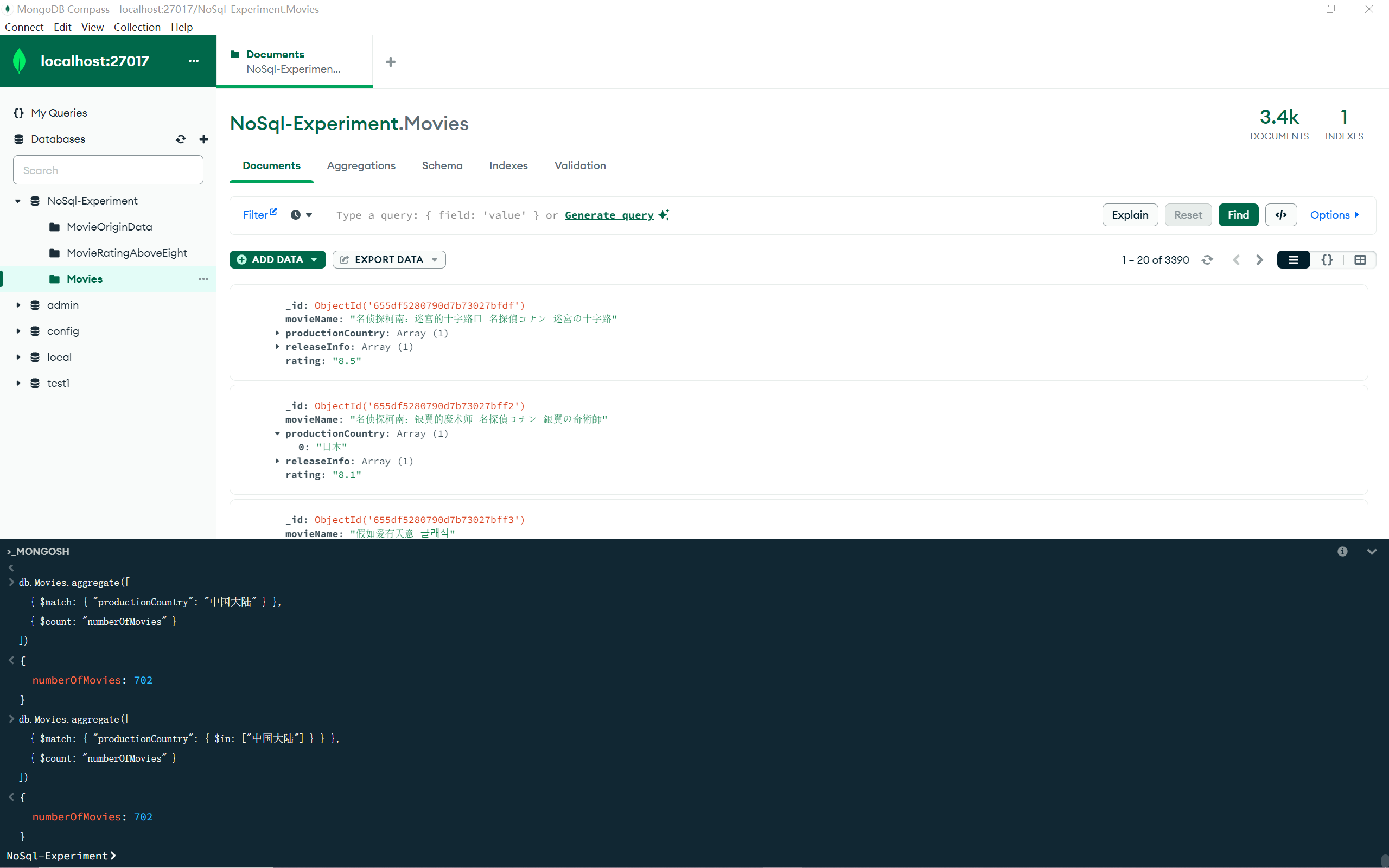
2.查询“制片国家或者地区”为“中国大陆”的电影数量;
1 2 3 4 5 db.Movies .aggregate ([ { $match : { "productionCountry" : "中国大陆" } }, { $count : "numberOfMovies" } ])
1 2 3 4 5 db.Movies .aggregate ([ { $match : { "productionCountry" : { $in : ["中国大陆" ] } } }, { $count : "numberOfMovies" } ])
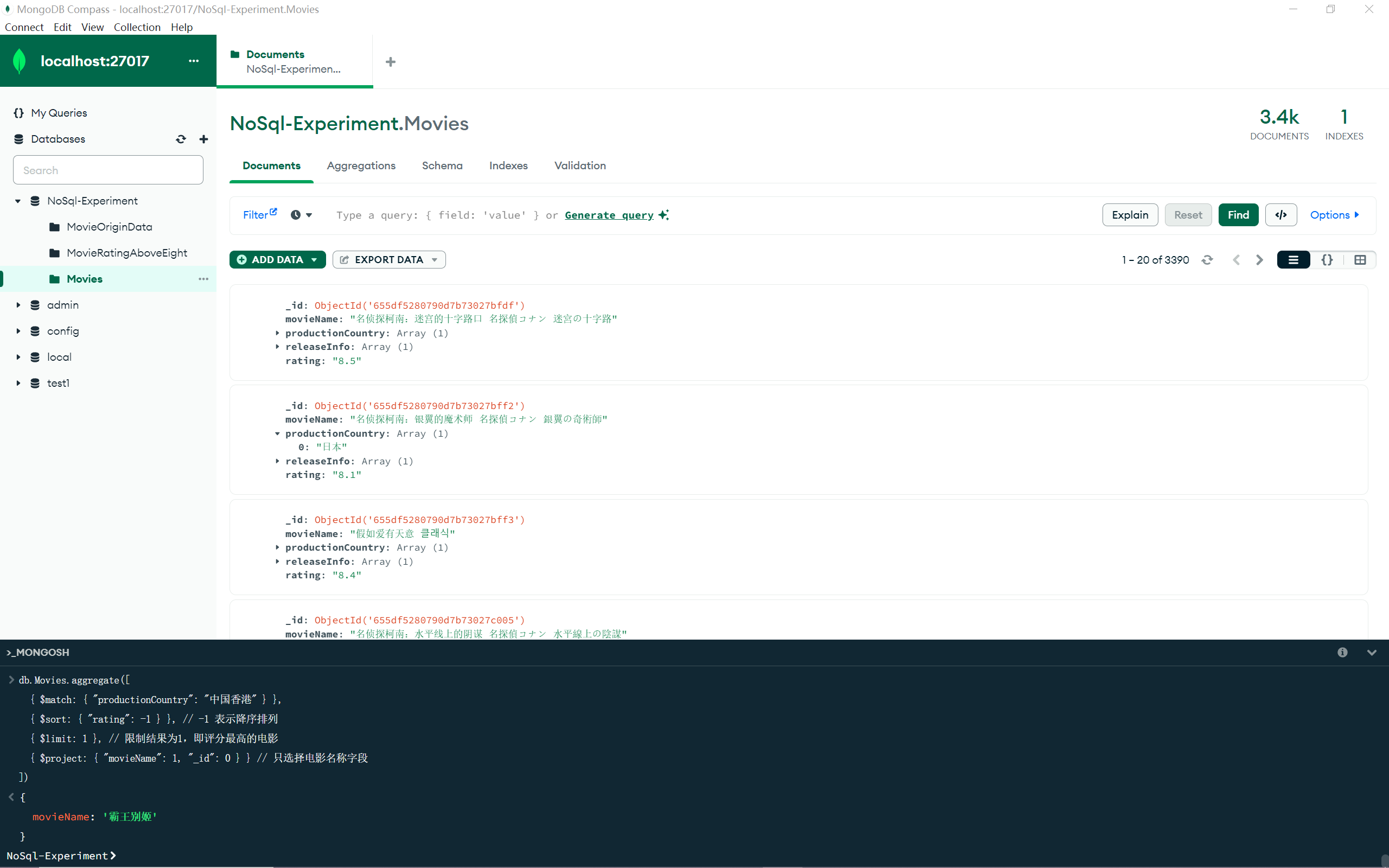
3.查询“制片国家或者地区”为“中国香港”的评分最高的电影名称;
1 2 3 4 5 6 7 db.Movies .aggregate ([ { $match : { "productionCountry" : "中国香港" } }, { $sort : { "rating" : -1 } }, { $limit : 1 }, { $project : { "movieName" : 1 , "_id" : 0 } } ])
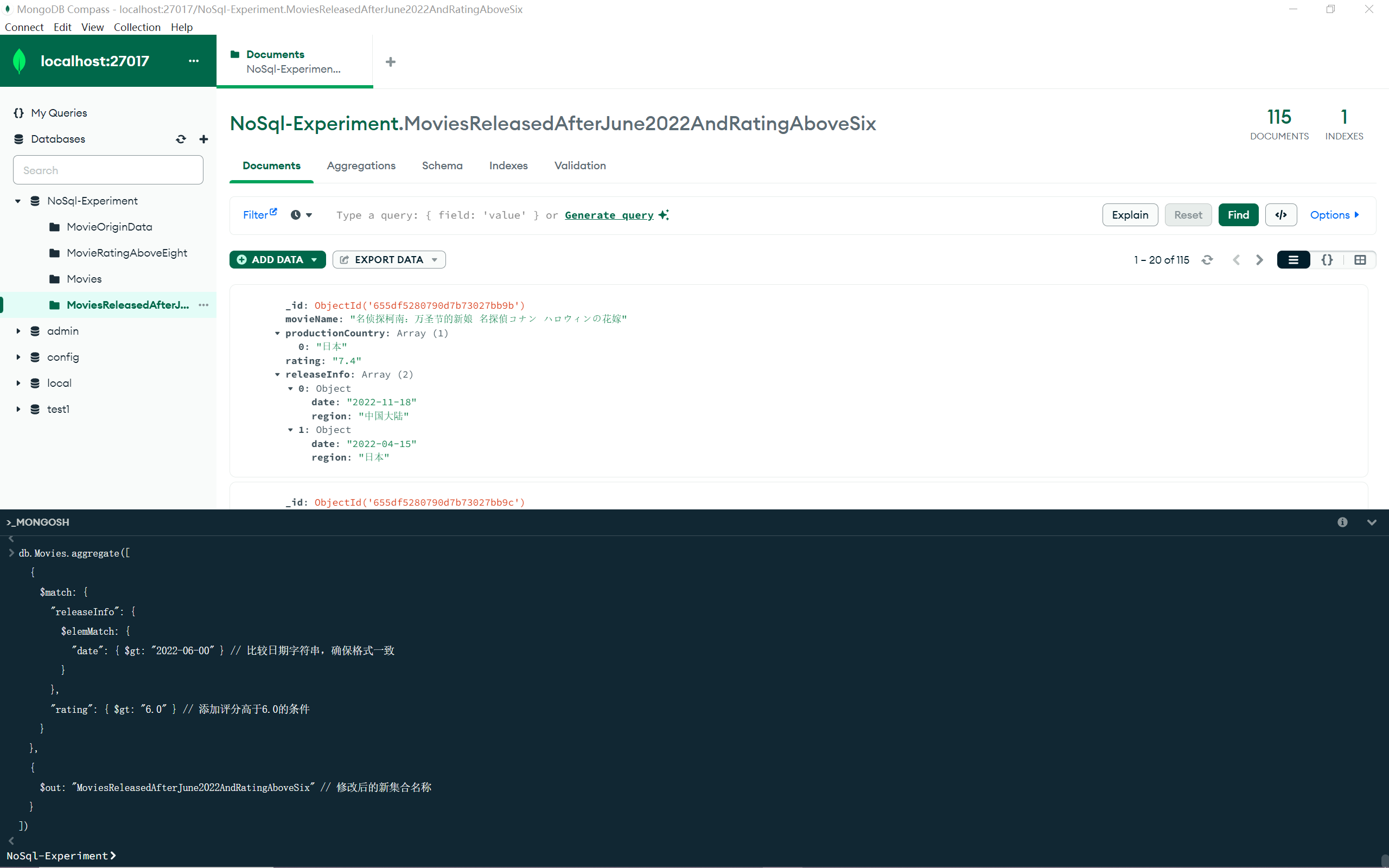
4.查询2022年6月以后上映的评分高于6.0的电影名称。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 db.Movies .aggregate ([ { $match : { "releaseInfo" : { $elemMatch : { "date" : { $gt : "2022-06-00" } } }, "rating" : { $gt : 6.0 } } }, { $out : "MoviesReleasedAfterJune2022AndRatingAboveSix" } ])
信息统计 终于来到了数据可视化的环节,一切开始变得熟悉起来,经过短暂思考过后,我打算采用 Springboot + MongoTemplete 来搭建后端提供 api 接口,前端用 React + Echarts 来制作可交互的可视化图表。其实细想实验要求,我大可以直接使用聚合函数统计出想要的数据,然后直接写死在前端页面里面,数据也不多,但是为了深入了解如何使用 java 来控制 MongoDB 数据库,模拟真实的业务场景,我决定将逻辑层放在后端,使用 MongoTemplete 提供的方法完成数据的统计。
完整代码可在我 github 中 MongoDBExperiment 仓库进行查看,其中包含清洗之后的 Movies 数据。
后端设计 基础结构 后端采用经典的 MVC 架构,也就是实体层、视图层和控制层,完整的项目结构如下。
1 2 3 4 5 6 7 8 9 10 11 12 ├── NoSqlExperiment | ├── config | │ └── WebConfig | ├── controller | │ └── MovieController | ├── model | │ └── Movie | ├── service | │ └── MovieService | ├── SpringBootMongoApplication ├── resources | └── application.properties
在新建一个使用 Maven 的项目之后,引入如下依赖让它变成 MongoDB 的形状。
1 2 3 4 5 6 7 8 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-mongodb</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency >
然后在 properties 文件中进行 MongoDB 数据库的信息配置
1 2 3 4 5 6 7 server.port=8082 spring.data.mongodb.authentication-database=admin spring.data.mongodb.database=NoSql-Experiment spring.data.mongodb.username=admin spring.data.mongodb.password=123456 spring.data.mongodb.host=localhost spring.data.mongodb.port=27017
根据清洗后数据的结构创建 Movie 实体类,使用 @Document 注解绑定 Movies ,在上述处理的过程中,我将 ReleaseInfo 转化为内嵌文档进行数据存储,所以这里要建一个 ReleaseInfo 类来获取表中的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Data @Document(collection = "Movies") public class Movie { @Id private String id; private String movieName; private List<String> productionCountry; private List<ReleaseInfo> releaseInfo; private String rating; } @Data class ReleaseInfo { private String date; private String region; }
为了简化代码中复杂的 getter 和 setter 方法,这里使用 lombok 包中的 @Data 注解,具体使用方法就不展开了。
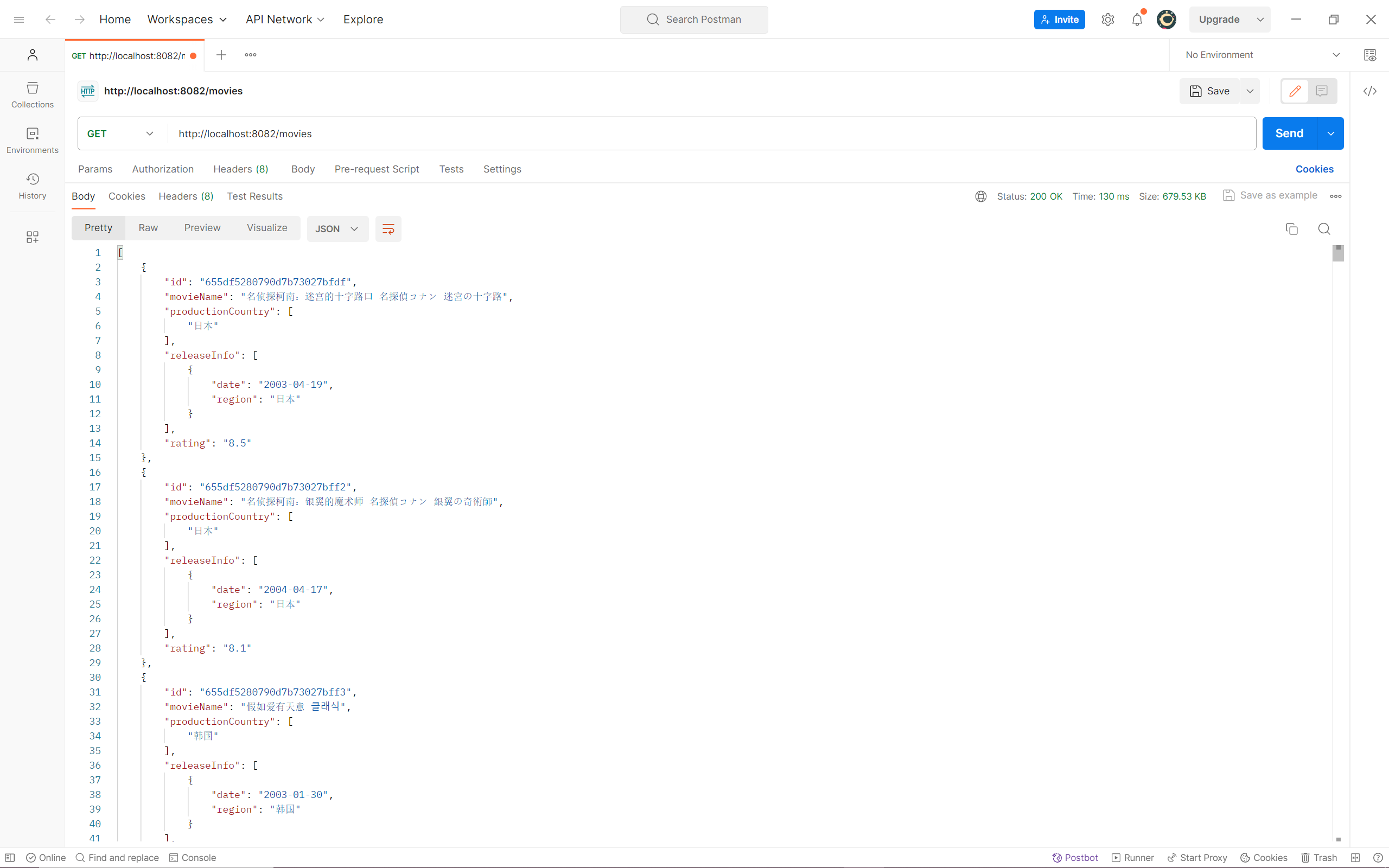
接着搭建业务层,使用 MongoTemplate 来与数据库进行交互,这里先准备一个 getAllMovies() 方法用于测试使用。
1 2 3 4 5 6 7 8 9 10 @Service public class MovieService { @Autowired private MongoTemplate mongoTemplate; public List<Movie> getAllMovies () { return mongoTemplate.findAll(Movie.class); } }
随后开始搭建控制层,在里面申明 MovieService 之后,就可以调用其中的方法了。
1 2 3 4 5 6 7 8 9 10 11 12 @RestController @RequestMapping("/movies") public class MovieController { @Autowired private MovieService movieService; @GetMapping public List<Movie> getAllMovies () { return movieService.getAllMovies(); } }
这里我使用 Postman 进行接口测试,可以看到数据成功的返回了。
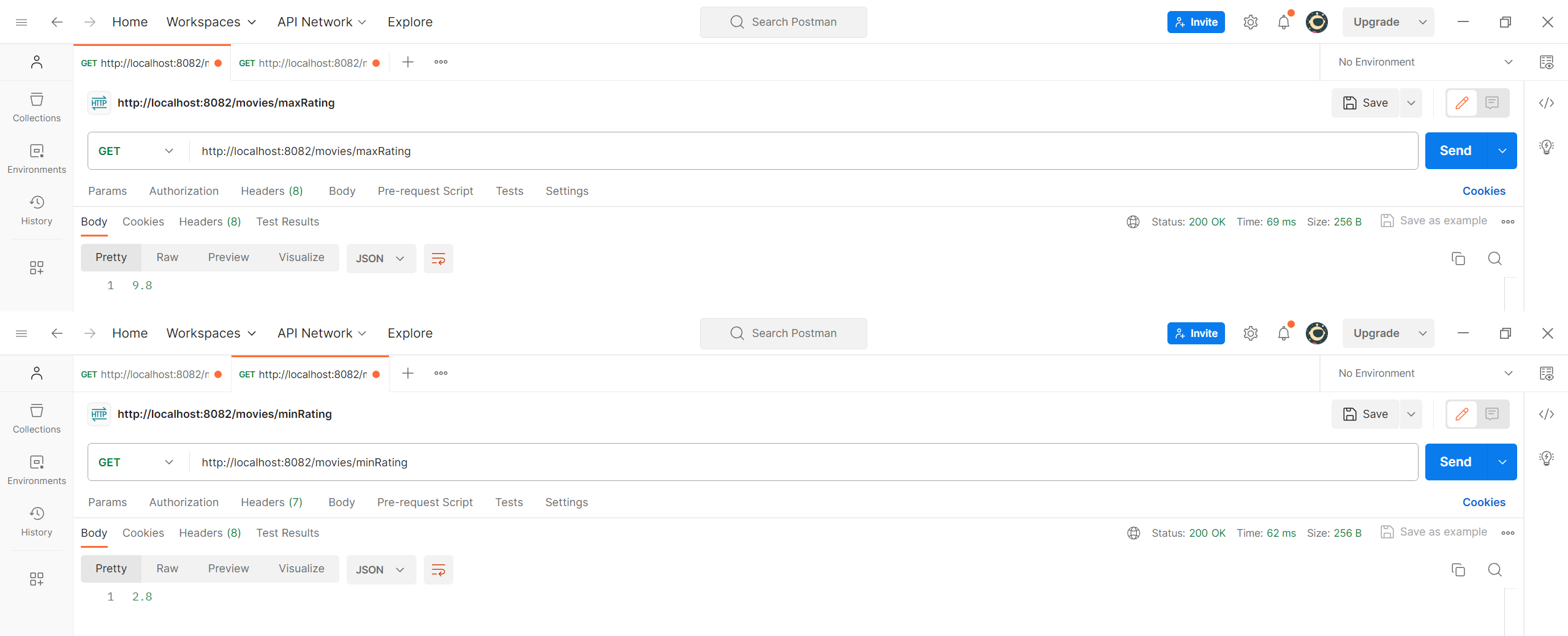
业务层编写 接下来开始按照实验要求实现具体功能,从最简单的最高分和最低分开始,先在 MovieService 中创建 getMaxRating() 和 getMinRating() 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public Double getMaxRating () { List<Movie> movies = mongoTemplate.findAll(Movie.class); return movies.stream() .map(Movie::getRating) .map(Double::parseDouble) .max(Comparator.naturalOrder()) .orElse(null ); } public Double getMinRating () { List<Movie> movies = mongoTemplate.findAll(Movie.class); return movies.stream() .map(Movie::getRating) .map(Double::parseDouble) .min(Comparator.naturalOrder()) .orElse(null ); }
然后在 MovieController 中创建接口。
1 2 3 4 5 6 7 8 9 @GetMapping("/maxRating") public Double getMaxRating () { return movieService.getMaxRating(); } @GetMapping("/minRating") public Double getMinRating () { return movieService.getMinRating(); }
重启项目进行测试,成功的返回了电影评分的最大值和最小值。
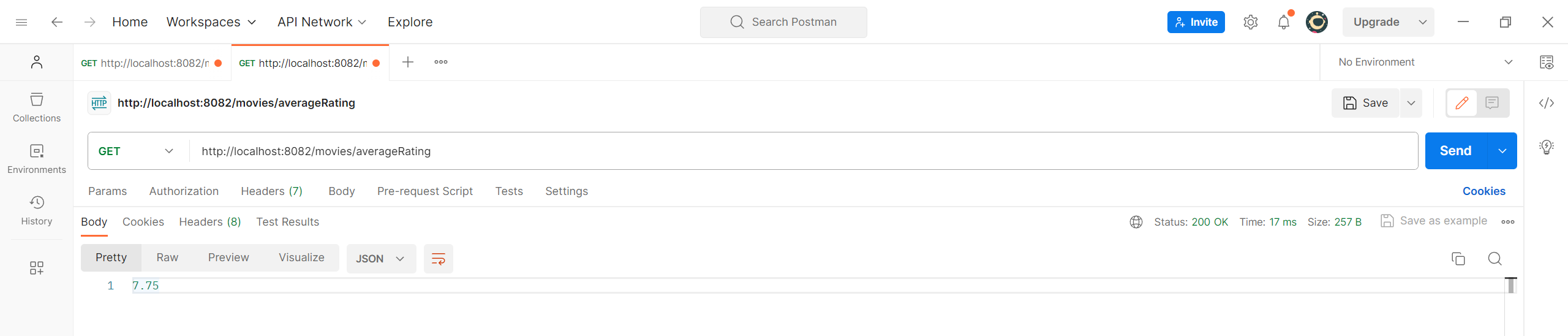
接下来处理电影的平均分,为了让报告简介一点,将思路以注释的形式展现在代码片段中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public Double getAverageRating () { TypedAggregation<Movie> aggregation = Aggregation.newAggregation( Movie.class, Aggregation.project() .andExpression("toDouble(rating)" ).as("ratingAsDouble" ), Aggregation.group().avg("ratingAsDouble" ).as("averageRating" ) ); AggregationResults<Document> result = mongoTemplate.aggregate(aggregation, Document.class); Document averageRatingResult = result.getUniqueMappedResult(); return averageRatingResult != null ? averageRatingResult.getDouble("averageRating" ) : null ; } @GetMapping("/averageRating") public Double getAverageRating () { Double averageRating = movieService.getAverageRating(); if (averageRating != null ) { return BigDecimal.valueOf(averageRating) .setScale(2 , RoundingMode.HALF_UP) .doubleValue(); } return null ; }
结合之后的前端页面制作,这里我选择保留两位小数,方便后续处理。
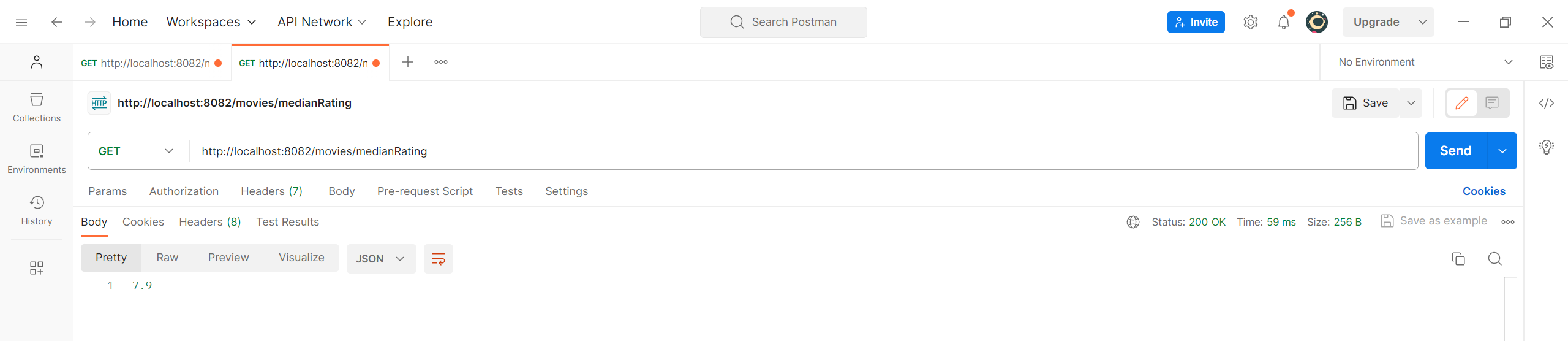
最后处理最难的中位数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public Double getMedianRating () { List<Movie> movies = mongoTemplate.findAll(Movie.class); List<Double> ratings = movies.stream() .map(Movie::getRating) .map(Double::parseDouble) .sorted() .collect(Collectors.toList()); if (ratings.isEmpty()) { return null ; } int middle = ratings.size() / 2 ; if (ratings.size() % 2 == 1 ) { return ratings.get(middle); } else { return (ratings.get(middle - 1 ) + ratings.get(middle)) / 2.0 ; } } @GetMapping("/medianRating") public Double getMedianRating () { return movieService.getMedianRating(); }
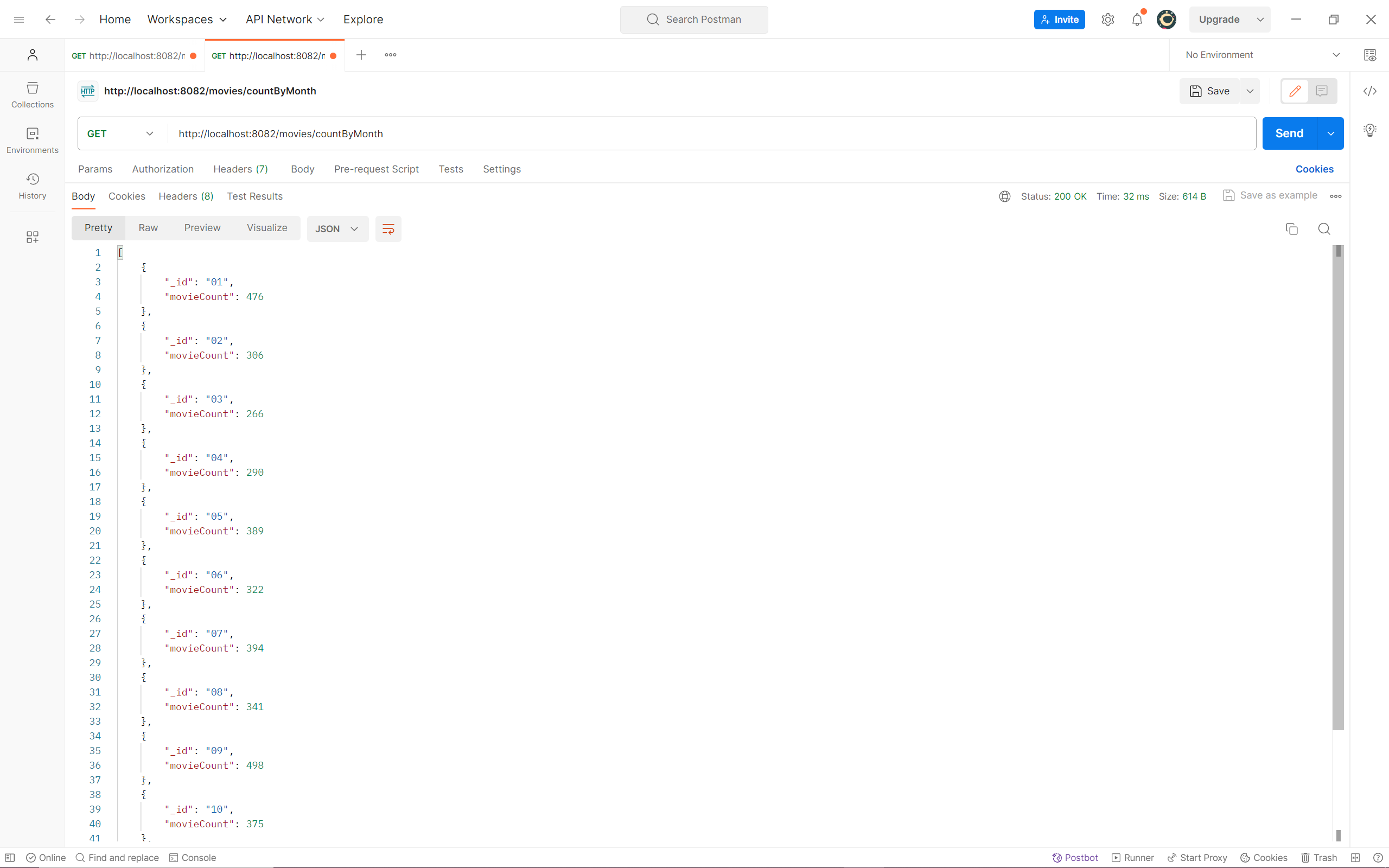
接着做第二个查询业务,展示电影上映数量与月份的关系:按照数据集中 “上映日期” 属性进行统计,统计每个月份上映电影的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public List<Document> getMovieCountByMonth () { Aggregation aggregation = Aggregation.newAggregation( Aggregation.unwind("releaseInfo" ), Aggregation.project() .andExpression("substr(releaseInfo.date, 5, 2)" ).as("month" ), Aggregation.group("month" ).count().as("movieCount" ), Aggregation.sort(Sort.Direction.ASC, "_id" ) ); AggregationResults<Document> results = mongoTemplate.aggregate(aggregation, "Movies" , Document.class); return results.getMappedResults(); } @GetMapping("/countByMonth") public List<Document> getMovieCountByMonth () { return movieService.getMovieCountByMonth(); }
前端展示 项目搭建 首先,创建一个新的 React 应用,使用 create-react-app 工具来快速创建一个新项目
1 2 npx create-react-app my-react-app cd my-react-app
接下来,在项目中安装 ECharts
1 npm install echarts --save
在项目目录中运行以下命令来启动 React 应用
接下来就是需要自己修改并封装 Echarts 组件进行可视化展示,以下是我的项目结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ├── public ├── src │ ├── component │ │ ├── MonthlyMovieBarChart.css │ │ ├── MonthlyMovieBarChart.js │ │ ├── MovieChart.css │ │ ├── MovieChart.js │ │ ├── MovieStatistics.css │ │ ├── MovieStatistics.js │ │ ├── YearSlider.css │ │ └── YearSlider.js │ ├── App.css │ ├── App.js │ ├── index.css │ ├── index.js │ └── reportWebVitals.js
编写组件 首先展示电影评分的平均分、中位数、最高分、最低分,在 component 文件夹中创建 MovieStatistics.js 组件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const MovieStatistics = ({ average, median, highest, lowest }) => { return ( <div className="movie-statistics-container"> <div className="statistic"> <h2>Average Rating</h2> <p className="rating">{average}</p> </div> <div className="statistic"> <h2>Median Rating</h2> <p className="rating">{median}</p> </div> <div className="statistic"> <h2>Highest Rating</h2> <p className="rating">{highest}</p> </div> <div className="statistic"> <h2>Lowest Rating</h2> <p className="rating">{lowest}</p> </div> </div> ); }; export default MovieStatistics;
创建对应的 css 文件修改样式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 .movie-statistics-container { display : flex; justify-content : space-around; align-items : center; background-color : #f5f5f5 ; padding : 20px ; border-radius : 10px ; } .statistic { text-align : center; } .rating { font-size : 24px ; font-weight : bold; color : #333 ; }
在 App.js 中引用这个组件,同时编写 fetchData 方法进行异步请求,给 stats 设置状态,通过 useEffect 钩子函数进行更新,详情请看注释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import React, { useState, useEffect } from 'react'; import MovieStatistics from './component/MovieStatistics'; import './App.css'; // 定义 App 组件 function App() { // 使用 useState 钩子来初始化状态。这里的状态是一个包含电影统计数据的对象。 const [stats, setStats] = useState({ average: null, median: null, highest: null, lowest: null }); // fetchData 是一个异步函数,用于从指定 URL 获取数据。 const fetchData = async (url) => { try { // 发起 fetch 请求到后端API const response = await fetch(`http://localhost:8082/movies${url}`); // 检查响应状态。如果不是“ok”,则抛出错误。 if (!response.ok) { throw new Error(`HTTP error! Status: ${response.status}`); } // 解析 JSON 响应并返回 return await response.json(); } catch (error) { // 如果请求失败,打印错误到控制台,并根据错误类型返回相应的值 console.error("Fetching data failed", error); return error.message.includes('404') ? [] : null; } }; // 使用 useEffect 钩子在组件加载后执行异步数据获取操作 useEffect(() => { // 定义一个异步函数 fetchStats 来获取所有统计数据 const fetchStats = async () => { // 分别获取最高评分、最低评分、平均评分和中位数评分的数据 const highest = await fetchData('/maxRating'); const lowest = await fetchData('/minRating'); const average = await fetchData('/averageRating'); const median = await fetchData('/medianRating'); // 更新状态 setStats({ highest, lowest, average, median }); }; // 调用 fetchStats 函数 fetchStats(); }, []); // 渲染组件。这里使用 MovieStatistics 组件来展示统计数据。 return ( <div className='App'> <div> <MovieStatistics average={stats.average} median={stats.median} highest={stats.highest} lowest={stats.lowest} /> </div> </div> ); } export default App;
需要注意的是,React 项目使用的是 localhost:3000 端口,而后端是 8082 端口,这就涉及到一个跨域的问题,需要在后端中进行跨域配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Configuration public class WebConfig implements WebMvcConfigurer { @Bean public WebMvcConfigurer corsConfigurer () { return new WebMvcConfigurer () { @Override public void addCorsMappings (CorsRegistry registry) { registry.addMapping("/movies/**" ).allowedOrigins("http://localhost:3000" ); } }; } }
前端成功获取数据,展示页面如下。
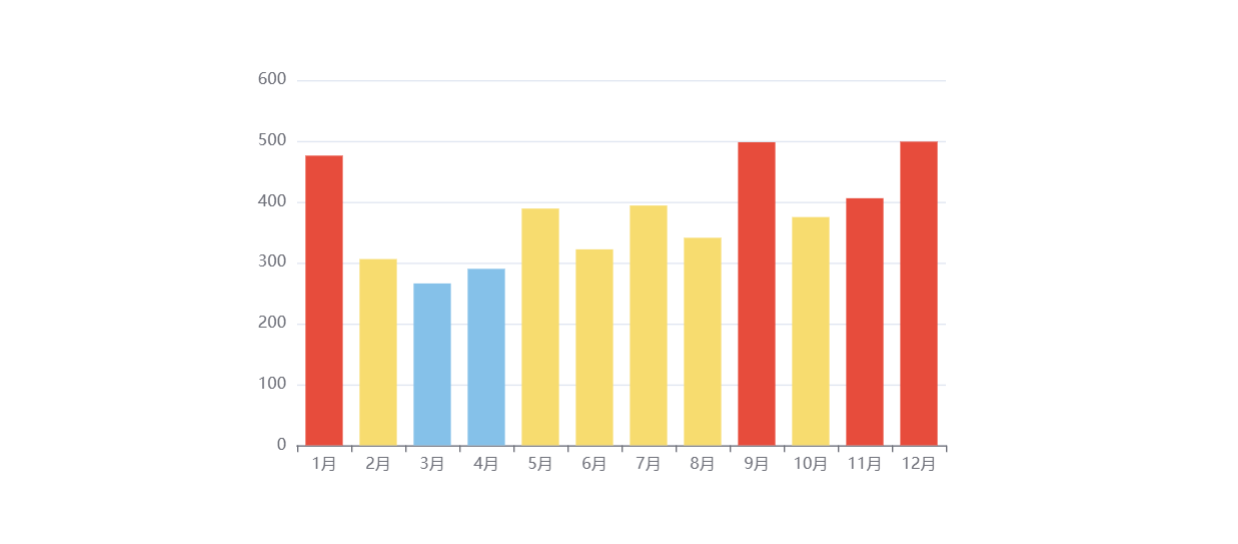
接着处理电影上映数量与月份的关系,根据后端设计的数据格式,我想用柱状图来展现数据,创建 MonthlyMovieBarChart.js 组件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import React, { useEffect, useRef } from 'react'; import * as echarts from 'echarts'; import './MonthlyMovieBarChart.css'; const MonthlyMovieBarChart = () => { // 使用 useRef 钩子创建一个引用,用于定位图表容器的 DOM 元素 const chartRef = useRef(null); // 使用 useEffect 钩子处理组件的挂载和更新逻辑 useEffect(() => { // 初始设置 ECharts 实例 const chartInstance = echarts.init(chartRef.current); // 定义图表数据,这里的数据是硬编码的 const movieData = [ // 每个月份的电影数量数据 { _id: "01", movieCount: 476 }, { _id: "02", movieCount: 306 }, { _id: "03", movieCount: 266 }, { _id: "04", movieCount: 290 }, { _id: "05", movieCount: 389 }, { _id: "06", movieCount: 322 }, { _id: "07", movieCount: 394 }, { _id: "08", movieCount: 341 }, { _id: "09", movieCount: 498 }, { _id: "10", movieCount: 375 }, { _id: "11", movieCount: 406 }, { _id: "12", movieCount: 499 } ]; // 配置项和数据 const option = { // 配置提示框组件 tooltip: { trigger: 'axis', // 触发类型:坐标轴触发 axisPointer: { type: 'shadow' // 指示器类型:阴影 } }, // 配置 X 轴 xAxis: { type: 'category', // 类目轴 data: ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'] }, // 配置 Y 轴 yAxis: { type: 'value', // 数值轴 max: 600 // Y轴的最大值 }, // 配置系列列表 series: [{ data: movieData.map(item => item.movieCount), // 映射数据 type: 'bar', // 指定图表类型为柱状图 itemStyle: { // 配置每个柱子的样式 color: (params) => { // 根据数值设置不同的颜色 if (params.value < 300) { return '#85C1E9'; // 淡蓝色 } else if (params.value >= 300 && params.value < 400) { return '#F7DC6F'; // 淡黄色 } else { return '#E74C3C'; // 淡红色 } } } }] }; // 将配置项设置到 ECharts 实例上 chartInstance.setOption(option); // 组件卸载时,清理 ECharts 实例 return () => { chartInstance.dispose(); }; }, []); // 渲染图表容器 return <div ref={chartRef} className="MonthlyMovieBarChart" style={{ width: '600px', height: '400px' }}></div>; }; export default MonthlyMovieBarChart;
在 App.js 中引用这个组件,React 框架支持热更新,刷新页面即可看到新增的柱状图。
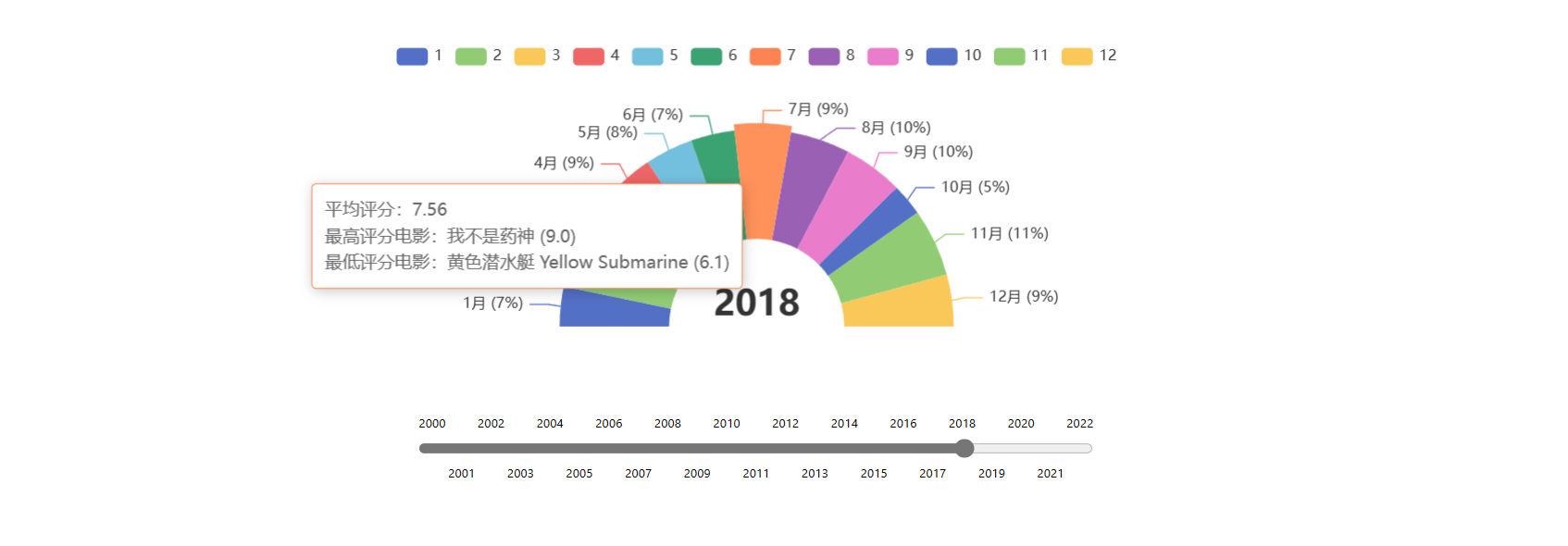
扩展图表 在完成这两个任务之后,我想更形象地展示这些电影数据(实际上是逛 Echarts 示例时感觉这个环状饼图很好看),可以展示每一年中不同月份上映电影的数量数量,同时统计每月电影的平均分并展示最高 / 最低评分的电影。
首先设计选择年份的 YearSlider 组件,思路是魔改源生的 input 组件,添加滑块,同时使用钩子函数来动态管理年份,实现组件之间的通信。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import React, { useState } from 'react'; import './YearSlider.css'; // 引入样式文件 // YearSlider 组件,用于创建一个年份滑块 const YearSlider = ({ minYear, maxYear, onYearChange }) => { // 使用 useState 钩子来管理滑块的当前值 const [year, setYear] = useState(minYear); // 处理滑块变更的事件 const handleSliderChange = (event) => { // 获取选中的年份 const selectedYear = event.target.value; // 更新组件状态中的年份 setYear(selectedYear); // 调用父组件传递的 onYearChange 函数,通知外部年份已更改 onYearChange(selectedYear); }; // 生成年份标签,用于在滑块下方显示 const yearLabels = []; for (let y = minYear; y <= maxYear; y++) { yearLabels.push( // 根据年份是奇数还是偶数,应用不同的 CSS 类 <span key={y} className={`year-label ${(y % 2 === 0) ? 'even' : 'odd'}`}> {y} // 显示年份 </span> ); } // 渲染滑块和年份标签 return ( <div className="year-slider-container"> <input type="range" // 输入类型为范围滑块 title="Select Year" // 滑块的标题 min={minYear} // 滑块的最小值 max={maxYear} // 滑块的最大值 value={year} // 滑块当前选中的值 onChange={handleSliderChange} // 滑块值变化时的处理函数 className="year-slider" // 应用的 CSS 类 /> <div className="year-labels"> {yearLabels} // 渲染年份标签 </div> </div> ); }; export default YearSlider;
然后根据 Echarts 示例的代码编写 MovieChart 组件,这个组件需要展示一年中电影的相关数据,需要略微处理一下后端返回的数据,以防止有些月份没有上映的电影导致图表出现错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import React, { useEffect, useRef } from 'react'; import * as echarts from 'echarts'; import './MovieChart.css'; // MovieChart 组件接收年份和数据作为属性 const MovieChart = ({ year, data }) => { // 使用 useRef 钩子创建一个引用,指向图表容器的 DOM 节点 const chartRef = useRef(null); // 使用 useEffect 钩子在组件更新时重新渲染图表 useEffect(() => { // 如果数据不存在或者给定年份的数据不存在,则不渲染图表 if (!data || !data[year]) { return; } // 初始化 ECharts 实例 const chartInstance = echarts.init(chartRef.current); // 获取给定年份的数据 const chartData = data[year]; // 配置 ECharts 图表的选项 const option = { // 配置提示框组件,用于格式化鼠标悬浮到图表项的信息 tooltip: { trigger: 'item', formatter: (params) => { // ...提示框的格式化函数... } }, // 配置图例组件的位置和选择模式 legend: { // ...图例配置... }, // 配置系列列表 series: [ { // ...系列配置... } ], // 配置标题组件,显示选定的年份 title: { // ...标题配置... }, }; // 应用配置选项到 ECharts 实例 chartInstance.setOption(option); // 组件卸载时,清理 ECharts 实例 return () => { chartInstance.dispose(); }; }, [year, data]); // 依赖项数组,当 year 或 data 变化时,useEffect 会重新执行 // 渲染图表容器,设置固定的宽度和高度 return <div ref={chartRef} className="chart-container" style={{ width: '600px', height: '350px'}}></div>; }; export default MovieChart;
在 App.js 中创建新的状态,使用 setSelectedYear 变量在组件之间传递信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // 添加新的状态,将 selectedYear 初始值设置为 2000 const [selectedYear, setSelectedYear] = useState(2000); const [chartData, setChartData] = useState({}); // 创建 useEffect 钩子来动态更新两个组件的数据 useEffect(() => { fetchData(`/countByMonth/${selectedYear}`).then(data => { setChartData(prevData => ({ ...prevData, [selectedYear]: data })); }); }, [selectedYear]); // 将组件加入页面中 <div className='Chart2'> <MovieChart year={selectedYear} data={chartData} /> <YearSlider minYear={2000} maxYear={2022} onYearChange={setSelectedYear} /> </div>
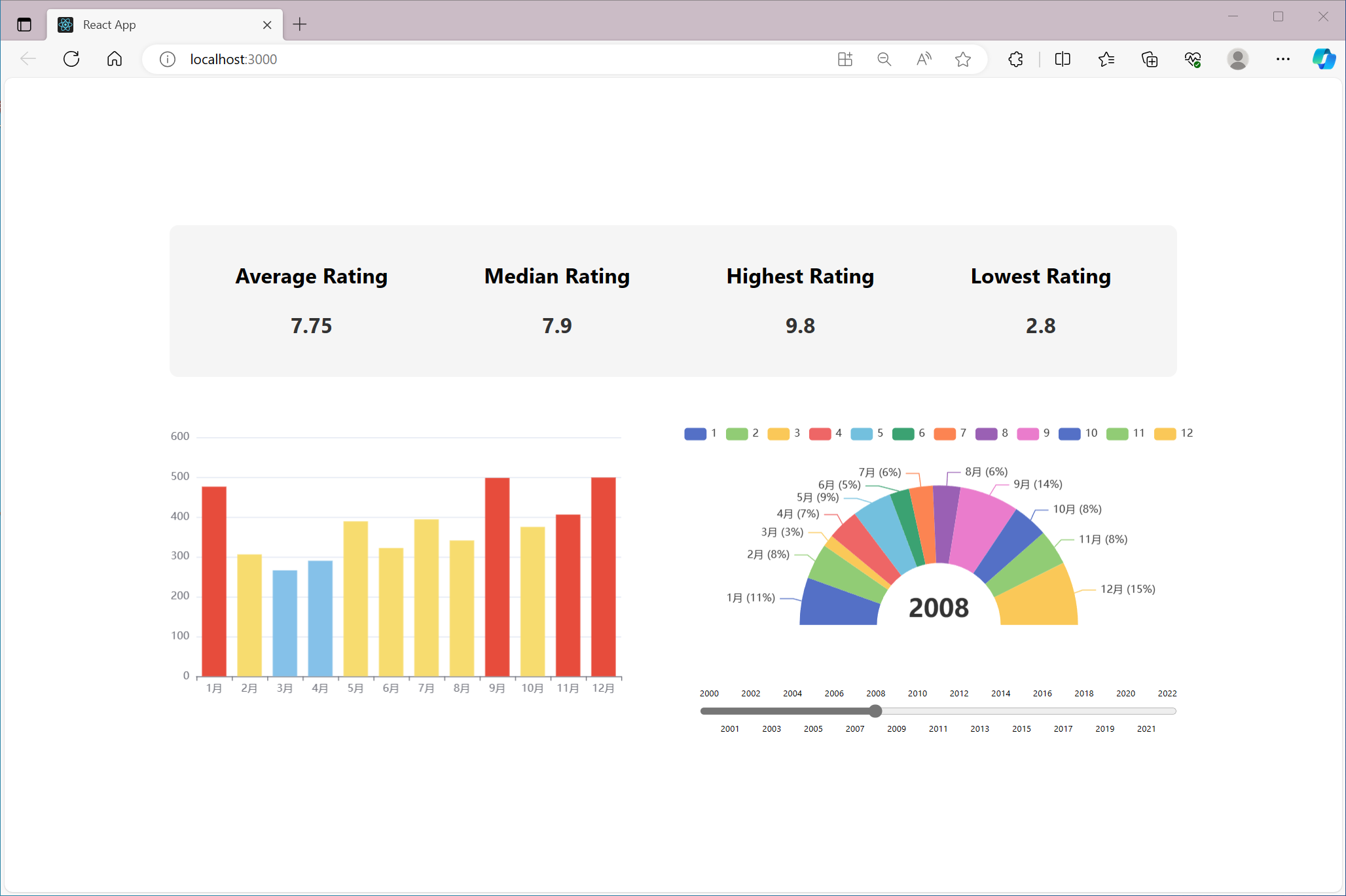
效果如下
感悟总结 通过这次实验,我深刻体会到了数据科学与现代编程实践相结合的力量。在初步接触 MongoDB 和掌握其操作之初,我就被其灵活性和强大的数据处理能力所吸引。实验中,我不仅学会了如何下载和理解数据集,还学习了如何设计合理的数据库、集合和文档结构,这对我理解非关系型数据库的设计理念至关重要。
实验的过程不仅是对技术的操作学习,更是一次思维的锻炼。在将数据导入数据库的过程中,我开始意识到存储数据的科学性对于后续数据检索的重要性。如何设计集合和文档结构,不仅影响数据插入的效率,也直接关系到查询性能和便捷性。这让我认识到,数据库设计不仅是技术问题,更是一门艺术。
使用 MongoDB 的交互式命令查询数据的过程,更是锻炼了我逻辑思维和解决问题的能力。面对具体的查询需求,我学会了如何构造有效的查询语句,这个过程既有挑战也有乐趣。尤其是在执行复杂查询时,我更加深刻地理解了索引和查询优化的重要性。
此外,通过使用高级程序设计语言进行数据统计和展示,我深感程序设计对于数据科学的重要支撑作用。在这一环节中,我不仅需要编写代码实现功能,更要考虑用户界面的友好性和数据呈现的直观性。实验使我认识到,良好的用户体验和直观的数据可视化对于理解和传达数据的含义至关重要。
在实验五中,我学会了使用 React 结合 ECharts 进行数据统计和可视化展示。这一过程中,我不仅锻炼了我的编程技能,更加深了我对于数据美学的认识。一个好的数据可视化能够一目了然地展示复杂数据的关键信息,而优雅的界面设计则能够提升整体的交互体验。
总而言之,这次实验不仅提高了我的数据处理能力,还增强了我对于数据背后故事的理解。我开始意识到数据不仅仅是数字和文本的堆砌,它们代表着信息,承载着知识,反映着现实。未来,我期望能够将这次实验的学习成果应用到更广泛的数据科学项目中,不断提升我的数据洞察力和解决实际问题的能力。最后,附上实验五将三个组件放在一起的完整展示页面。