
数据挖掘实验报告
前言
没什么好说的,就是照葫芦画瓢的无脑实验,会cv就能做。
实验 1.1
实验目的
掌握Hive的配置过程和三种搭建模式
了解Hive的配置原理
实验内容
1、启动Hadoop服务
2、内嵌模式部署
3、本地模式部署
4、远程模式部署
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
hive是架构在Hadoop之上的,所以需要先部署好Hadoop。
Hive的3种安装方式,分别对应不同的应用场景。
1、内嵌模式(元数据保存在内嵌的derby中,允许一个会话链接,尝试多个会话链接时会报错)
2、本地模式(本地安装mysql 替代derby存储元数据)
3、远程模式(远程安装mysql 替代derby存储元数据,并且与Hive不在同一台机器上)
实验步骤
启动Hadoop服务
1、检查MySQL是否安装
1 | mysql -u root -proot |
此时发现报错信息如下:
1 | mysql: [Warning] Using a password on the command line interface can be insecure. |
执行如下命令,即可成功进入 MySQL。
1 | rm /var/run/mysqld/mysqld.sock |
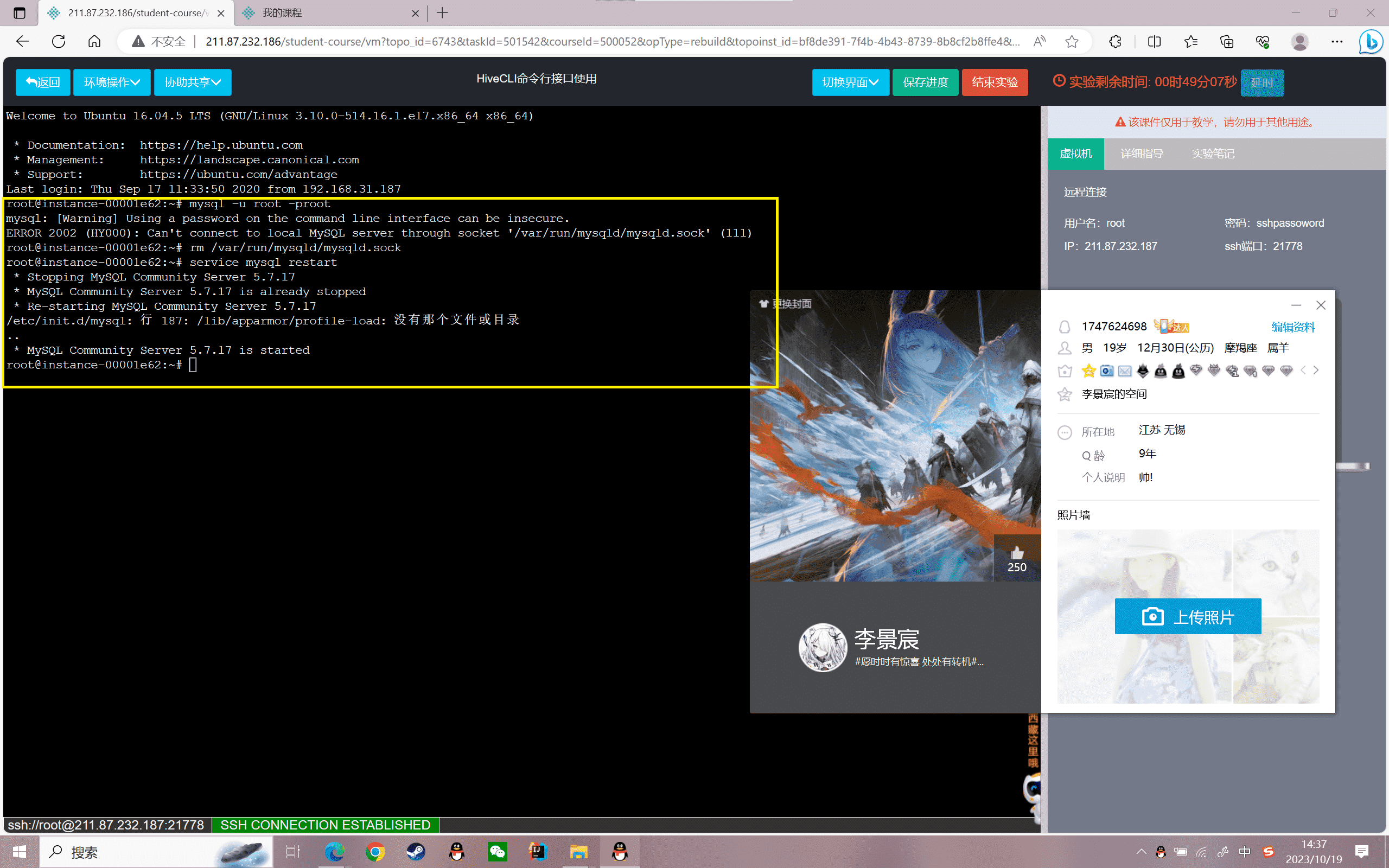
2、检测是否安装Hadoop
注意:需要在配置文件/etc/profile中注释掉Hadoop3的相关环境变量设置,然后执行命令【source /etc/profile】,让配置的profile文件立刻生效。
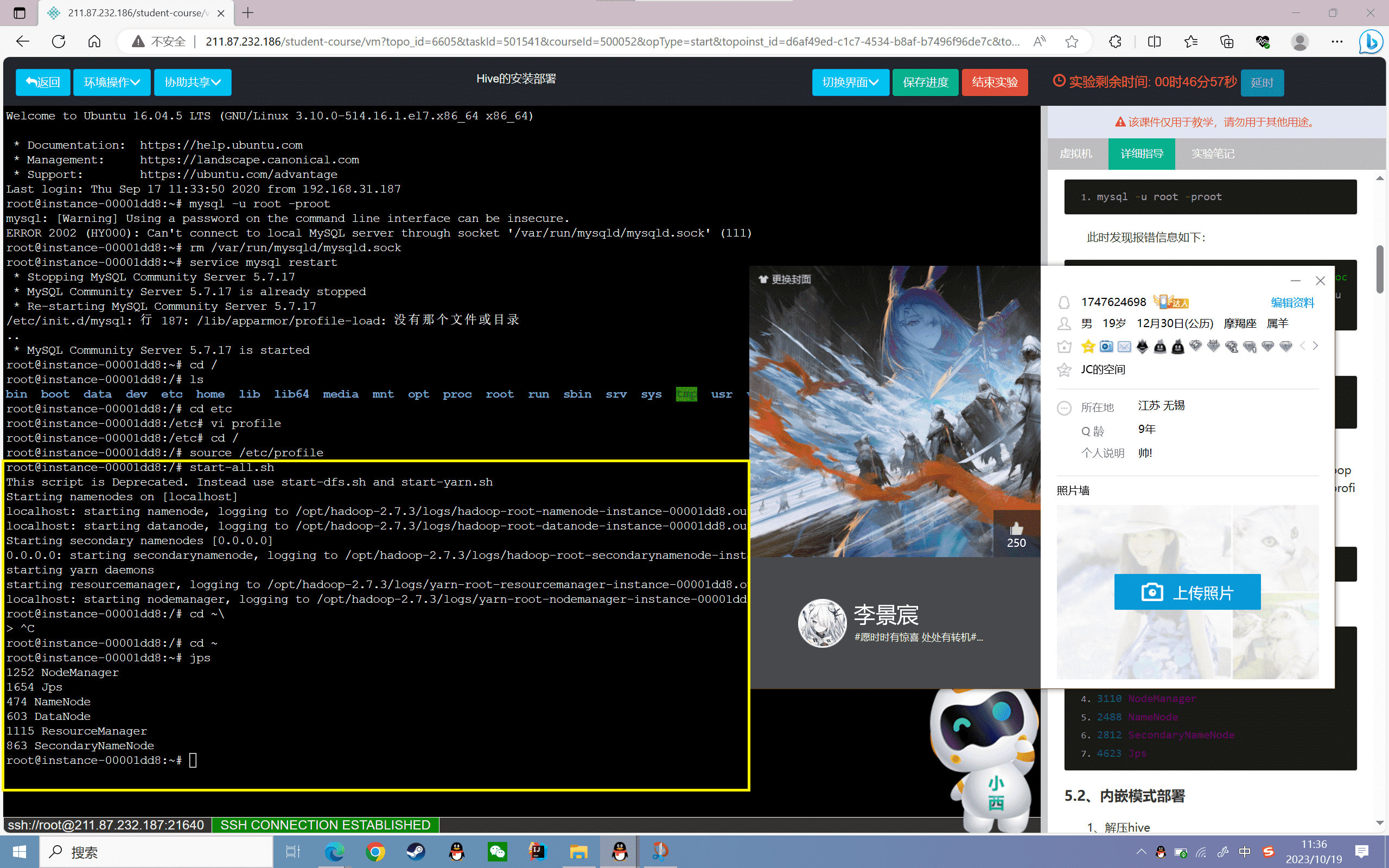
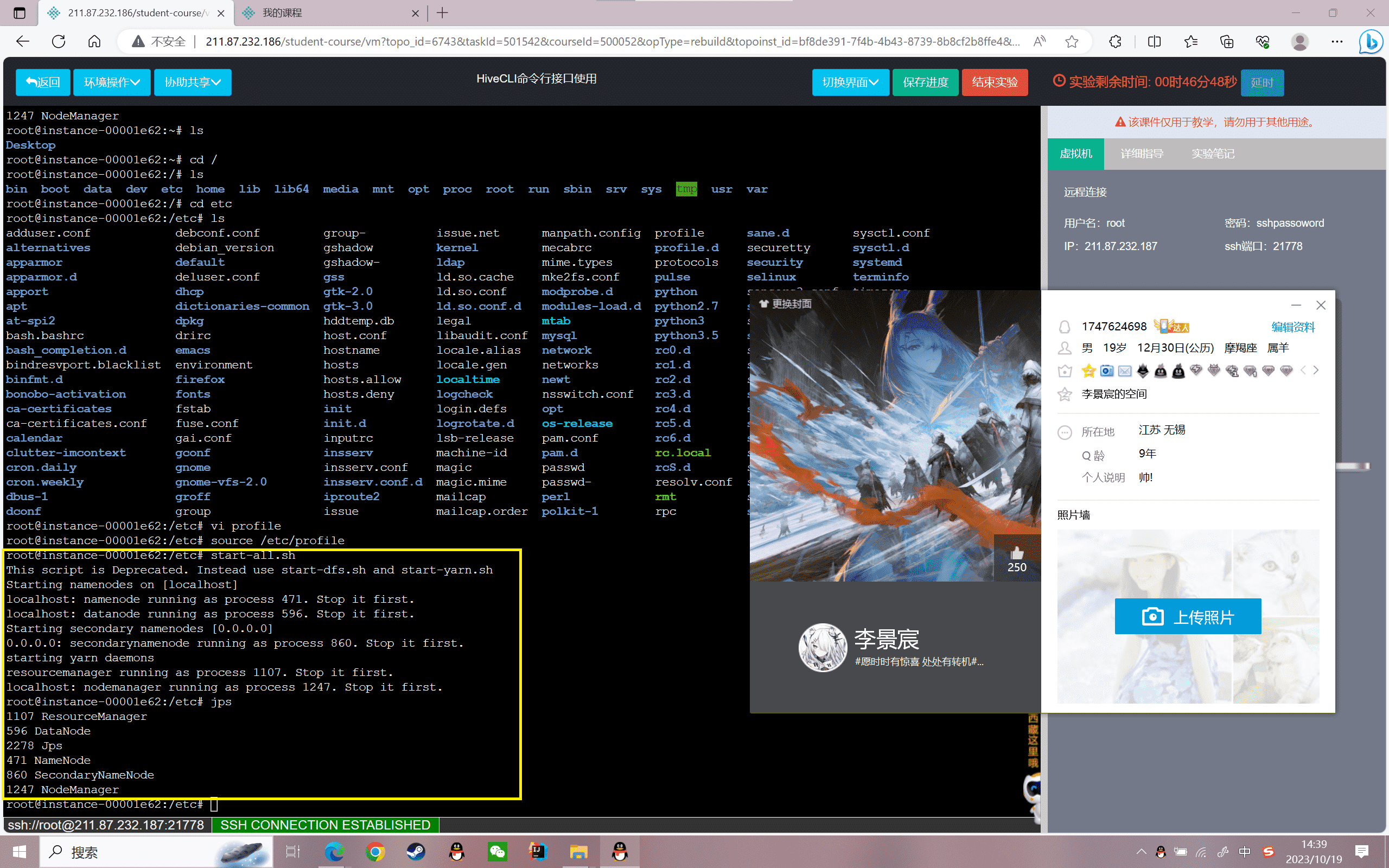
启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~# jps |
内嵌模式部署
1、解压hive
进入软件包所在文件夹中:
1 | cd /data/software |
将Hive解压安装到“/data/bigdata/”目录下:
1 | tar -zxvf apache-hive-2.3.3-bin.tar.gz -C /data/bigdata/ |
查看解压后的Hadoop安装文件:
1 | root@localhost:/data/bigdata# |
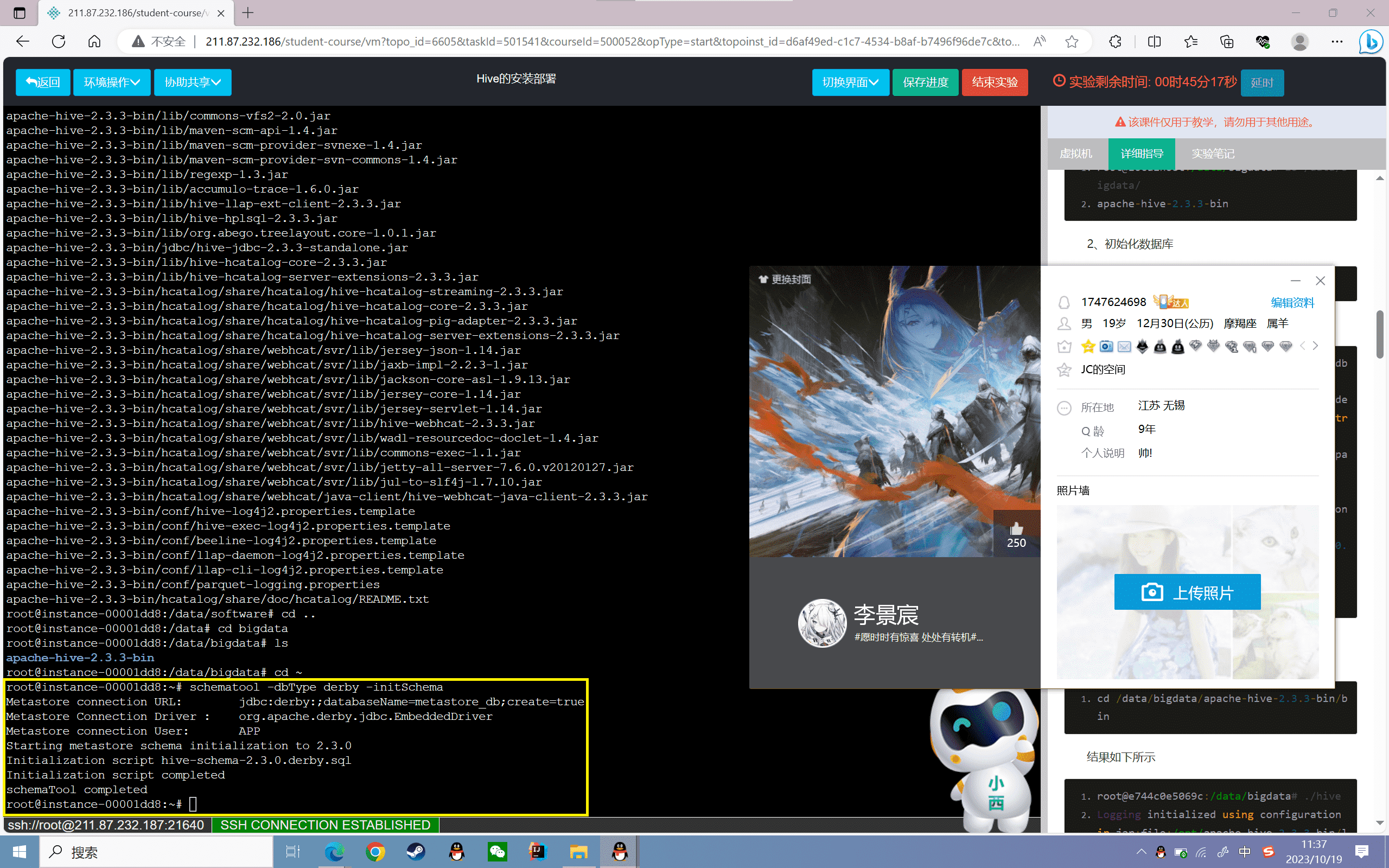
2、初始化数据库
1 | schematool -dbType derby -initSchema |
结果如下所示
1 | root@instance-0000002b:~# schematool -dbType derby -initSchema |
3、Hive测试。
进入Hive客户端,查看是否安装成功:
1 | cd /data/bigdata/apache-hive-2.3.3-bin/bin |
结果如下所示
1 | root@e744c0e5069c:/data/bigdata# ./hive |
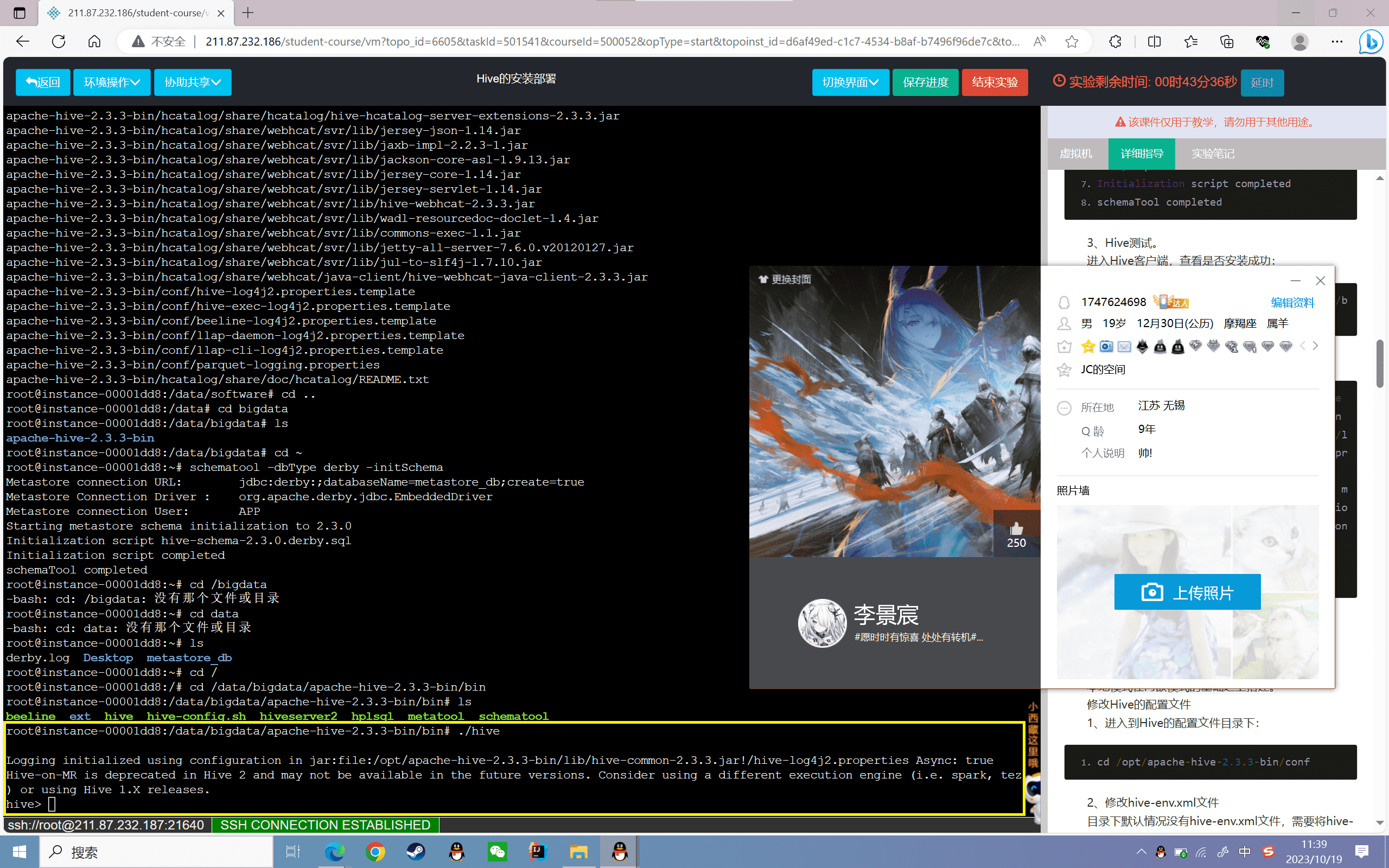
至此,hive内嵌模式安装完成
本地模式部署
本地模式在内嵌模式的基础之上搭建。
修改Hive的配置文件
1、进入到Hive的配置文件目录下:
1 | cd /opt/apache-hive-2.3.3-bin/conf |
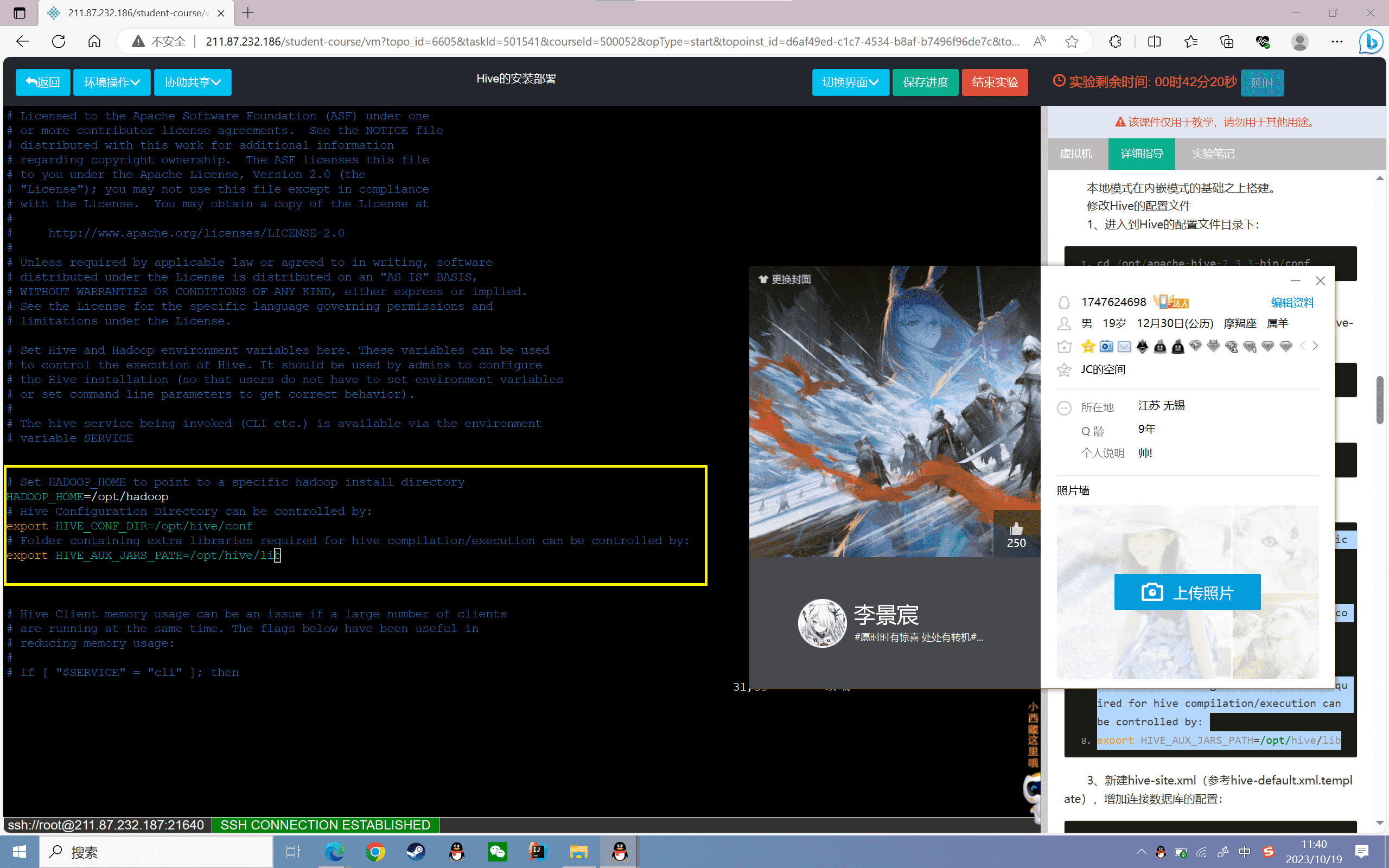
2、修改hive-env.xml文件
目录下默认情况没有hive-env.xml文件,需要将hive-env.xml.template文件复制并重命名为hive-env.xml:
1 | cp hive-env.sh.template hive-env.sh |
进入hive-env.sh文件中:
1 | vi hive-env.sh |
修改该文件内容如下:
1 | Set HADOOP_HOME to point to a specific hadoop install directory |
3、新建hive-site.xml(参考hive-default.xml.template),增加连接数据库的配置:
1 | <configuration> |
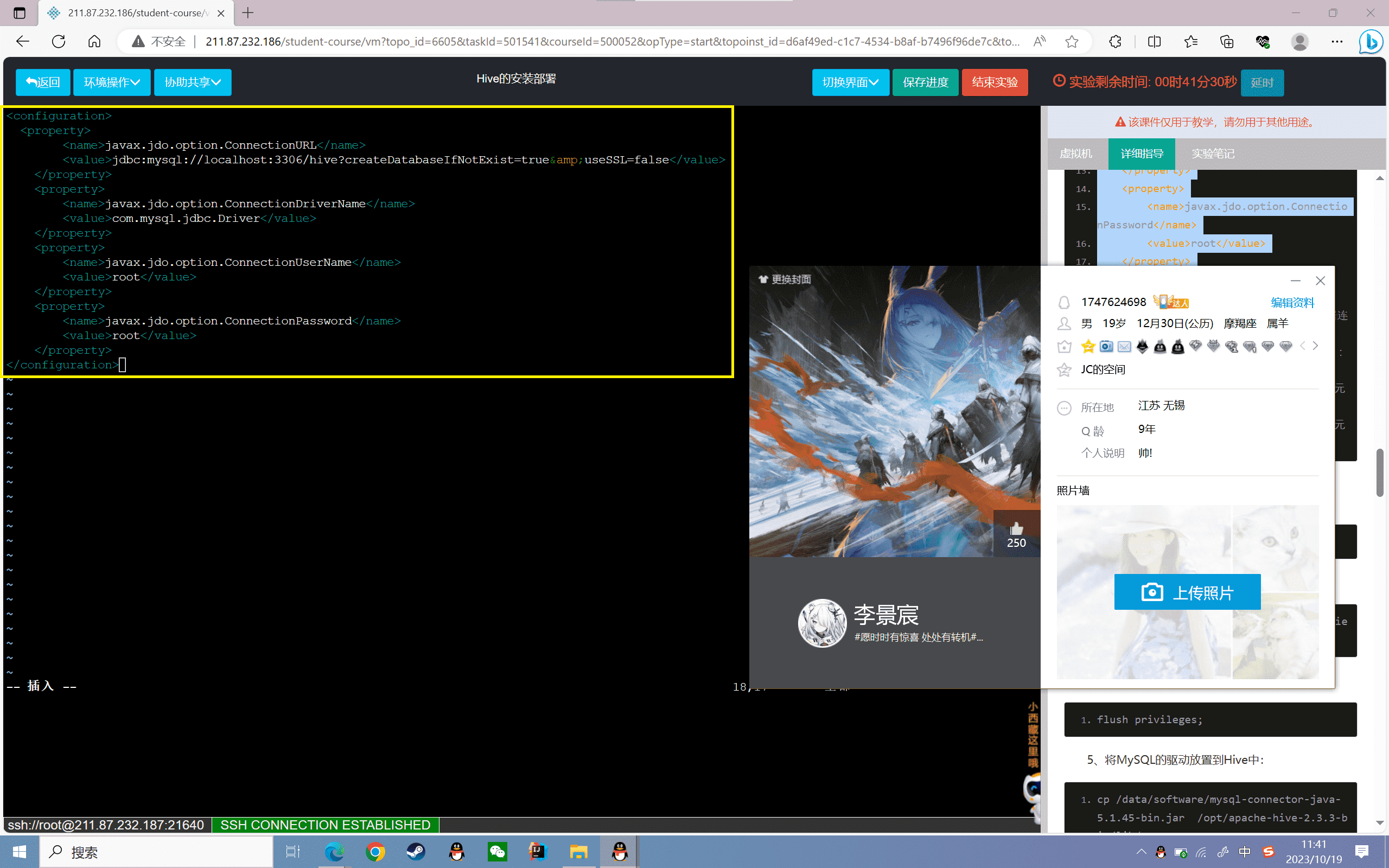
4、元数据的配置
这里以MySQL配置元数据,以root用户登录:
1 | mysql -uroot -proot |
授予权限给用户root:
1 | grant all on *.* to 'root'@'%' identified by'root'; |
刷新权限:
1 | flush privileges; |
5、将MySQL的驱动放置到Hive中:
1 | cp /data/software/mysql-connector-java-5.1.45-bin.jar /opt/apache-hive-2.3.3-bin/lib/ |
6、初始化schema
1 | schematool -initSchema -dbType mysql |
如下图所示:
7、启动测试
进入Hive客户端:
1 | hive |
功能测试,如下图所示:
1 | root@instance-0000001e:/opt/hive/conf# hive |
远程模式部署
在本地的模式基础之上修改,主要是将访问的MySQL地址进行修改即可。
1、修改mysql绑定地址
修改mysql的配置文件,执行命令
1 | vi /etc/mysql/mysql.conf.d/mysqld.cnf |
将该配置文件中的bindaddress参数改为要访问的主机IP(ip以本机实际ip为准),如下图所示:
1 | [mysqld] |
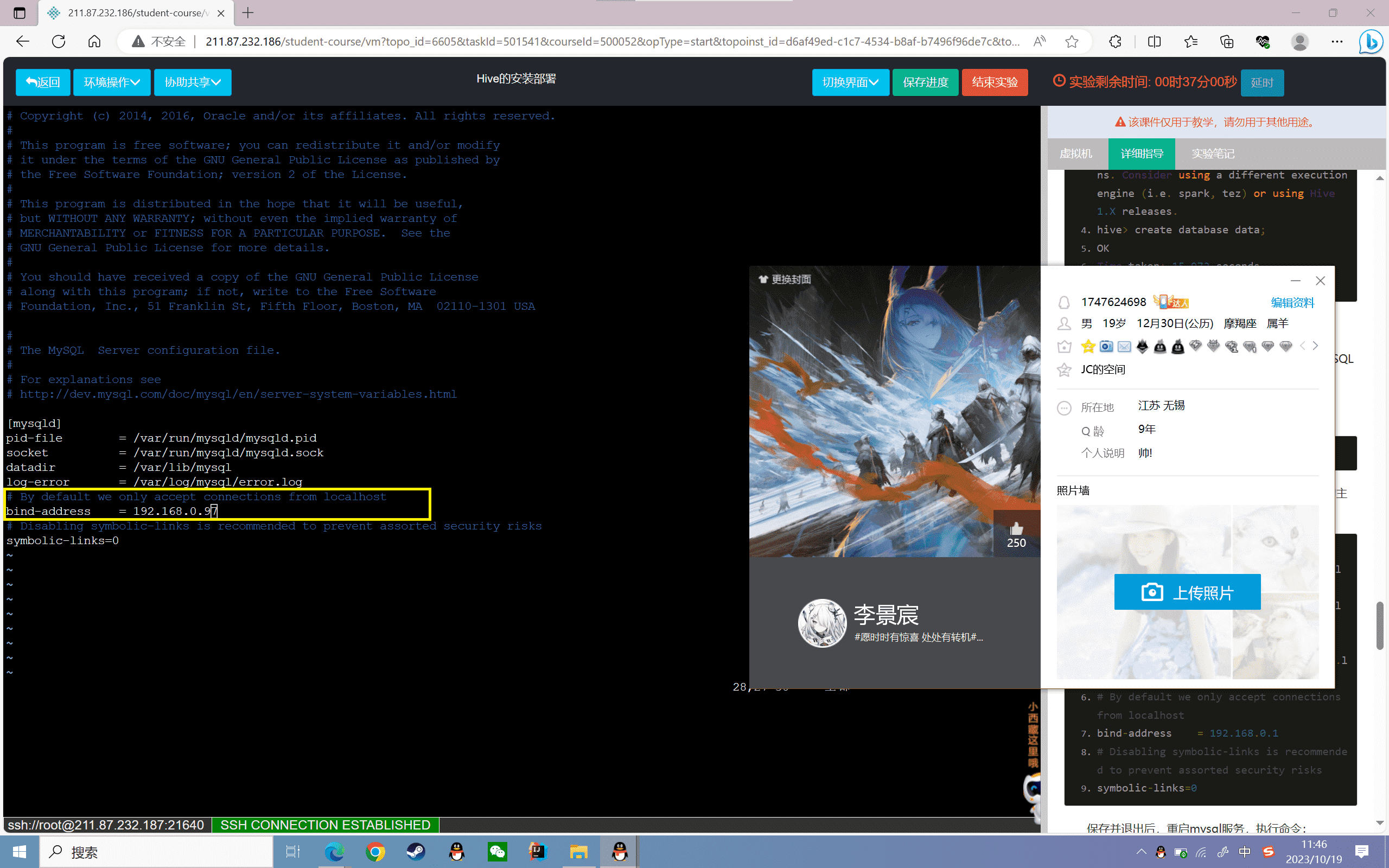
保存并退出后,重启mysql服务,执行命令:
1 | service mysql restart |
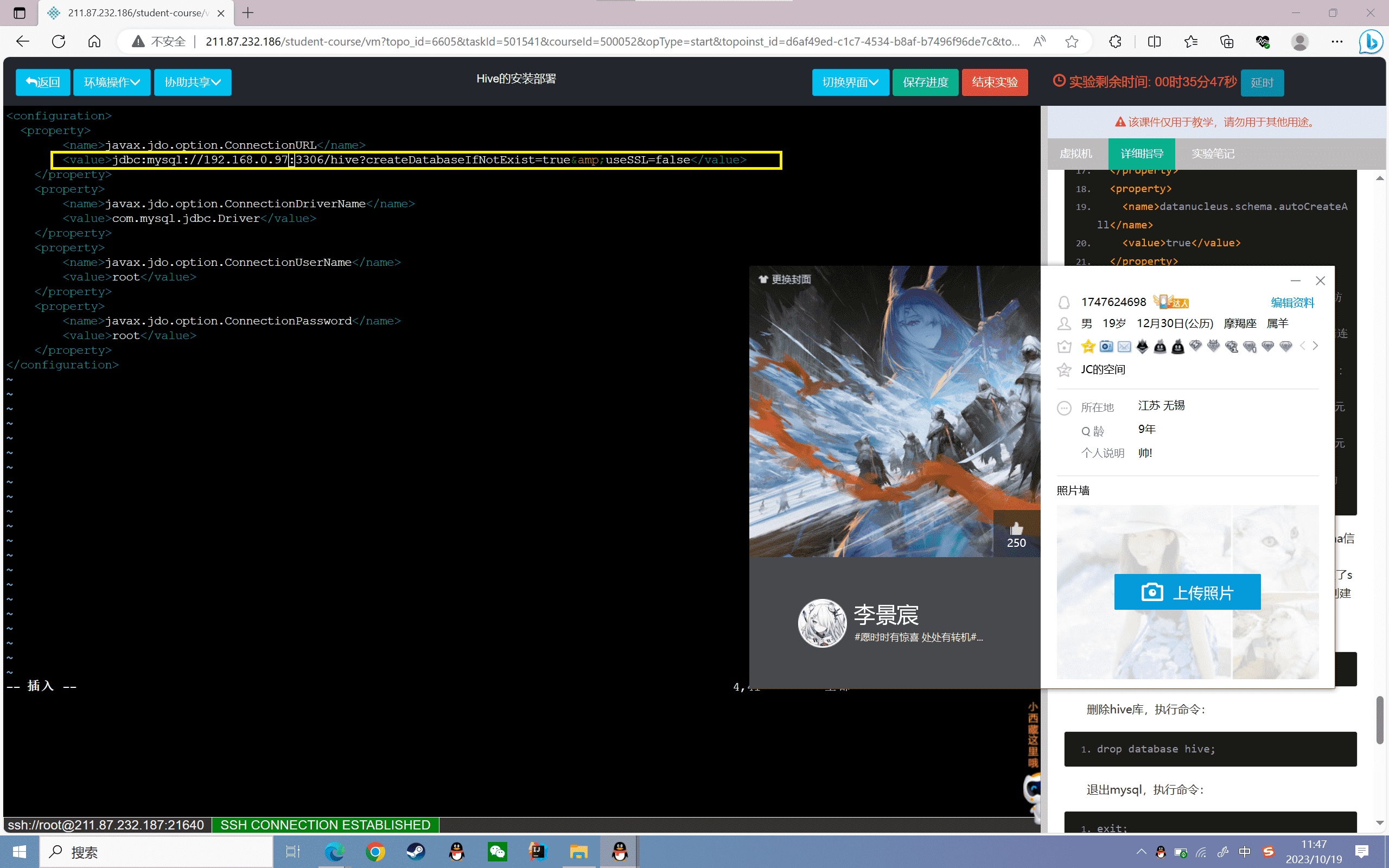
2、修改hive-site.xml,修改连接数据库的配置:
进入到Hive的配置文件目录下:
1 | cd /opt/apache-hive-2.3.3-bin/conf |
修改hive-site.xml文件,修改内容如下:
注意:ip以本机实际ip为准。
1 | <configuration> |
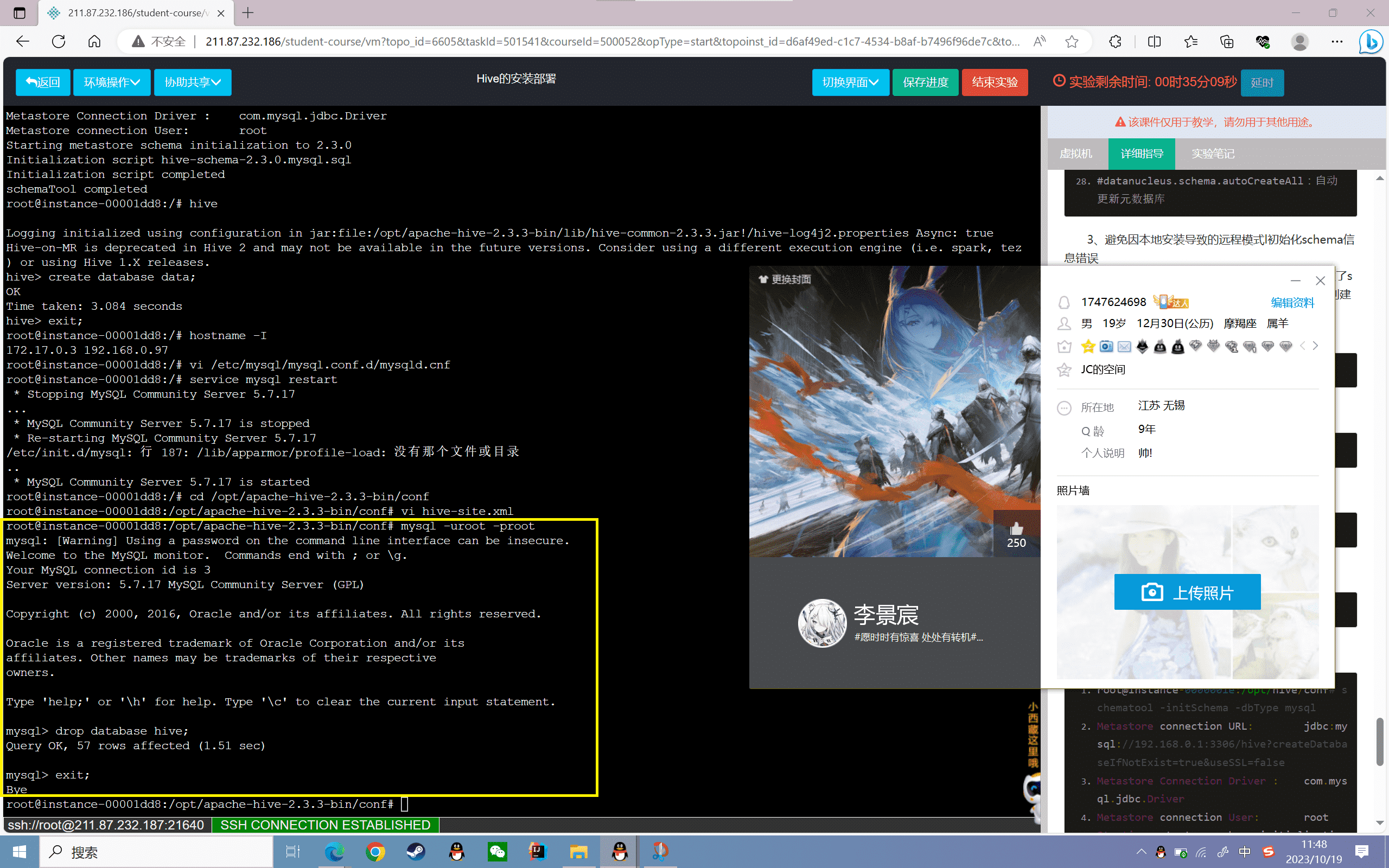
3、避免因本地安装导致的远程模式l初始化schema信息错误
在本地模式安装过程中,对mysql数据库初始化过了schema信息,再次初始化可能导致失败,故先将之前创建的hive库删除
进入mysql数据库,执行命令:
1 | mysql -uroot -proot |
删除hive库,执行命令:
1 | drop database hive; |
退出mysql,执行命令:
1 | exit; |
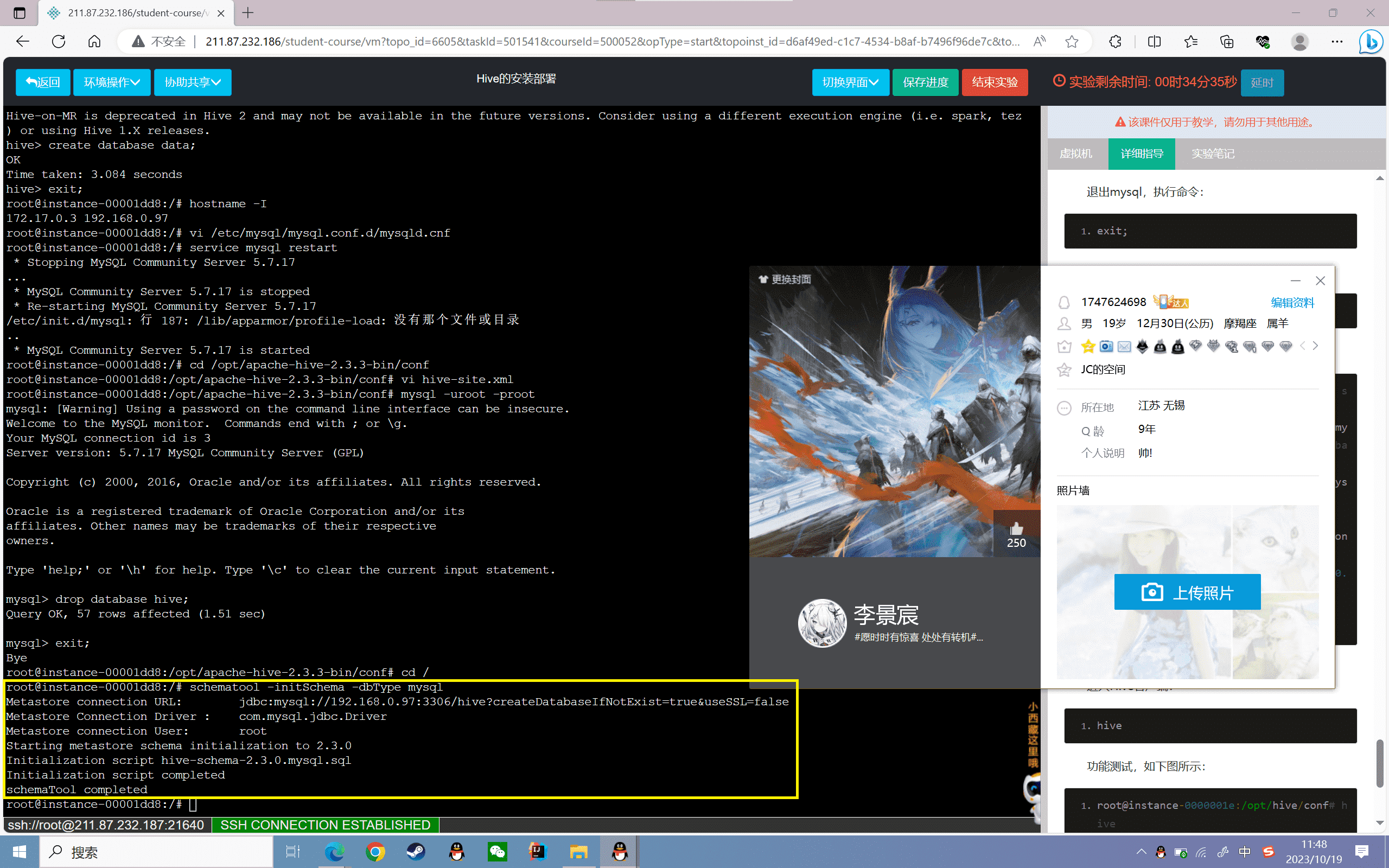
4、初始化schema
1 | schematool -initSchema -dbType mysql |
窗口回显如下,则证明成功
1 | root@instance-0000001e:/opt/hive/conf# schematool -initSchema -dbType mysql |
5、启动测试
进入Hive客户端:
1 | hive |
功能测试,如下图所示:
1 | root@instance-0000001e:/opt/hive/conf# hive |
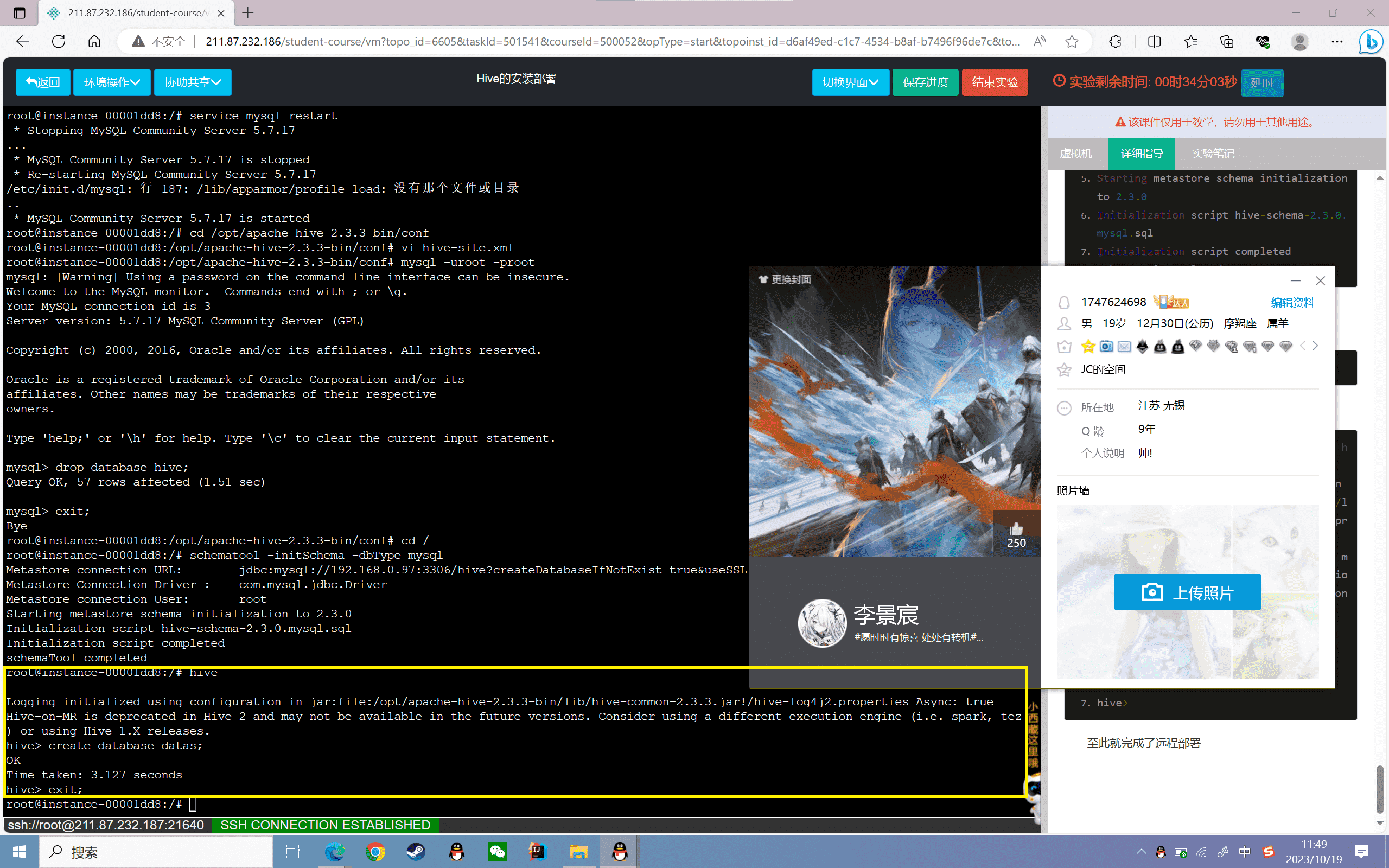
至此就完成了远程部署
实验感悟
关于Hive的安装部署实验,我有以下几点感悟:
Hive建立在Hadoop之上,必须先启动Hadoop相关服务,Hive才能正常运行。这体现了大数据技术的层次性和组件化的特点。
Hive支持内嵌、本地、远程三种模式的安装部署。内嵌模式可以单机试用,但只允许一个会话,不适合生产环境。本地模式将元数据存储在本地MySQL,支持多会话操作,可以用于开发环境。远程模式将元数据存储在远程MySQL,支持多用户分布式操作,适合生产环境。
三种模式的安装步骤类似,都是配置hive-env.sh、hive-site.xml,初始化元数据库模式,然后启动Hive进行验证。需要根据不同模式修改数据库连接相关配置。掌握这一部署流程,可以快速上手Hive的使用。
在远程模式下,如果本地已初始化过元数据库模式,再次初始化会失败。需要先删除本地的Hive数据库,再在远程MySQL上重新初始化,否则会出现报错。这点需要引起重视。
Hive依赖Hadoop环境,必须配置相关环境变量,让Hive知道Hadoop的安装位置。Hive本身也有一定的目录结构,需要配置hive的安装路径、驱动路径等参数。
整个安装过程中,记录日志,分析报错信息非常重要,这些都对后期的定位维护问题非常有帮助。要养成调试的习惯。
通过这次实验,我对Hive的安装部署有了直观的了解,也加深了对大数据技术范式的理解。对下一步学习Hive的使用打下了坚实的基础。这是一次非常有意义的实践经历。
实验 1.2
实验目的
了解常用的Hive CLI命令使用
掌握hive的交互式Shell命令
实验内容
1、启动Hadoop服务
2、Hive CLI操作
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive CLI:查询处理器,用户通过它可以对hive做查询操作处理。
处理流程:根据MetaStore中的信息,将sql解析成MR任务,在提交给yarn去执行;处理后的结果存放在hdfs上,结果再返回给hive cli,解析好之后返回给用户。

实验步骤
启动Hadoop服务
1、重复实验1的步骤,启动mysql服务
修改profile
启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~#jps |
Hive CLI操作
$HIVE_HOME/bin/hive是一个shell实用程序,可用于以交互或批处理模式运行Hive查询,也可以称为Hive CLI。所有hive操作需要在hive的安装目录下进行
1 | cd /opt/hive/ |
1、帮助命令。假如忘记Hive的使用命令或者想要查询其他命令,可以使用这个命令。
1 | hive -H(hive --help) |
结果如下:
1 | usage: hive |
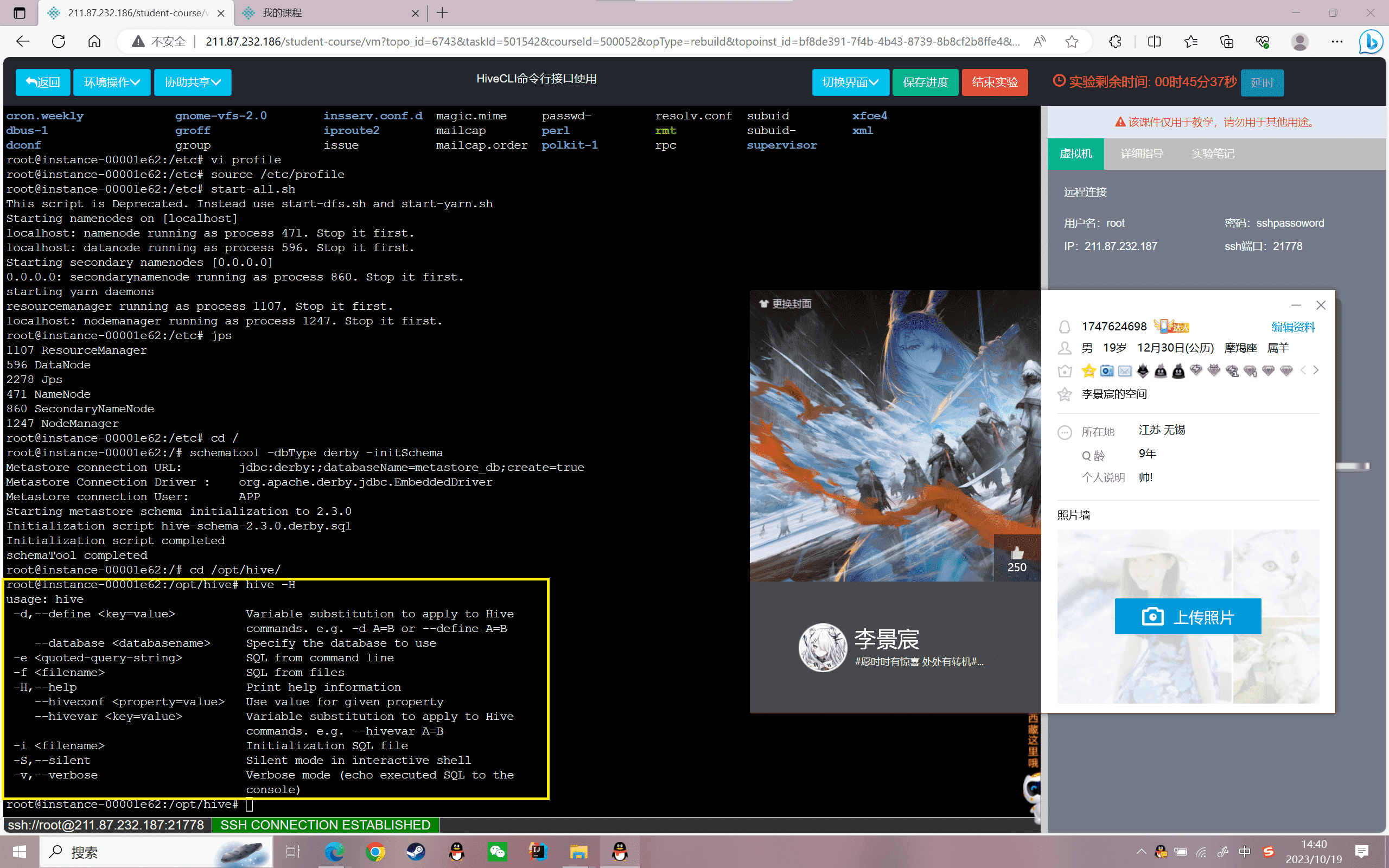
可以看到hive可以使用的命令参数以及用途
2、批处理模式
hive -e ‘< query-string>’执行查询字符串hive -f ‘< filepath>’从文件执行一个或多个SQL查询
使用批处理模式命令查看数据库:
1 | hive -e "show databases" |
结果如下:
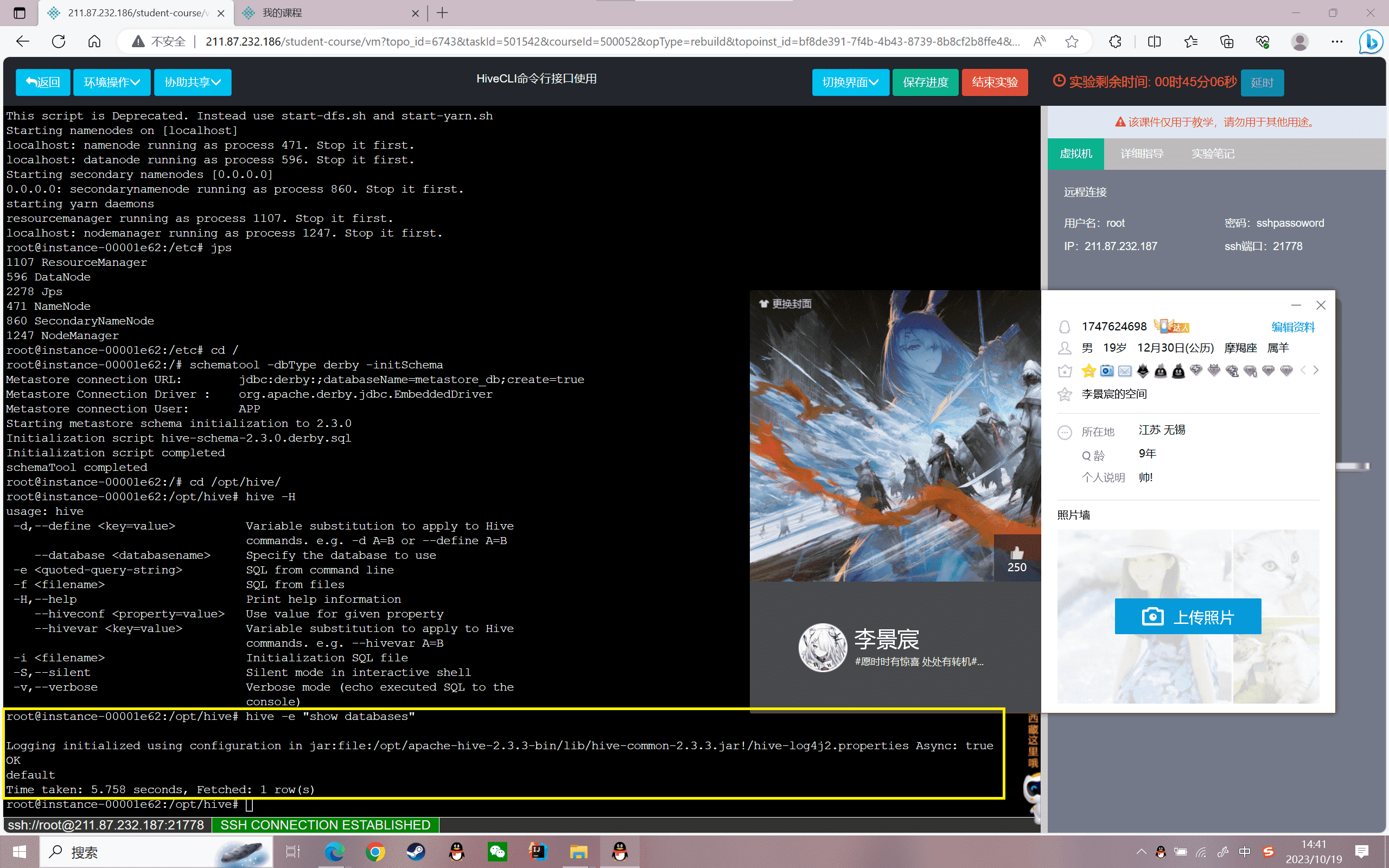
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueOKdefaultTime taken: 6.154 seconds, Fetched: 1 row(s) |
将创建库的SQL追加到“info”文件中
1 | echo "create database info">>info |
使用批处理模式命令创建“info”表
1 | hive -f info |
结果如下:
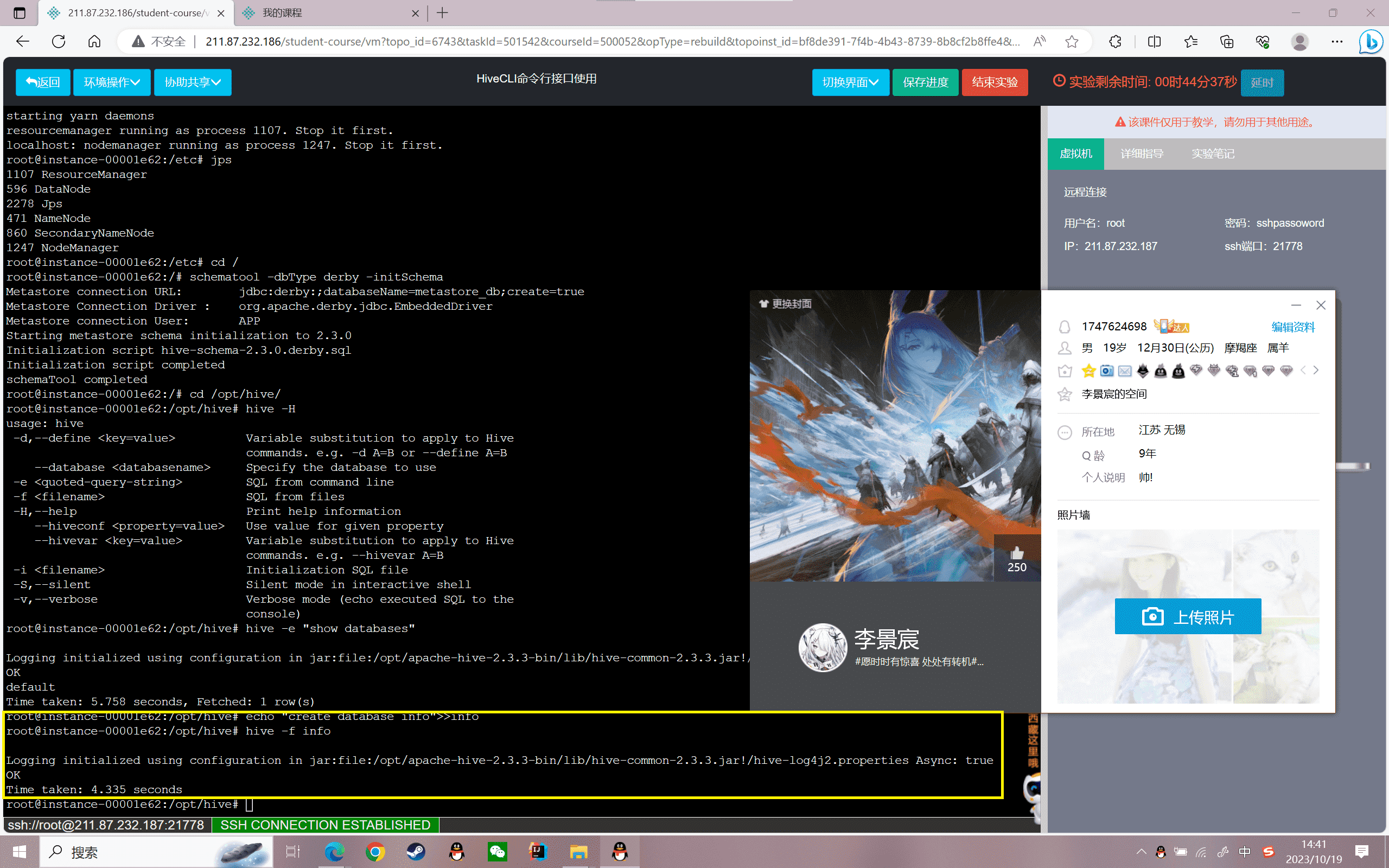
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueOKTime taken: 6.255 seconds |
3、hive的交互式Shell命令
通过进入交互式Shell模式,对hive直接操作,进入hive交互式Shell模式
1 | hive |
结果如下:
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.hive> |
对Hive的配置值的设置,设置reduce的task:
1 | 语法:set <key> = <value>hive> |
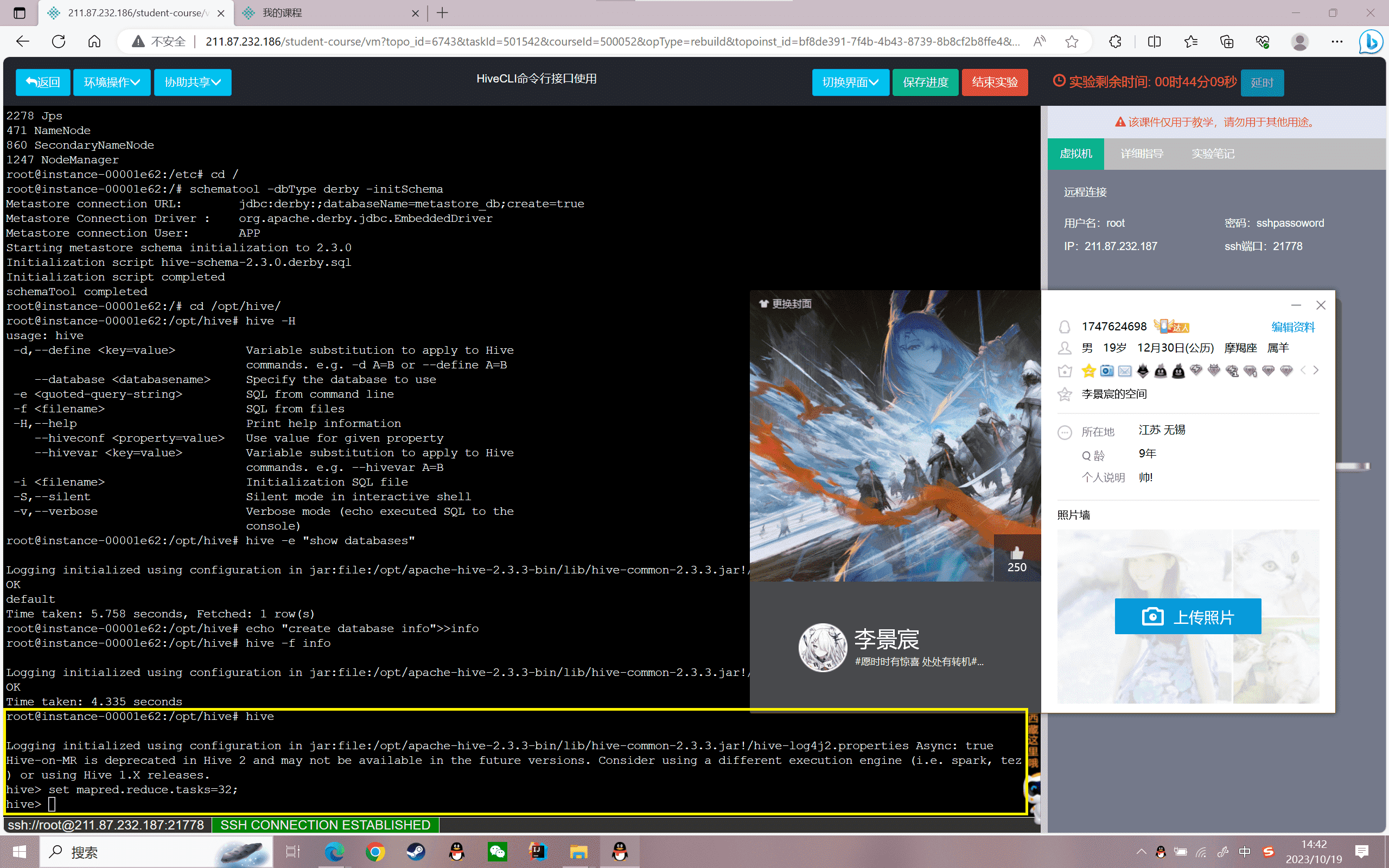
在Hive的Shell中执行Shell命令,查看目录文件:
1 | 语法:!linux命令 |
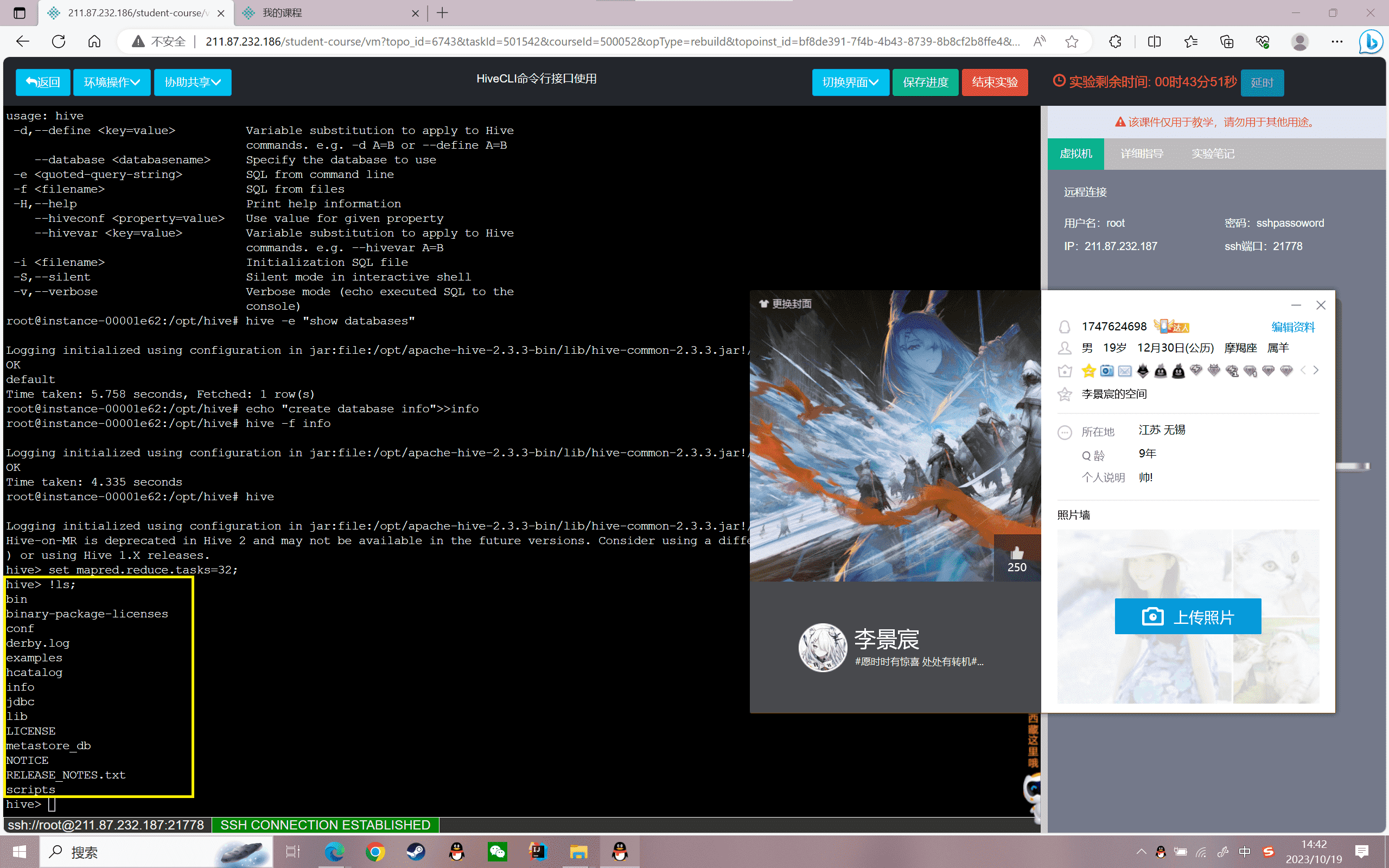
从Hive Shell执行dfs命令,查看目录文件:
1 | 语法:dfs -linux命令 路径 |
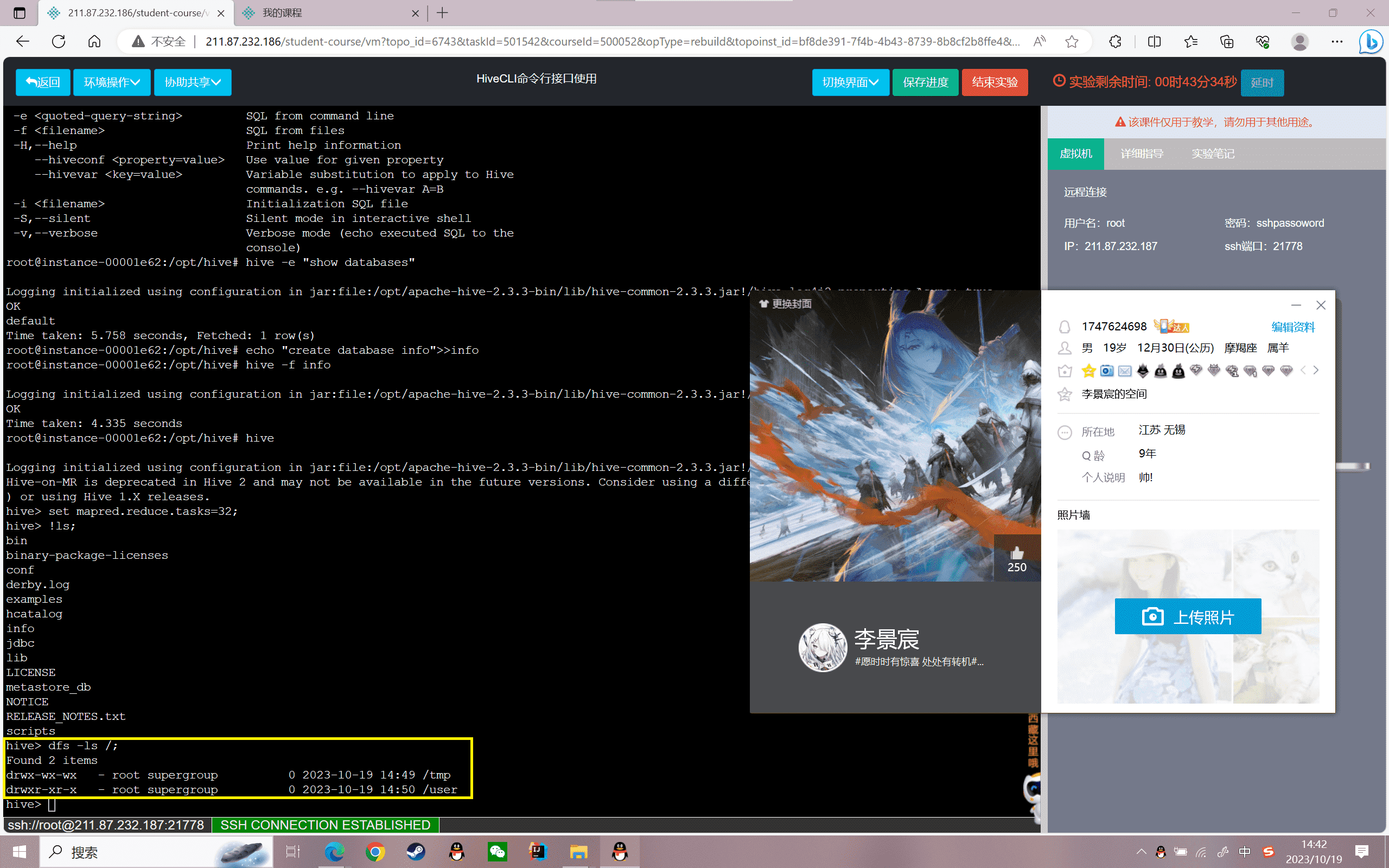
添加文件资源,
1 | echo "print (hello word)">>first.py |
结果如下:
1 | add file first.py; |
关闭Hive交互或批处理模式
1 | exit; |
实验感悟
通过这次Hive CLI命令行接口的实验,让我对Hive CLI的使用有了更深入的了解。Hive CLI为我们提供了交互式和批处理两种模式去执行HiveQL语句,极大地方便了我们对Hive的操作。
我首先学习了如何启动Hadoop服务,确保 Hive CLI能够连接Hadoop集群。然后了解到CLI的两种模式:一种是批处理模式,可以通过-e、-f参数执行SQL语句;一种是交互式Shell模式,通过hive命令进入交互界面。
在交互模式下,我练习了很多CLI的常用命令,像set去设置参数、!执行Linux shell命令、dfs执行HDFS命令等。这让我感受到Hive CLI是一个非常强大的工具。我还学习了添加资源文件、列出资源文件等命令,可以方便我们在Hive查询中使用资源。
通过自己亲身操作,我掌握了Hive CLI的基本用法,知道了如何构建SQL查询、如何查看执行结果。这为我后续使用Hive分析海量数据打下了坚实的基础。我会在今后的学习中,继续深入Hive CLI的高级功能,像参数调优、日志分析等。
总体来说,通过这个实验的学习,我对Hive CLI有了全面系统的了解,既掌握了基础操作,也看到了强大功能。这将大大提高我使用Hive的效率,使我可以更好更快地进行海量数据的提取、转换和分析工作。我会在以后的工作中熟练运用Hive CLI,发挥它的最大价值。
实验 2.1
实验目的
掌握数据库和数据表的定义
了解数据库和数据表定义的常用参数
掌握数据库和数据表的常用操作
实验内容
1、启动Hadoop服务和Hive服务
2、数据库的定义和操作
3、数据表的定义和操作
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的数据管理:hive的表本质就是Hadoop的目录/文件
hive默认表存放路径一般都是在工作目录的hive目录里面,按表名做文件夹分开,如果有分区表的话,分区值是子文件夹,可以直接在其它的M/R job里直接应用这部分数据
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
- db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
- table:在hdfs中表现所属db目录下一个文件夹
- external table:与table类似,不过其数据存放位置可以在任意指定路径
- partition:在hdfs中表现为table目录下的子目录
- bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
实验步骤
启动Hadoop服务和Hive服务
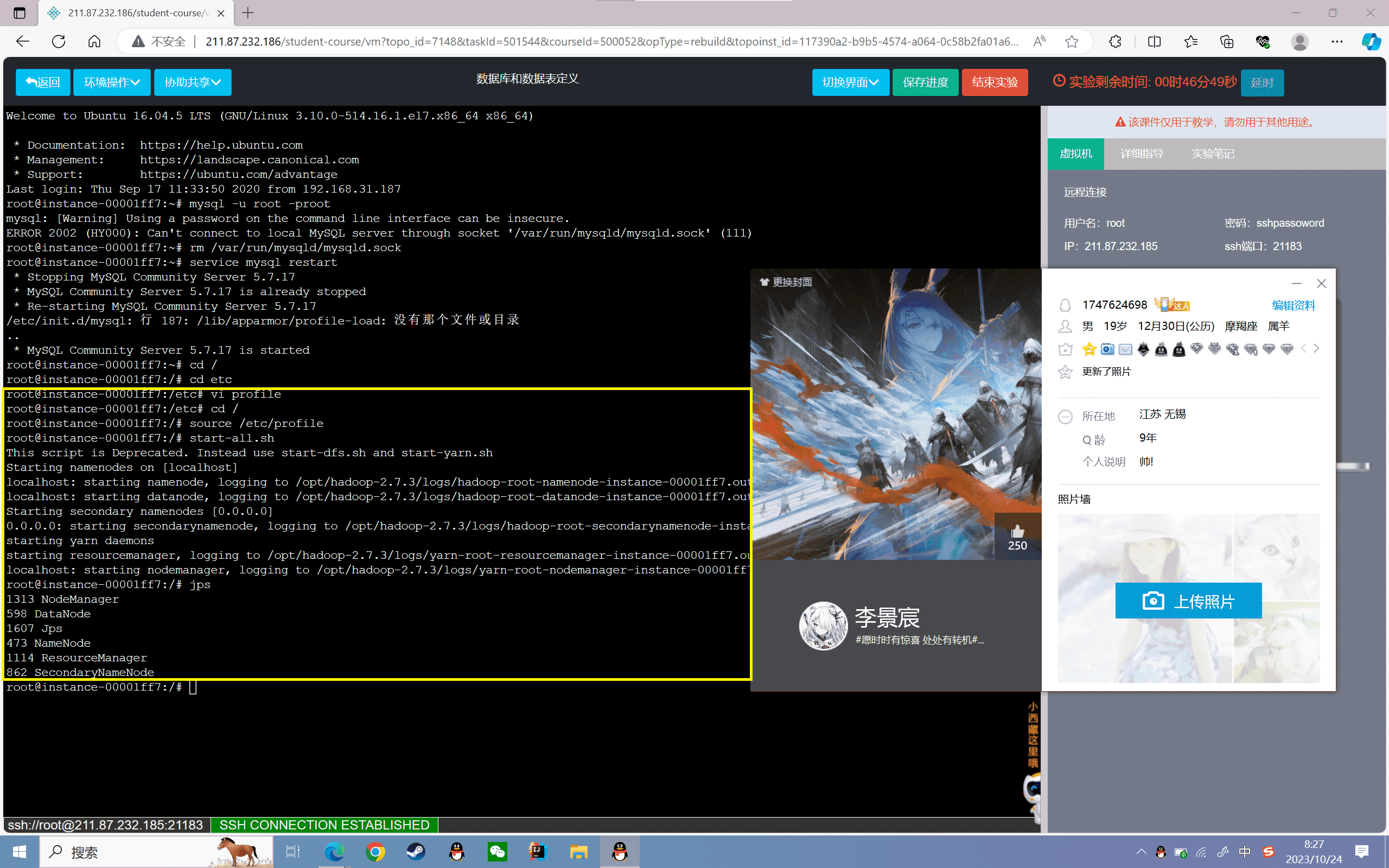
1、启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~# jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.hive> |
数据库的定义和操作
1、查看数据库是否存在
1 | hive> show databases; |
2、创建数据库data
1 | hive> create database if not exists datas comment 'data_comment' location'/data' with dbproperties('day'='20191009'); |
“if not exists”可以省略,data数据库不存在就创建,存在也不会报错
“comment”可以省略,用来给数据库创建别名
“location”可以省略,用来指定数据库的存储位置
“with dbproperties”可以省略,用来添加数据库一些描述性键值对信息
创建数据库可以简写为“create database datas;”
3、模糊匹配查询数据库
1 | hive> show databases like'data*'; |
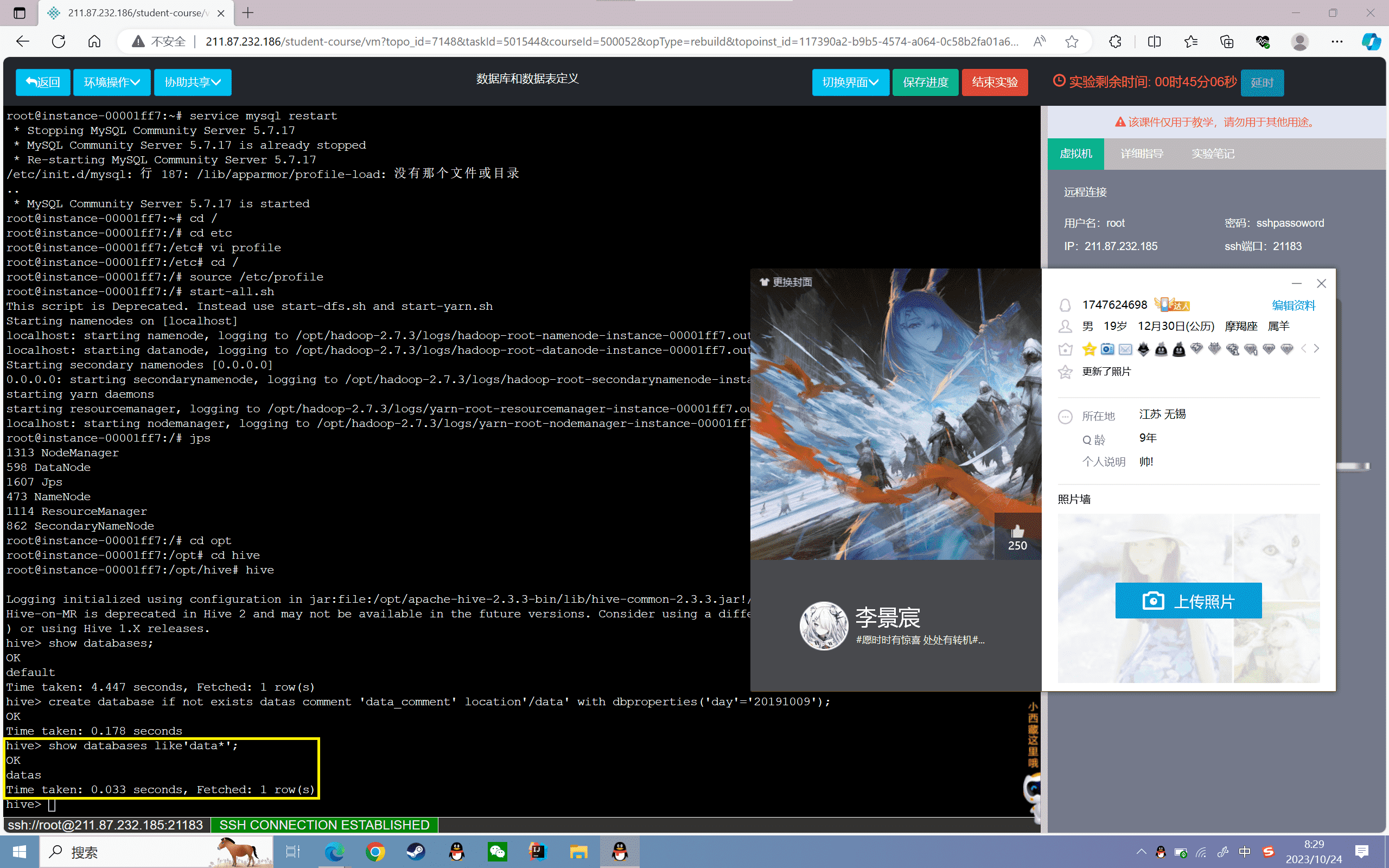
4、查看创建数据库的语句
1 | hive> show create database datas; |
结果如下所示:
1 | OKCREATE DATABASE `datas`COMMENT 'data_comment'LOCATION 'hdfs://localhost:9000/data'WITH DBPROPERTIES ( 'day'='20191009')Time taken: 0.061 seconds, Fetched: 7 row(s) |
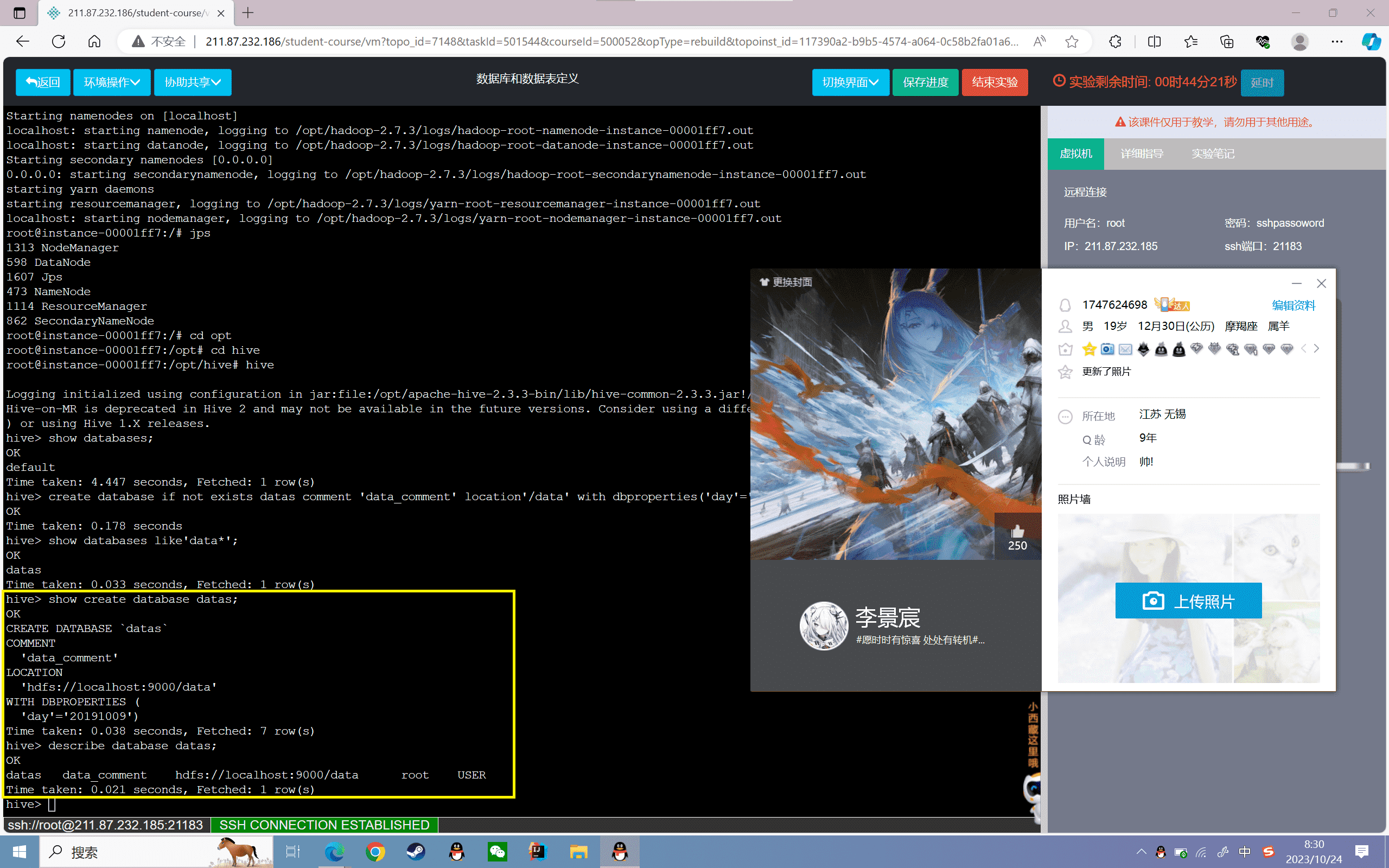
5、查看到数据库的详细信息
1 | hive> describe database datas; |
结果如下所示:
1 | OKdatas data_comment hdfs://simple:9000/data root USER Time taken: 0.062 seconds, Fetched: 1 row(s) |
6、查看数据库的键值对信息
1 | hive> describe database extended datas; |
结果如下所示:
1 | OKdatas data_comment hdfs://simple:9000/data root USER {day=20191009}Time taken: 0.05 seconds, Fetched: 1 row(s) |
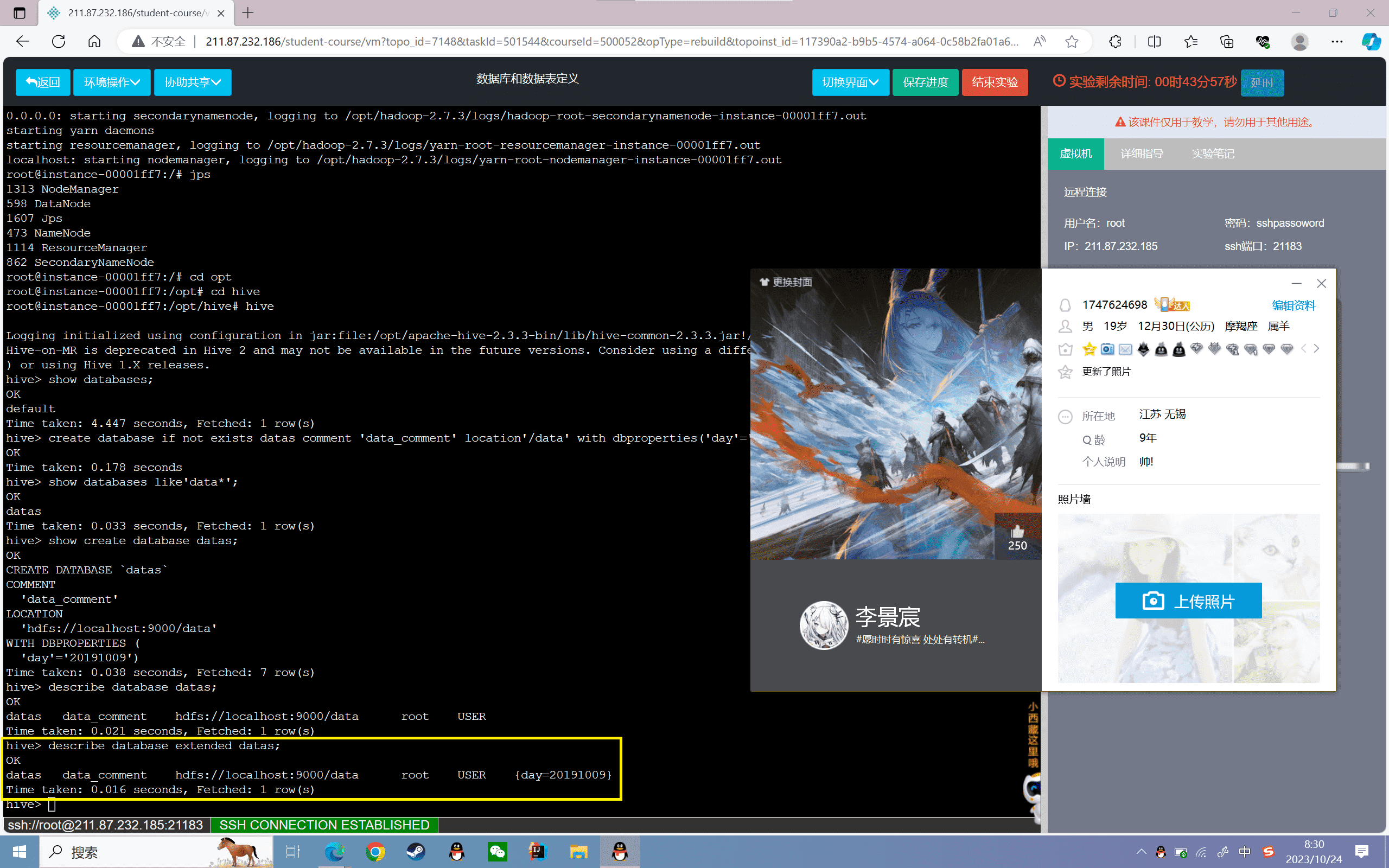
7、要修改数据库的键值对信息:
1 | hive> alter database datas set dbproperties('day'='20231024'); |
结果如下所示:
1 | hive> describe database extended datas;OKdatas data_comment hdfs://localhost:9000/data root USER {day=20191010}Time taken: 0.015 seconds, Fetched: 1 row(s) |
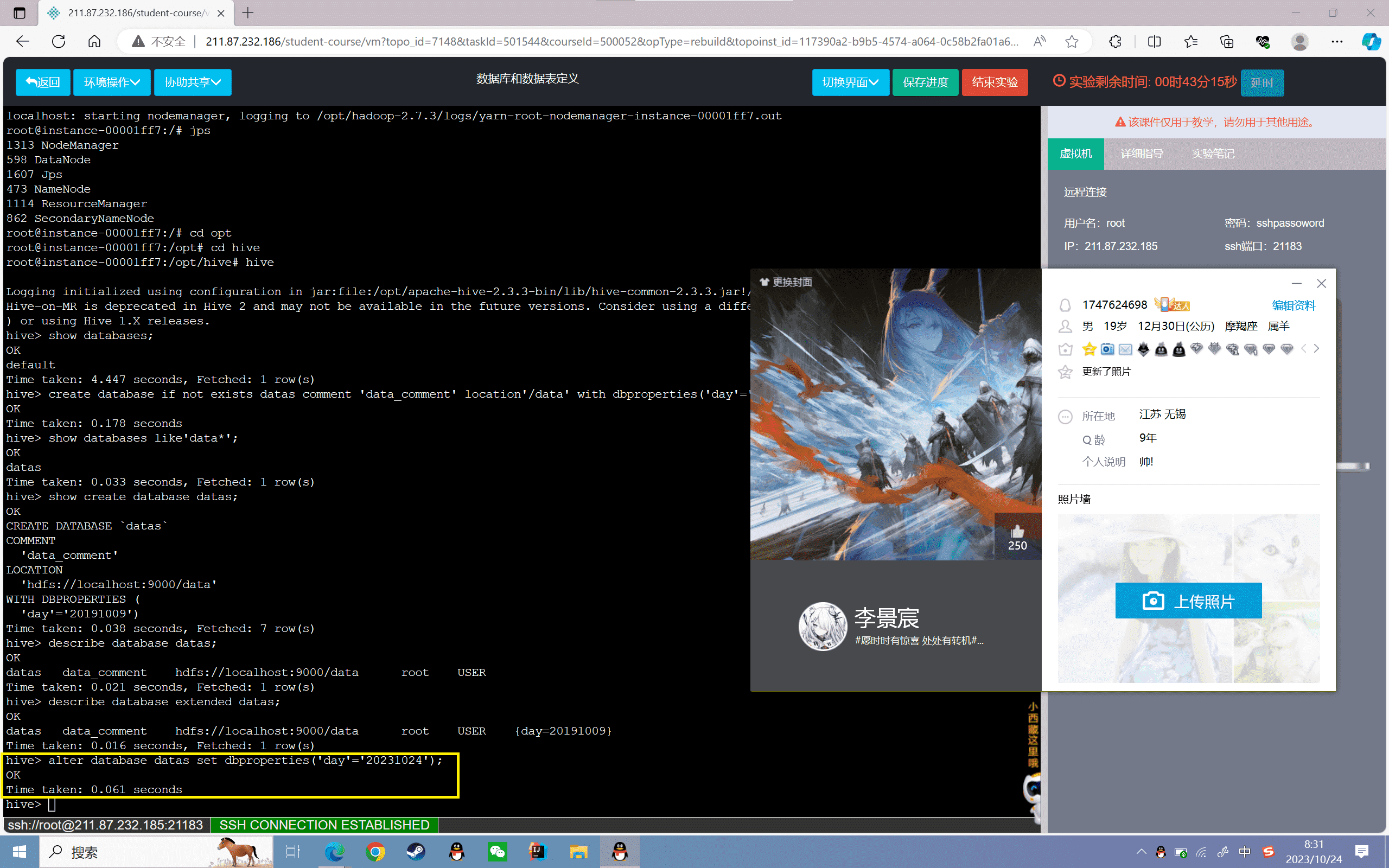
8、使用数据库:
1 | hive> use datas; |
9、删除数据库:
1 | hive> drop database if exists datas; |
默认情况下是不允许直接删除一个有表的数据库的,删除一个有表的数据库有两种办法:sh
- 先把表删干净,再删库。
- 删库时在后面加上cascade,表示级联删除此数据库下的所有表
1 | hive> drop database if exists datas cascade; |
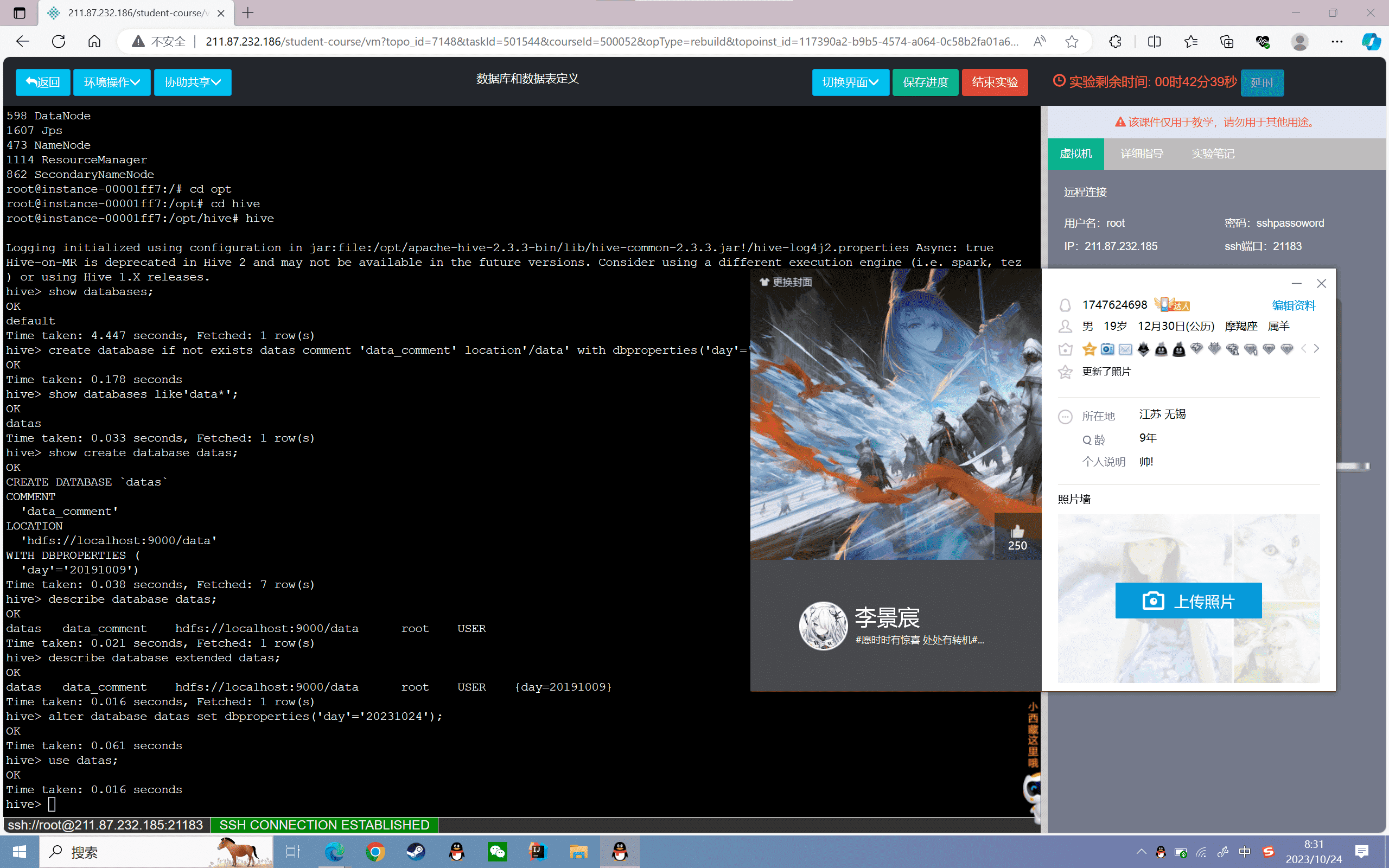
数据表的定义和操作
1、创建普通表
创建student表,分为姓名、入学日期、年龄三个字段
1 | hive> use default; |
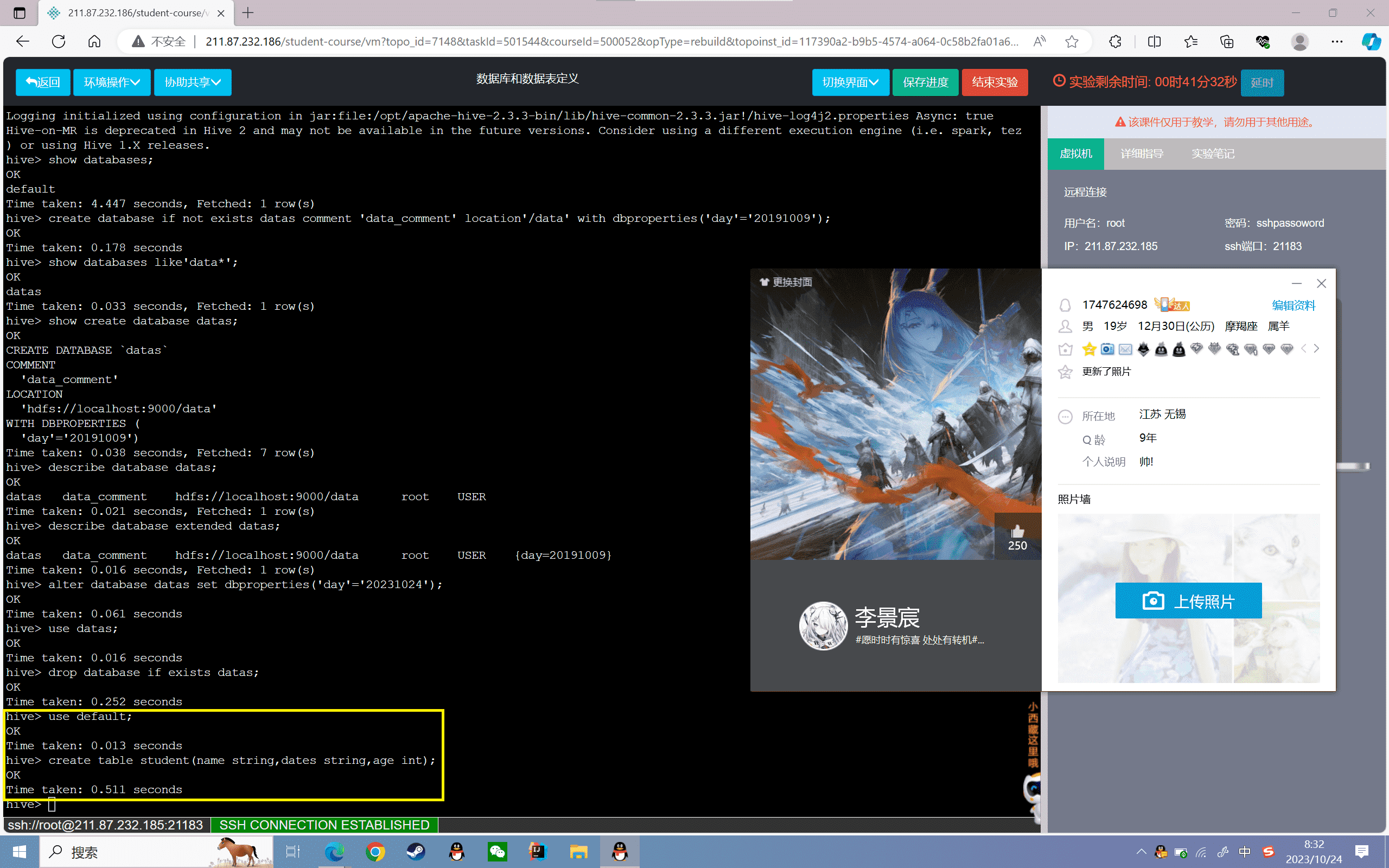
2、创建student2表,分为姓名、入学日期、年龄三个字段,数据格式以“,”分割:
1 | hive> create table student2(name string,dates string,age int) row format delimited fields terminated by ','; |
3、创建student3表,分为姓名、入学日期、年龄三个字段,数据格式以“,”分割,并制定存储位置为“/data”
1 | hive> create table student3(name string,dates string,age int) row format delimited fields terminated by ',' location'/data'; |
4、创建student4表,分为姓名、入学日期、年龄三个字段,增加数据注释,字段终止符,行终止符,并保存文件类型
1 | hive> create table student4(name string,dates string,age int) > COMMENT 'student details'> ROW FORMAT DELIMITED> FIELDS TERMINATED BY ' '> LINES TERMINATED BY ''> STORED AS TEXTFILE; |
5、查看所有表
1 | hive> show tables; |
结果如下所示:
1 | OKstudentstudent2student3student4Time taken: 0.2 seconds, Fetched: 5 row(s) |
6、模糊查询表
1 | hive> show tables in default like "stu*"; |
结果如下所示:
1 | OKstudentstudent2student3student4Time taken: 0.2 seconds, Fetched: 5 row(s) |
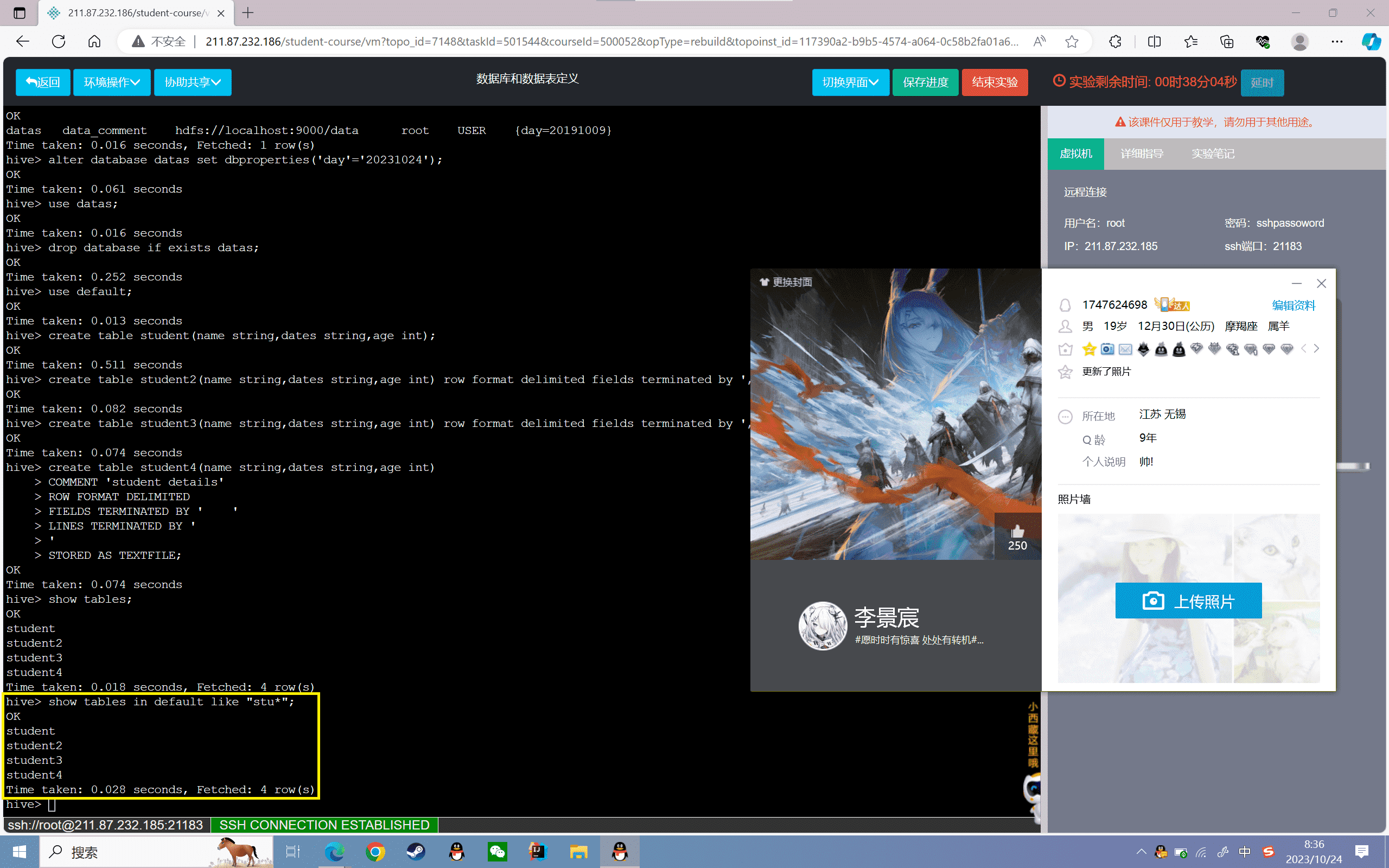
7、查看表的详细信息
1 | hive> desc student2; |
结果如下所示:
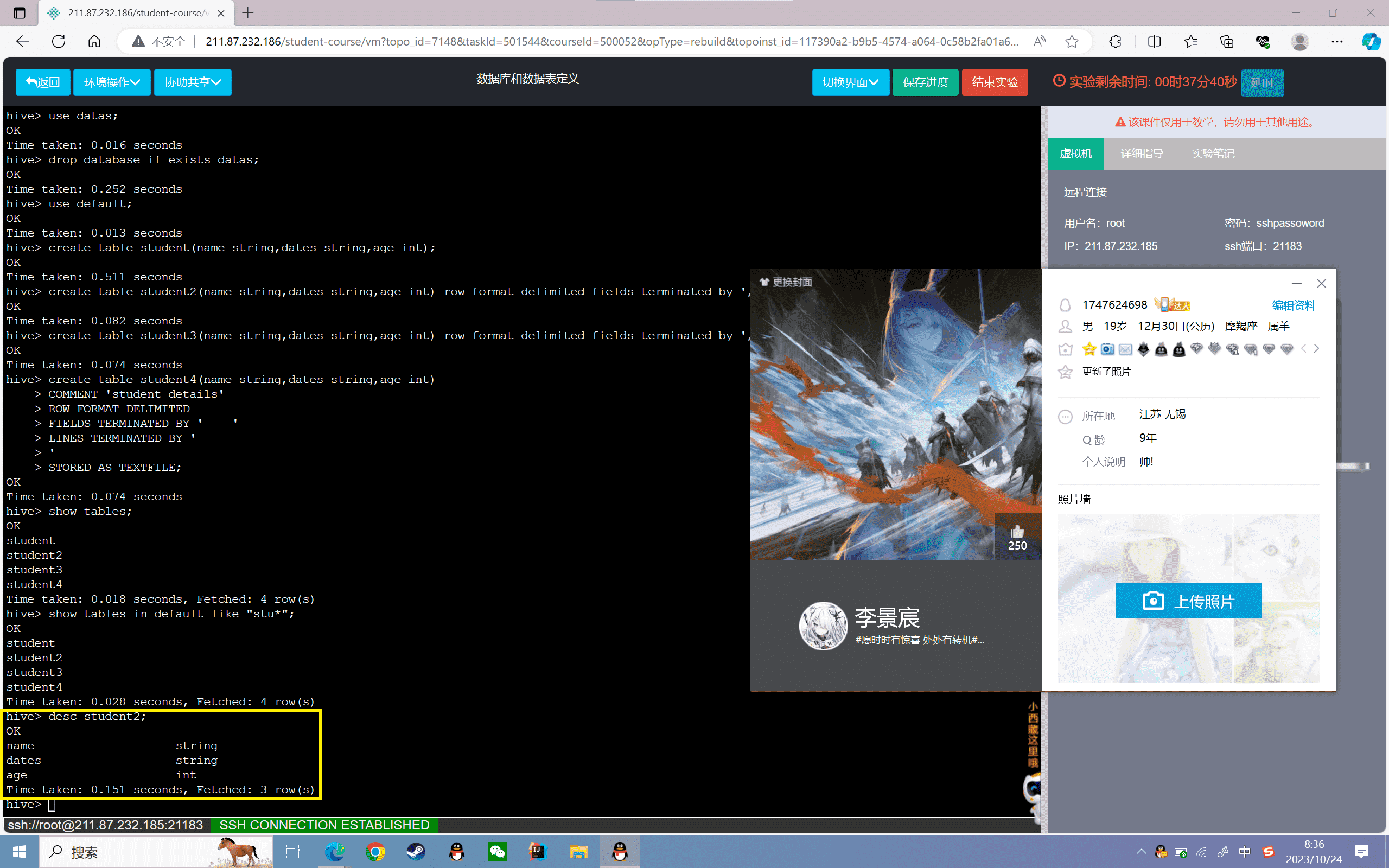
8、修改表名称
1 | hive> alter table student rename to new_student;hive> show tables; |
可以发现原来的“student”表名已经修改为“new_student”h
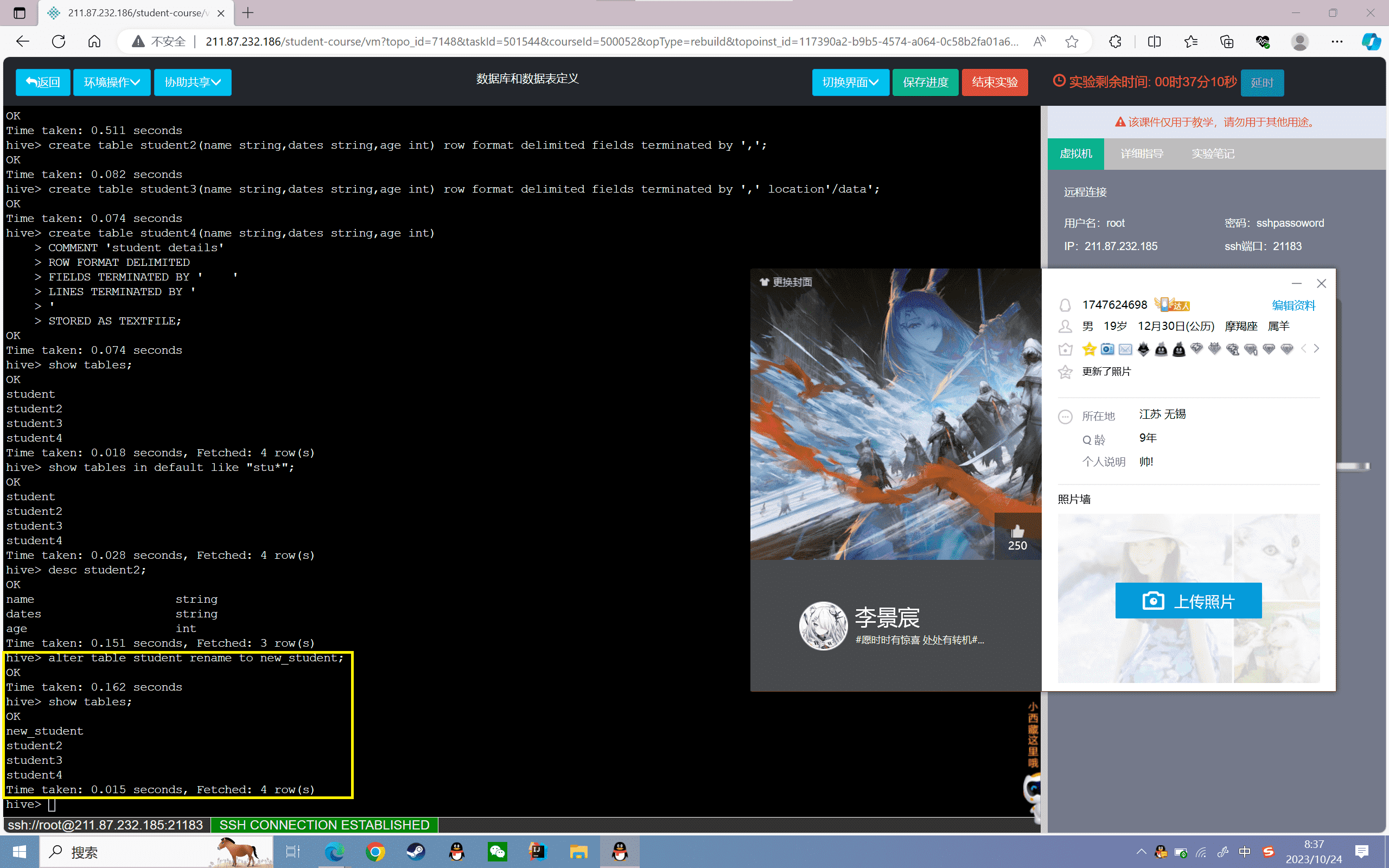
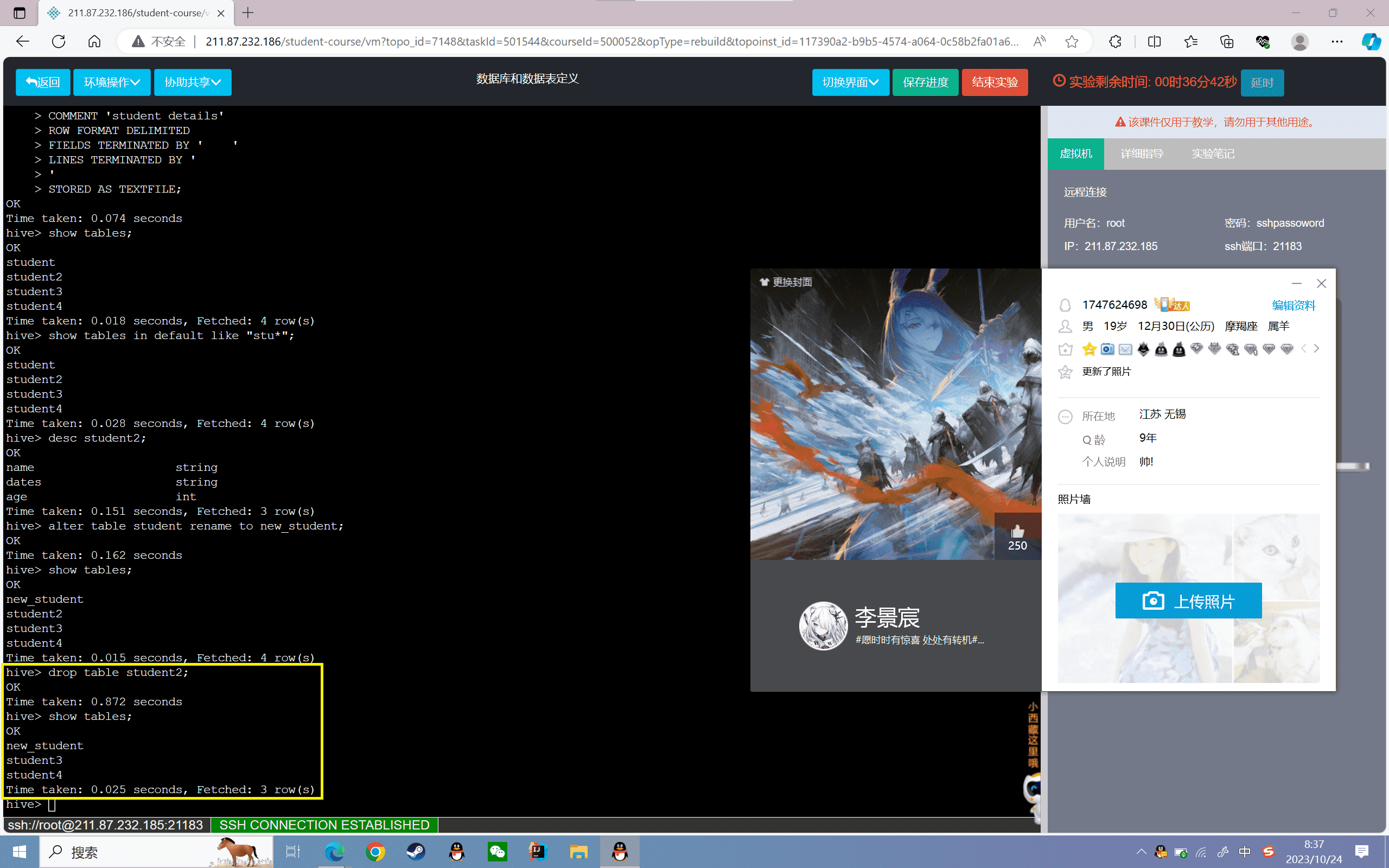
9、删除表
1 | hive> drop table student2;hive> show tables; |
可以发现原来的“student2”表已经被删除
实验感悟
通过这次的数据库和数据表定义实验,我对Hive的数据库和表的定义和操作有了更深入的理解。实验通过 Hive 命令行界面创建和操作数据库和表,让我对 Hive 的基本操作有了第一手的体验。
实验中我掌握了数据库的创建、查看、使用和删除操作。数据库可以添加注释、指定存储位置、以及添加描述性信息。我还了解到表的创建语法,可以指定各个字段、表注释、存储格式等信息。表支持多种存储格式如 TEXTFILE、SEQUENCEFILE 等。我掌握了查询表的信息、修改表名、删除表等操作。
另外,实验也让我认识到数据库和表在 HDFS 上的表现形式。数据库在 HDFS 中表现为一个目录,表表现为该数据库目录下的子目录。这种一一映射的关系有助于我理解 Hive 的表结构。分区表在 HDFS 中则表现为表目录下的子目录。
通过实践创建表操作,我加深了对 Hive 中数据库、表、分区等核心概念的理解,也了解了在 HDFS 中的表现形式。掌握了基本的 DDL 操作对我后续使用 Hive 分析数据提供了基础。这次实验让我对 Hive 有了直观的了解,是非常有意义的一次学习经历。
实验 2.2
实验目的
掌握受管理表和外部表的创建方式
理解受管理表和外部表的区别
实验内容
1、启动Hadoop服务和Hive服务
2、受管理表的操作
3、外部表的操作
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
未被external修饰的是受管理表,也叫做内部表(managed table),被external修饰的为外部表(external table);
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
实验步骤
启动Hadoop服务和Hive服务
1、启动mysql,Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~# jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.hive> |
受管理表操作
受管理表(内部表)也称之为MANAGED_TABLE,数据由Hive自身管理,默认存储在/user/hive/warehouse下,也可以通过location指定,删除表时,会删除表数据以及元数据。
1、创建受管理表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
2、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | load data local inpath '/data/dataset/film_log3.log'into table film; |
3、查看film表数据的前十条:
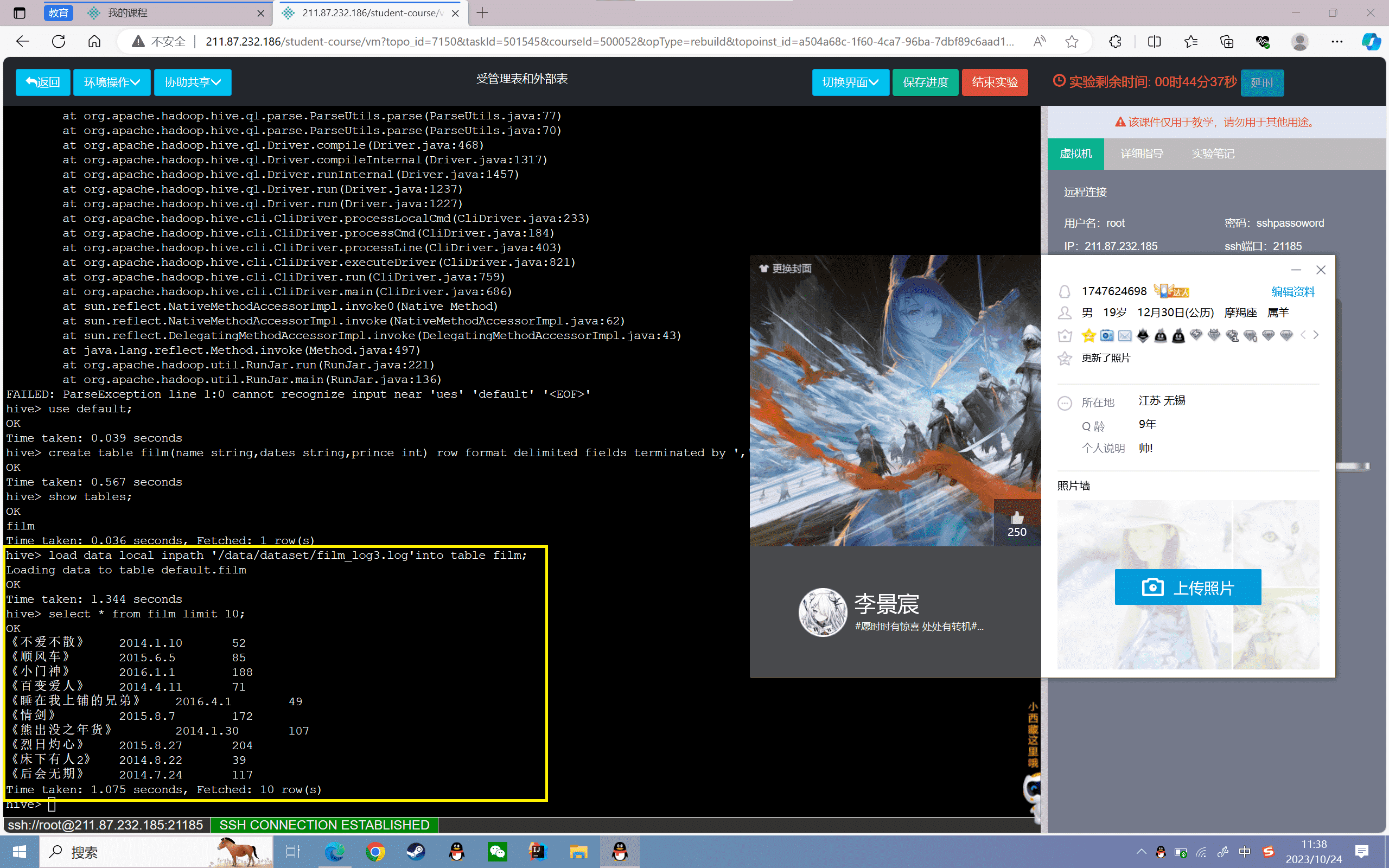
4、查看film表在hdfs存储位置
1 | hive> dfs -ls /user/hive/warehouse/film; |
可以看到上传的数据文件
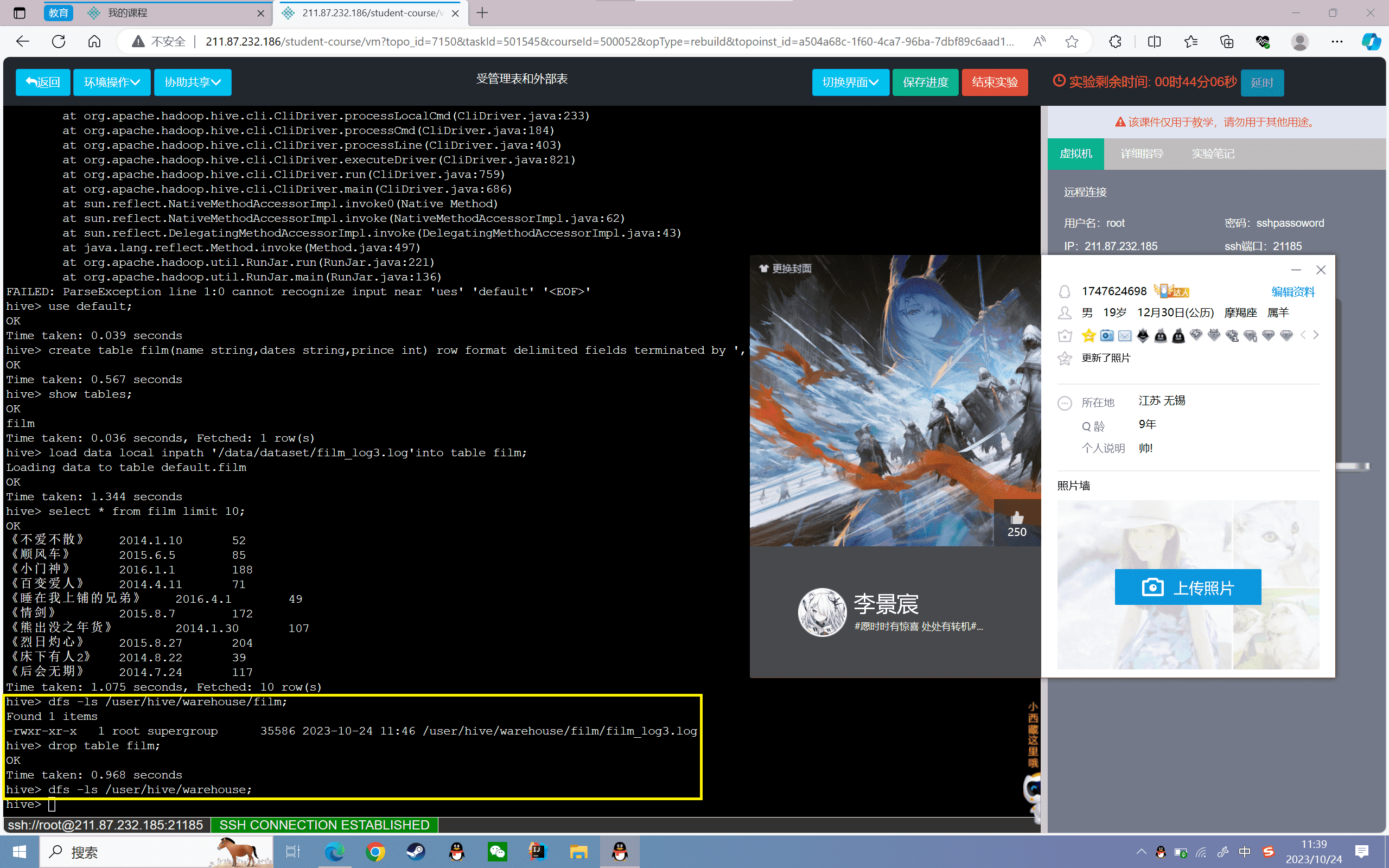
5、删除表并查看数据文件
1 | hive> drop table film;hive> dfs -ls /user/hive/warehouse; |
可以看到删除表以后,对应的数据也删除了,同样可以在MySQL中查看元数据,也删除了。
外部表的操作
外部表称之为EXTERNAL_TABLE,数据由HDFS管理。在创建表时可以自己指定目录位置(LOCATION),删除表时,只会删除元数据不会删除表数据
1、外部表的创建
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割,数据存储路径为“/user/film”:
1 | hive> create external table film(name string,dates string,prince int) row format delimited fields terminated by ',' location'/user/film'; |
2、导入数据
将数据上传到HDFS“/user/film”下
1 | hive> dfs -put /data/dataset/film_log3.log /user/film/; |
3、查看film表数据的前十条:
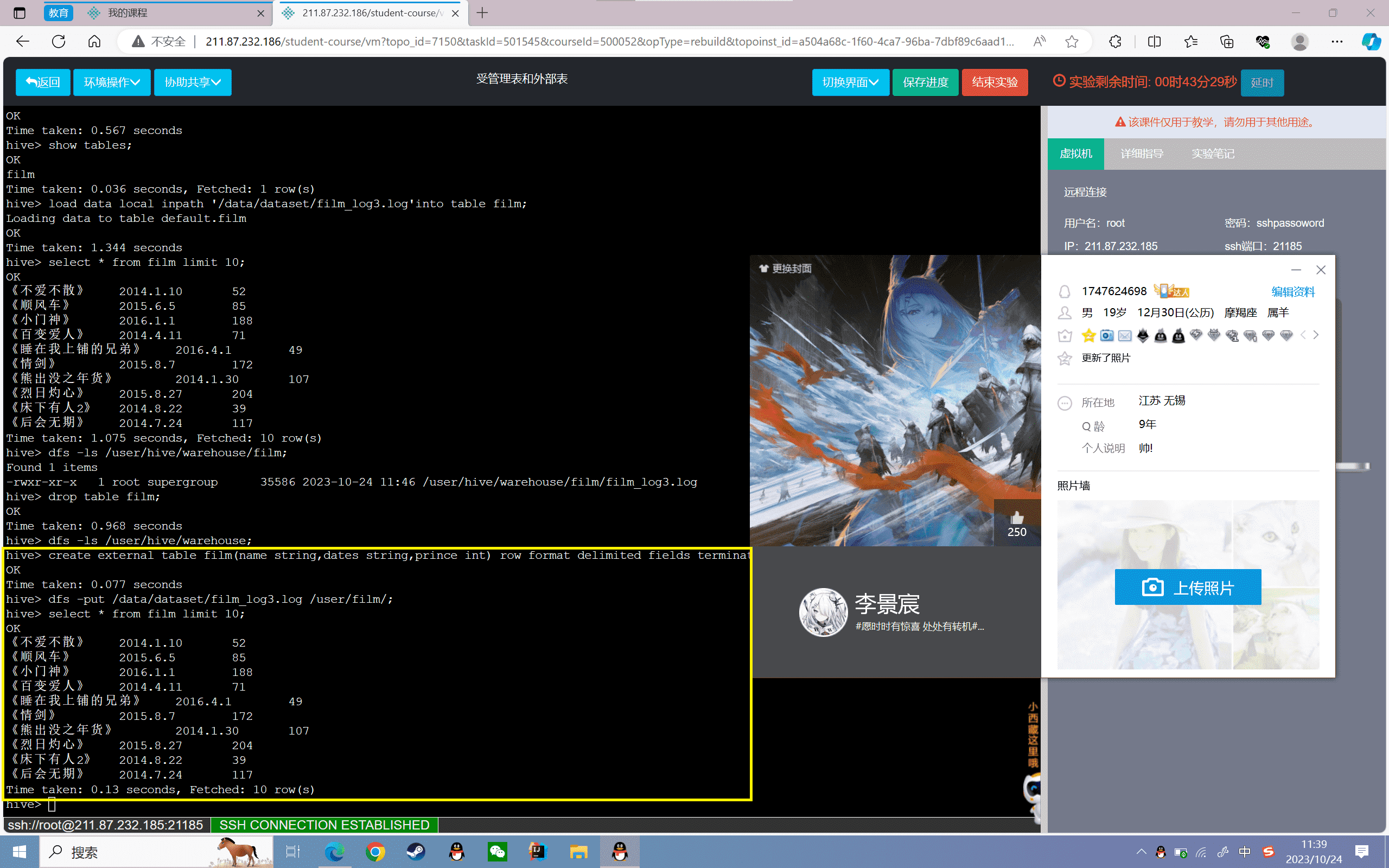
4、查看film表在hdfs存储位置
1 | hive> dfs -ls /user/film/; |
可以看到上传的数据文件
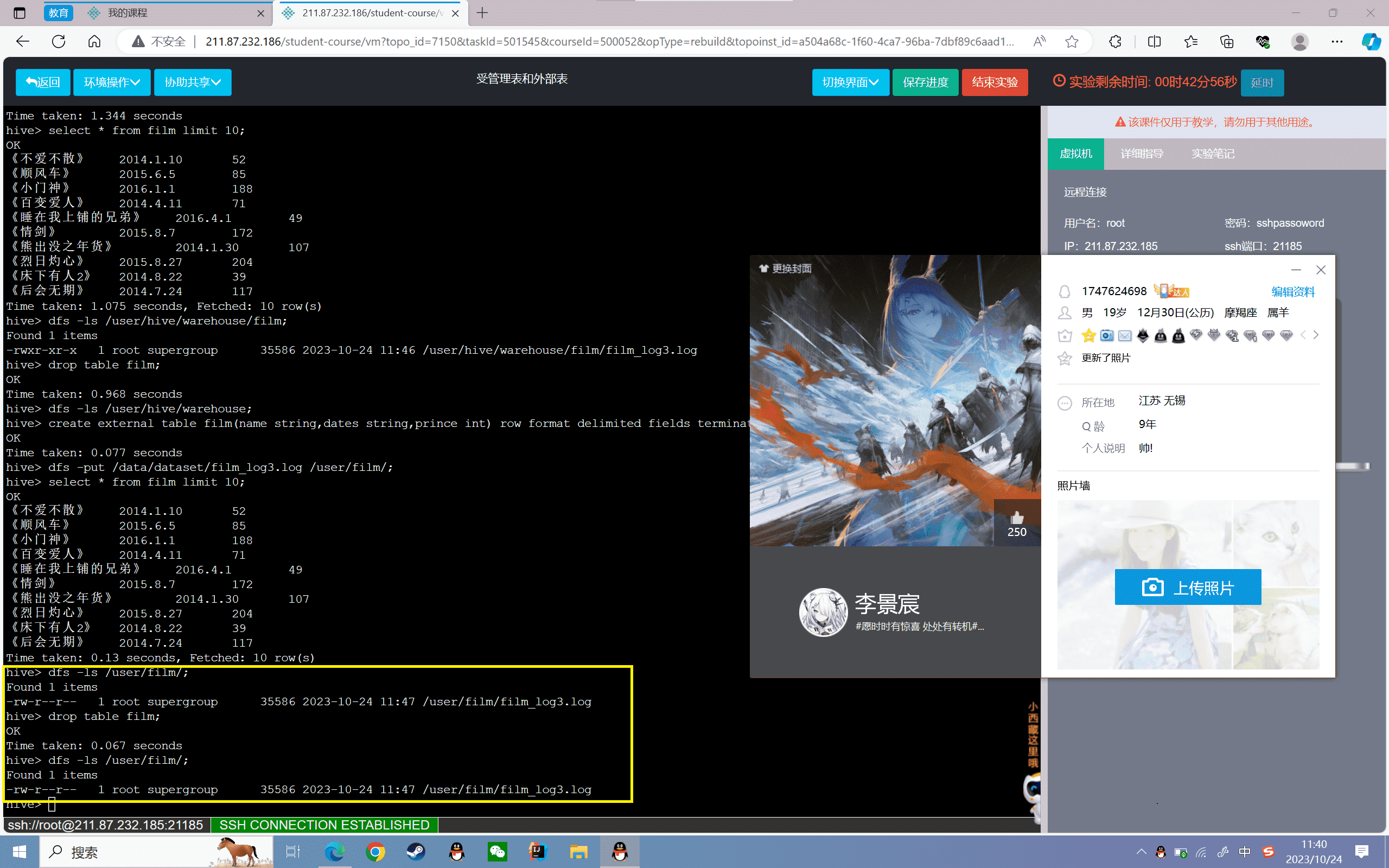
5、删除表并查看数据文件
1 | hive> drop table film;hive> dfs -ls /user/film/; |
可以看到删除表以后,对应的数据并没有删除了,同样可以在MySQL中查看元数据,发现已经删除了。
实验感悟
本次实验主要探究了Hive中受管理表和外部表的区别。受管理表的数据由Hive管理,存储在Hive的默认位置/user/hive/warehouse,删除表时会同时删除数据和元数据。而外部表的数据由HDFS管理,可以自定义存储位置,删除表只会删掉元数据,不会删除HDFS上的数据。
实验中,我先创建了一个受管理表film,指定了字段和分隔符。然后向表中导入本地数据文件。删除表后,HDFS上的数据被同时删除。这说明受管理表数据由Hive管理。之后我创建外部表film,指定存储在/user/film路径。删除表后,/user/film路径的数据依然存在,仅元数据被删除。
通过对比受管理表和外部表的创建、加载数据、删除表的操作,我直观地了解了两者的区别:受管理表更适合Hive自身管理的场景,外部表更适合多用户共享的场景。受管理表删除时 datafile 被删除,外部表删除时 datafile 依然存在。
本实验加深了我对Hive管理表与外部表的概念理解,也让我对两种表的适用场景有了清晰的认识。掌握不同表类型的特点,可以让我后续根据分析需求灵活运用表的功能。这是一次收获颇丰的学习经历。
实验 2.3
实验目的
掌握数据导入Hive表的方式
理解三种数据导入Hive表的原理
实验内容
1、启动Hadoop服务和Hive服务
2、使用load直接导入
3、使用put上传导入
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的导入:
1.直接load导入
使用load命令,从HDFS或者本地将数据导入hive的指定表中,本地导入则是上传到Hive的指定文件夹,HDFS导入则是从HDFS移动到指定文件夹
2.put导入
使用HDFS的命令put将数据传到指定的Hive文件夹下
实验步骤
启动Hadoop服务和Hive服务
1、启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~#jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.hive> |
使用load直接导入
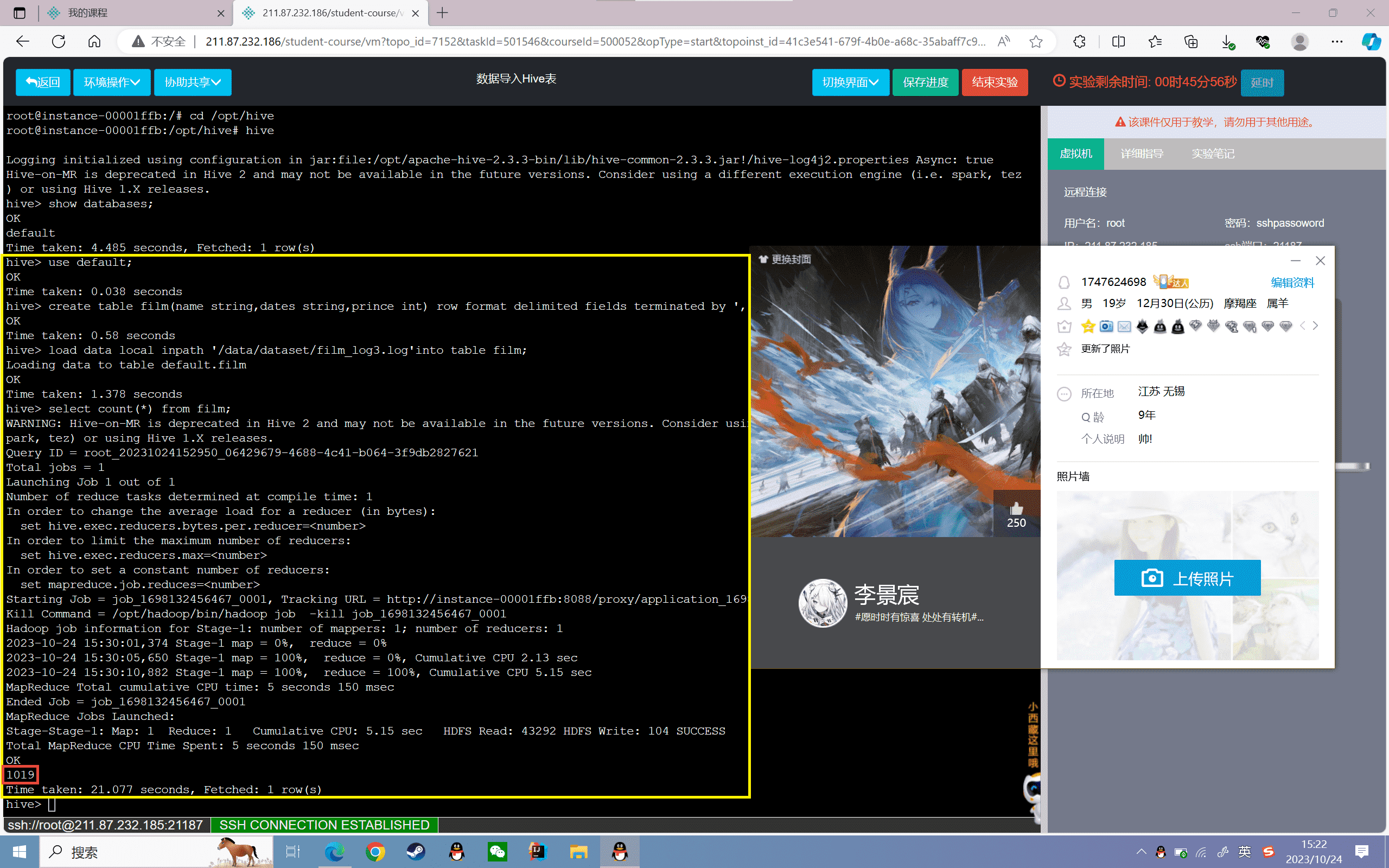
1、创建表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | hive> create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
2、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | hive> load data local inpath '/data/dataset/film_log3.log'into table film; |
3、查看film表数据的总条数:
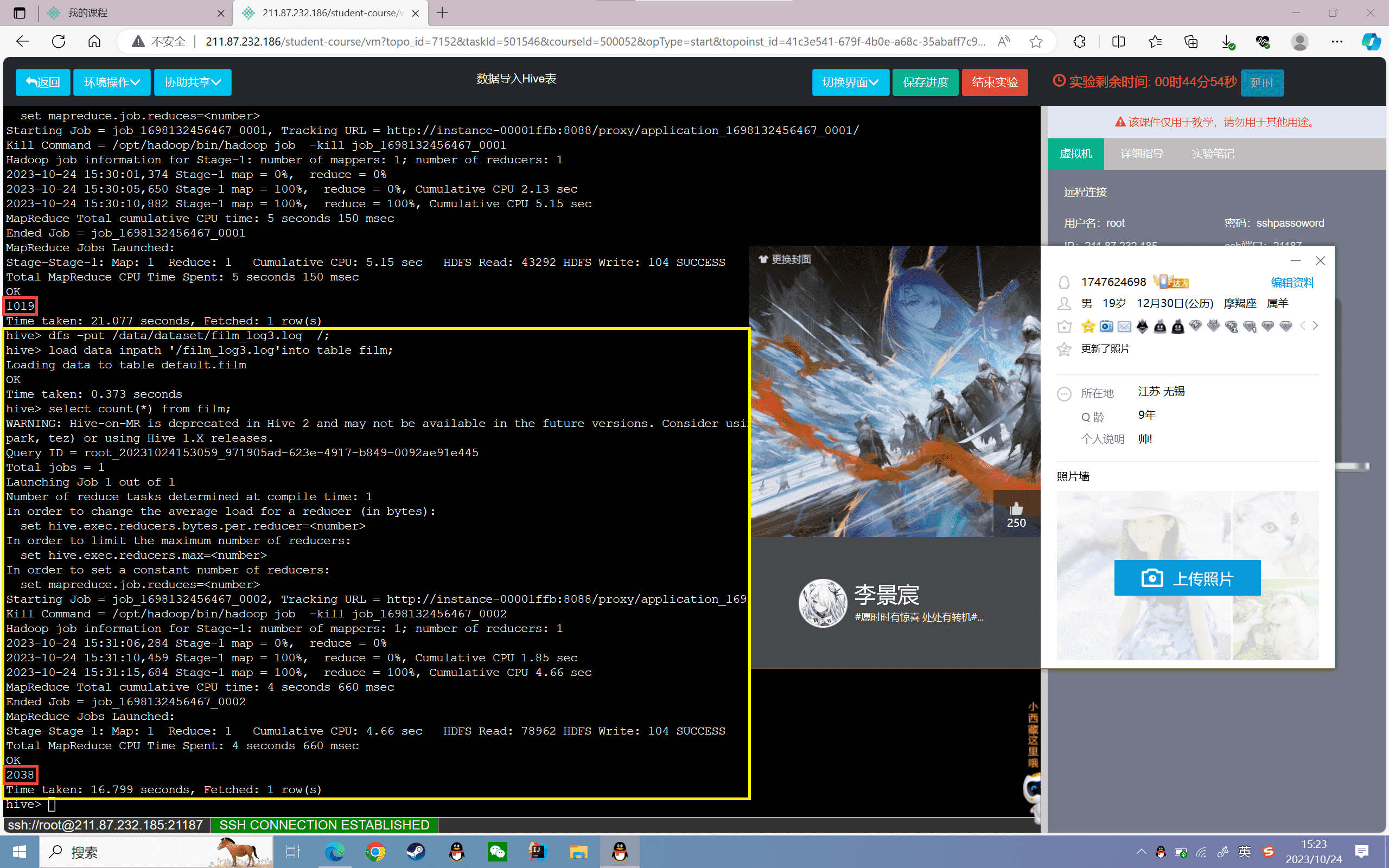
1 | hive> select count(*) from film; |
4、将HDFS的film_log3.log文件数据加载到film表:
1 | hive> dfs -put /data/dataset/film_log3.log /;hive> load data inpath '/film_log3.log'into table film; |
5、查看film表数据的总条数:
1 | hive> select count(*) from film; |
可以看到film的总条数变为之前的2倍,说明导入成功了。
使用put上传导入
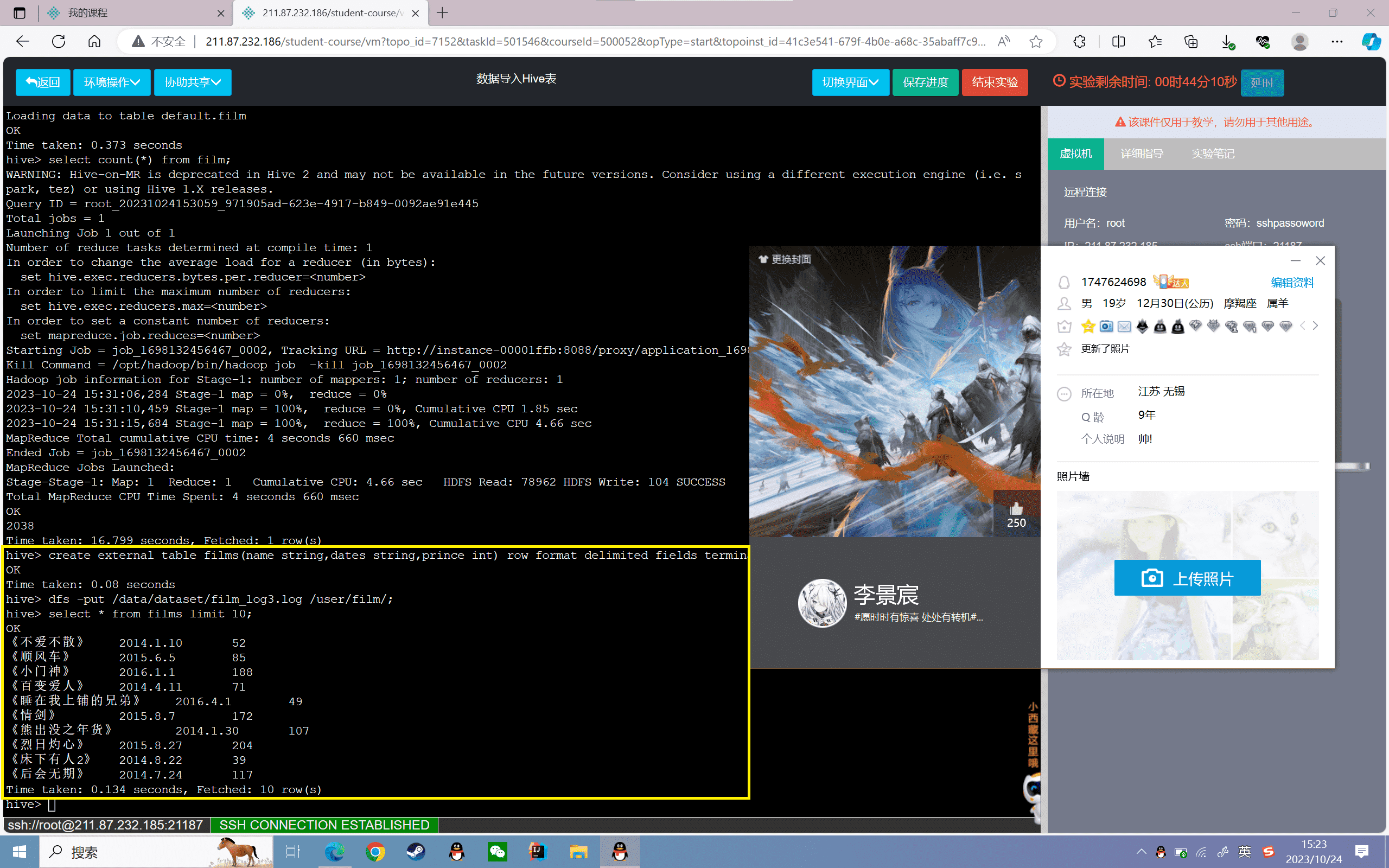
1、外部表的创建
创建films表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割,数据存储路径为“/user/film”:
1 | hive> create external table films(name string,dates string,prince int) row format delimited fields terminated by ',' location'/user/film'; |
2、导入数据
将数据上传到HDFS“/user/film”下
1 | hive> dfs -put /data/dataset/film_log3.log /user/film/; |
3、查看film表数据的前十条:
实验感悟
本次实验主要探究了将数据导入Hive表的两种方式:load直接导入和put上传导入。load可以从本地文件或HDFS路径导入数据到Hive表中。put可以先将本地数据上传到HDFS指定路径,再创建外部表指向该路径即可。
实验中,我先用load命令将本地文件的film_log3.log数据导入内部表film中。加载前后对比表中的数据条数可以看出数据成功导入。又用load从HDFS路径导入数据,实现了从HDFS向Hive表内部加载数据。
之后通过put命令上传本地数据到HDFS路径,再创建外部表films指向该路径。查询表数据可以看到文件的数据成功导入表中。put命令实现了本地文件先上传到HDFS,再通过外部表访问的方式。
通过本实验,我掌握了load和put两种方式向Hive导入数据,load适用于内部表,put适用于外部表场景。实践导入操作加深了我对加载数据到Hive表的理解,也让我对不同导入方式的适用场景有了直观感受。掌握导入数据的技能对我使用Hive分析海量数据提供了基础。这是一次非常愉快的学习过程。
实验 3.1
实验目的
掌握Hive的HQL查询常用操作
掌握Hive的HQL语法使用
实验内容
1、基础查询操作
2、启动Hadoop服务和Hive服务
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的数据查询:
对Hive中的数据进行查询操作,使用类似SQl语句的HQL进行查询,包括SQl中常用where、like、between and等基本查询操作。
实验步骤
启动Hadoop服务和Hive服务
1、启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~#jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
1 | Logging initialized using configuration in jar:file:/root/simple/bigdata/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.hive> |
3、创建表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | hive> create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
4、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | hive> load data local inpath '/data/dataset/film_log3.log'into table film; |
5、查看film表数据的前十条:
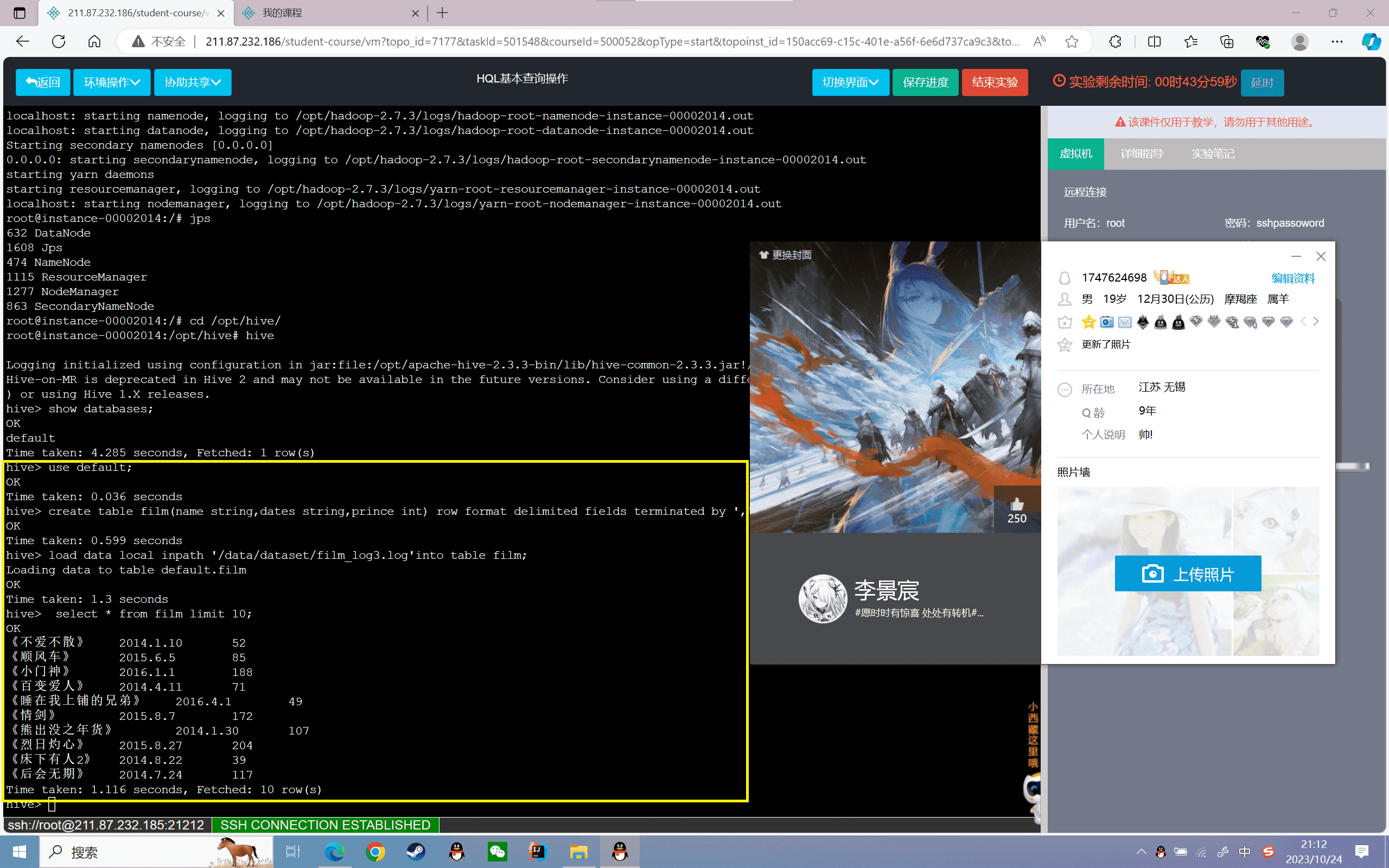
基础查询操作
1、查询film表的所有信息:
1 | hive> select * from film; |
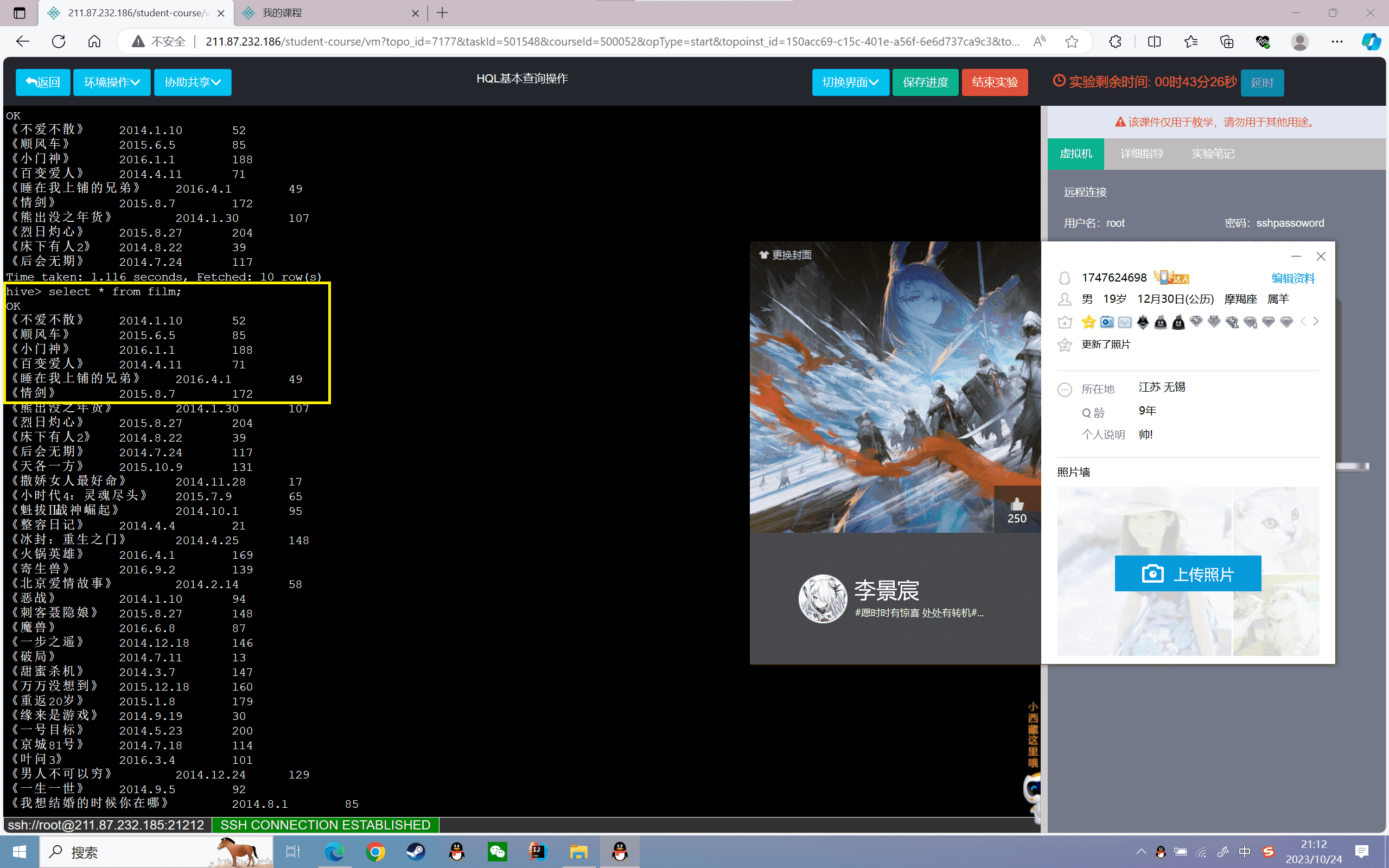
2、查询film表的名称和票房信息,分别用“n”表示电影名称,用“p”表示票房
1 | hive>select name as n,prince as p from film; |
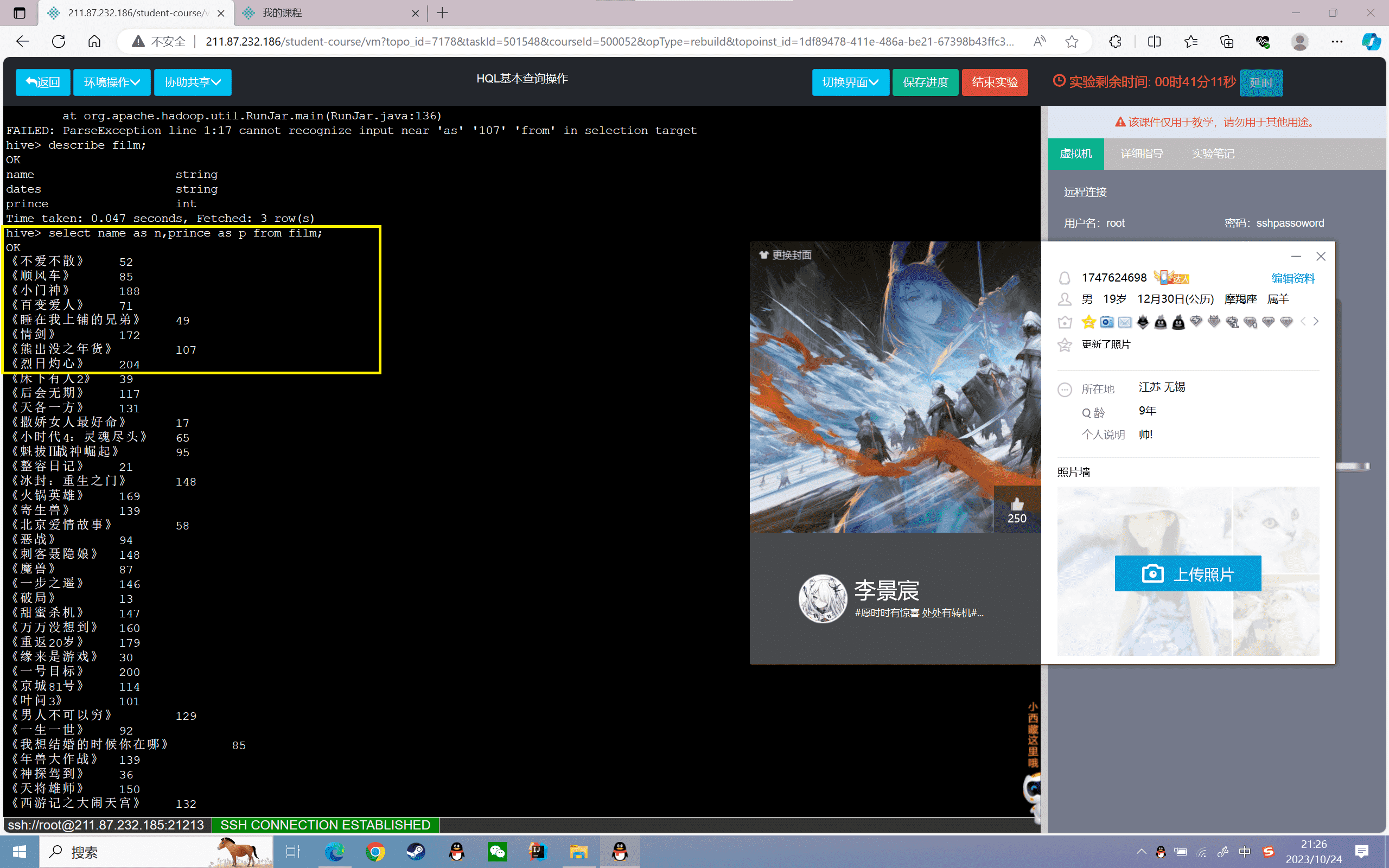
3、查询票房大于100,小于200的电影信息:
1 | hive>select * from film where prince<200 and prince>100; |
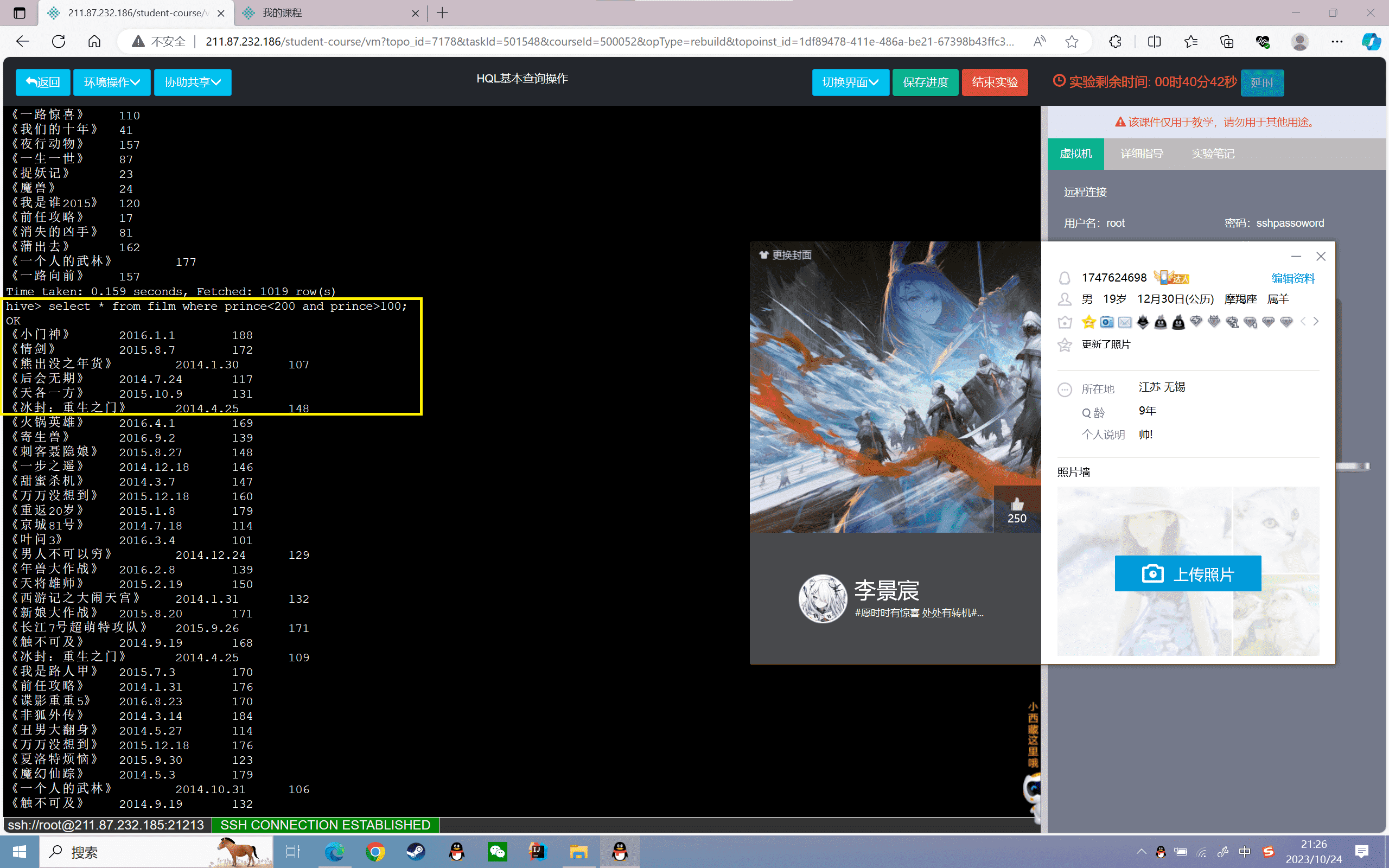
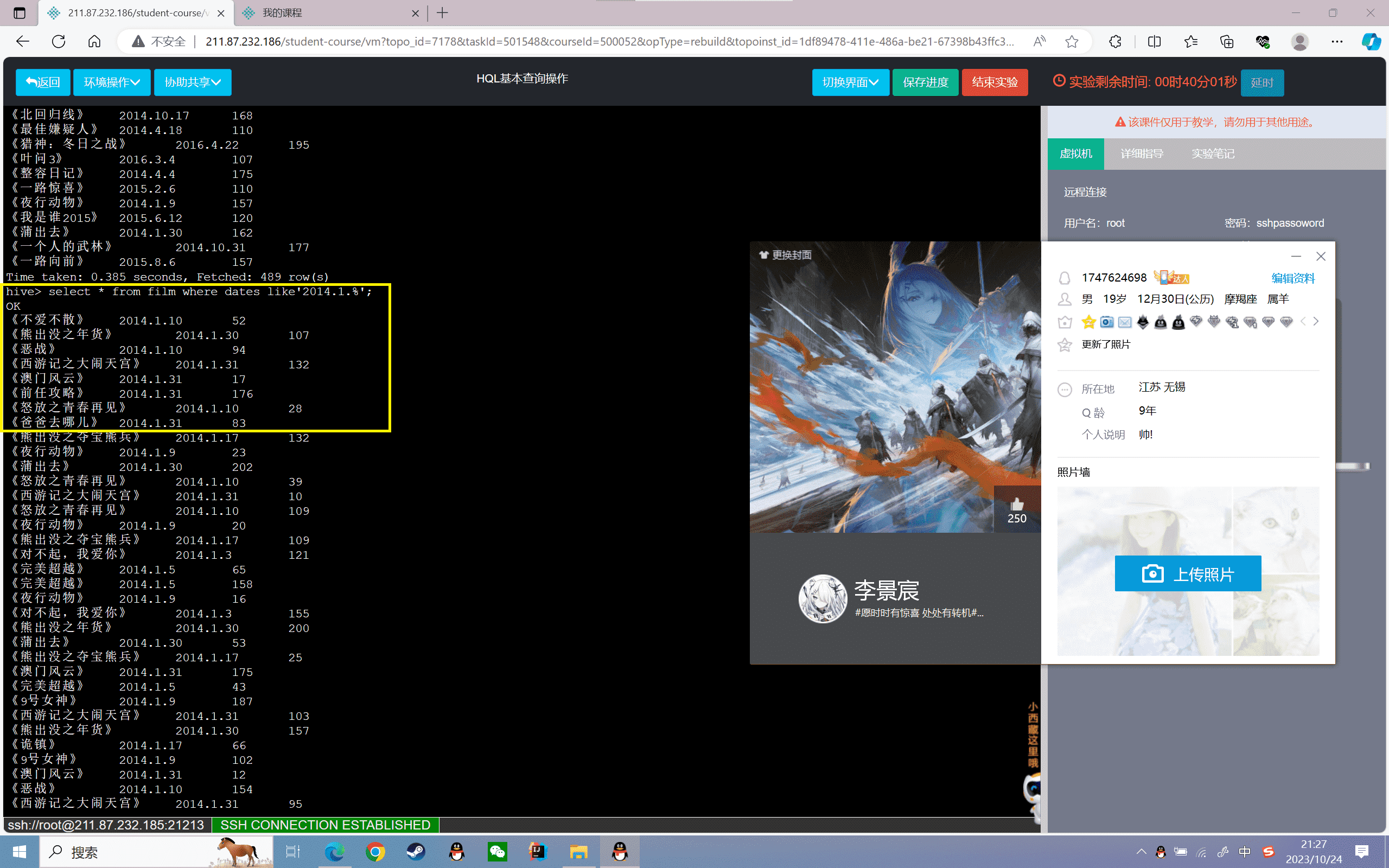
4、查询2014年1月份上映的所有电影信息:
1 | hive>select * from film where dates like'2014.1.%'; |
5、查询2015年上映的所有电影信息:
1 | hive>select * from film where dates like'2015%'; |
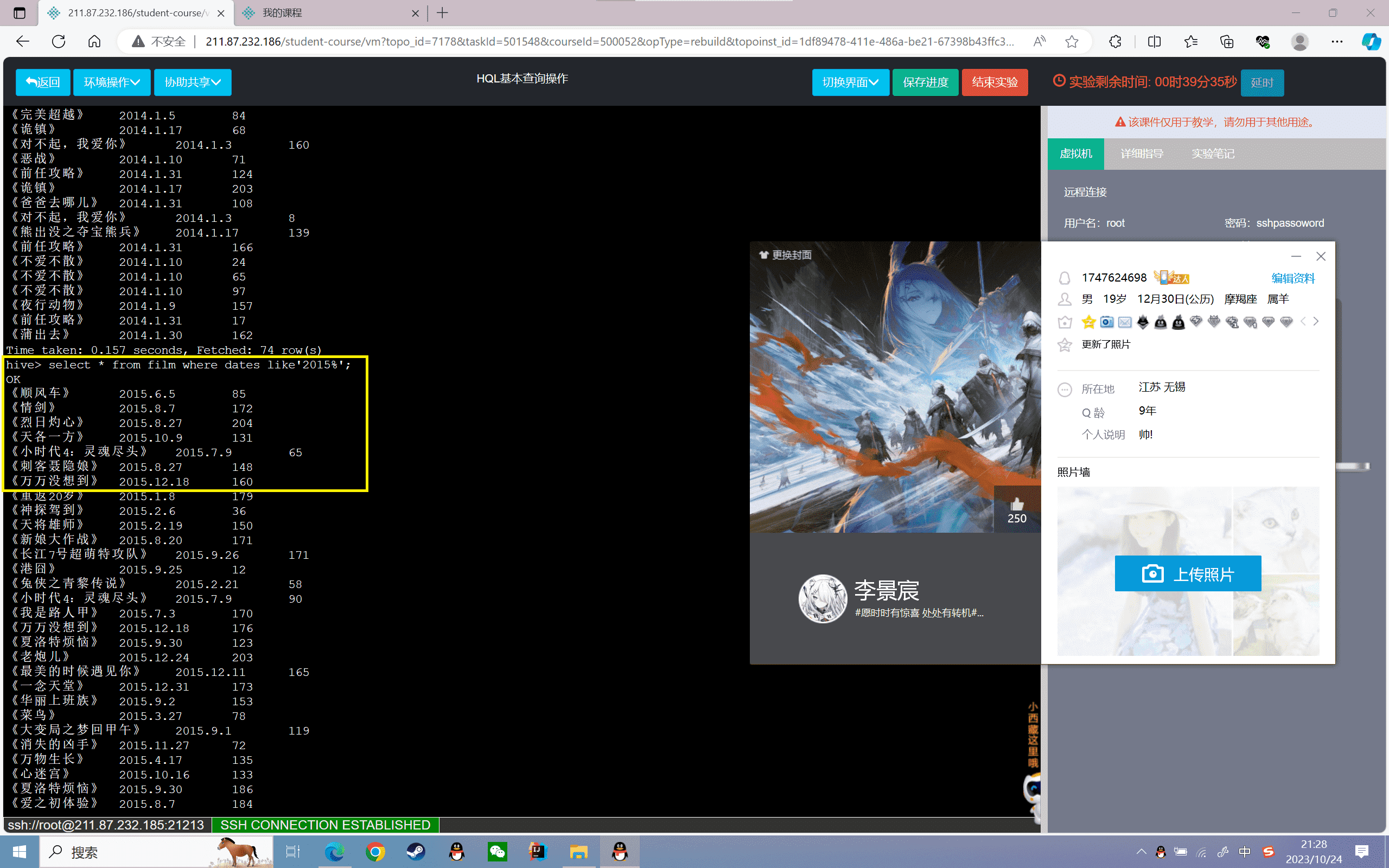
6、查询票房最高的5部电影信息:
1 | hive>select * from film order by prince desc limit 5; |
结果如下:
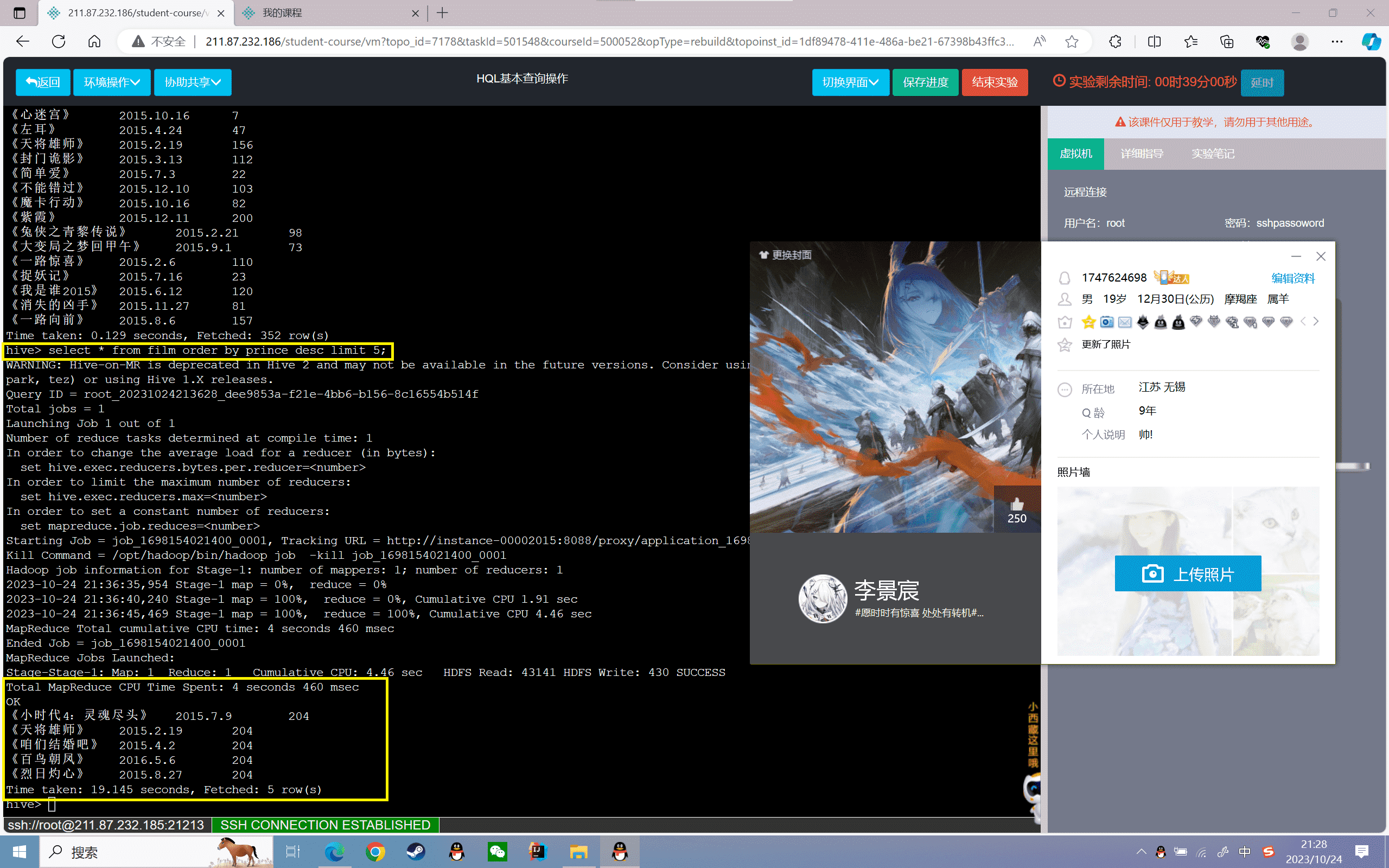
7、将票房信息都乘以10000
1 | hive>select name,dates,prince*10000 from film; |
结果如下:
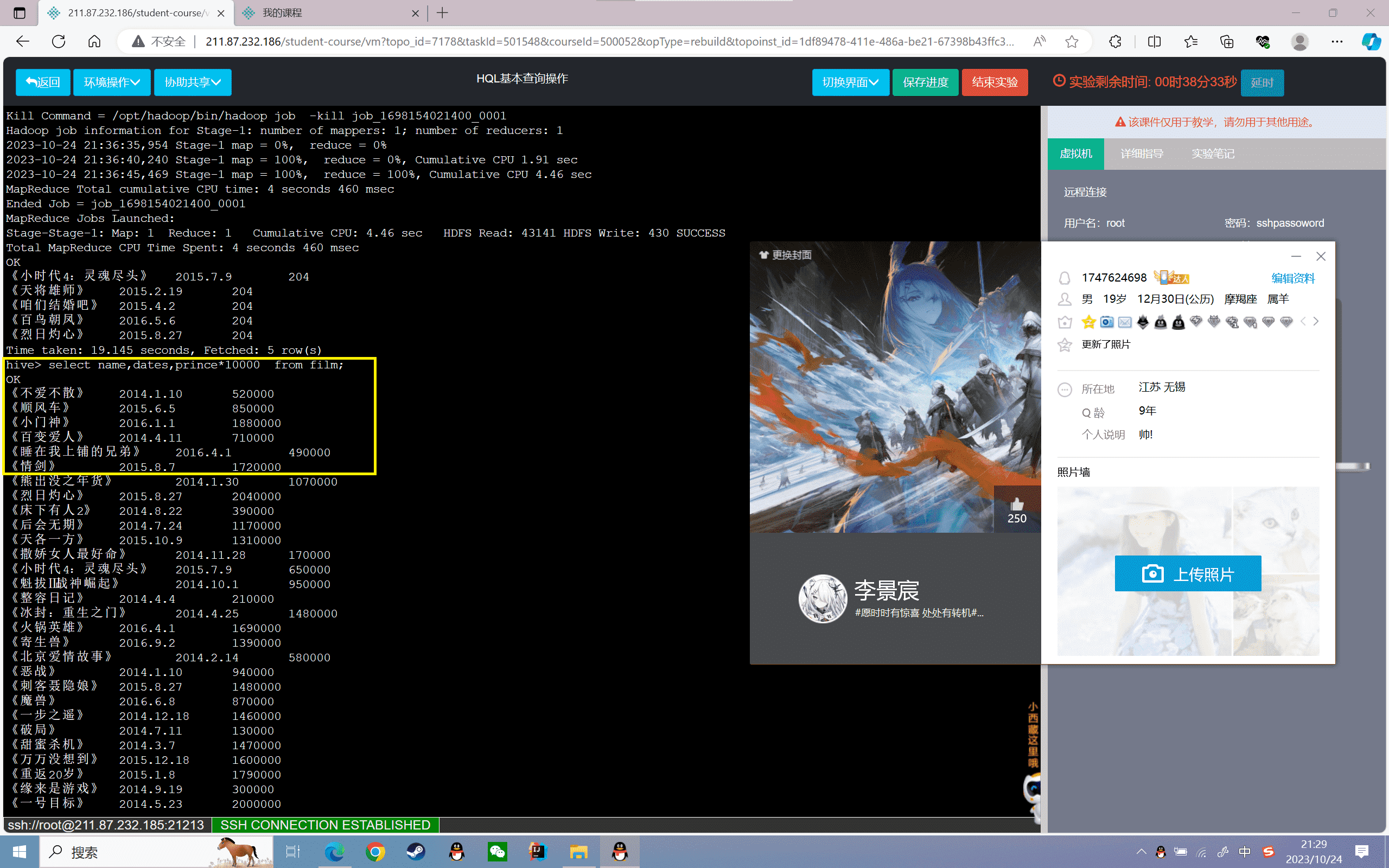
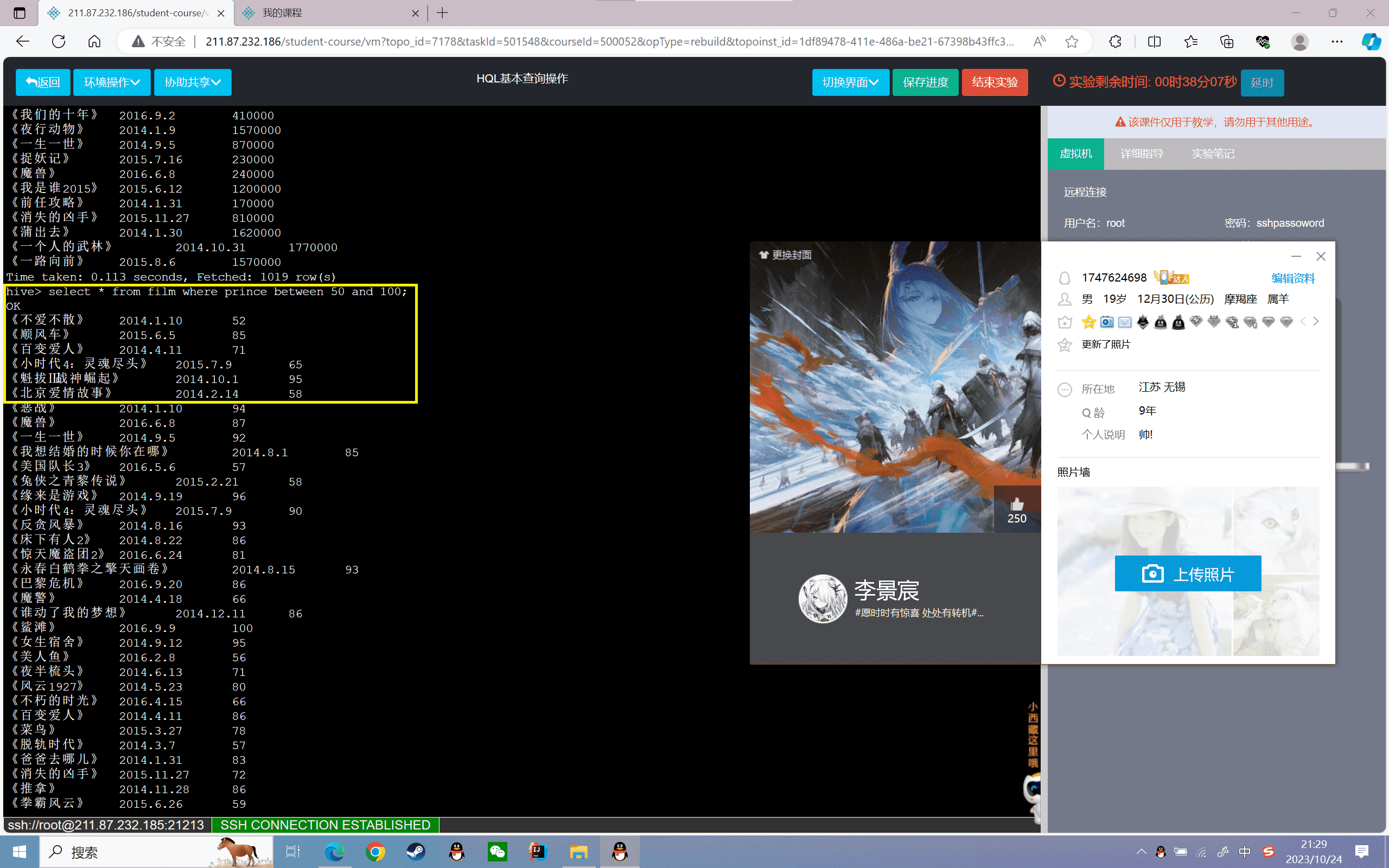
8、查询票房在50~100之间的票房信息
1 | hive>select * from film where prince between 50 and 100; |
9、查询2016年9月20日的票房信息
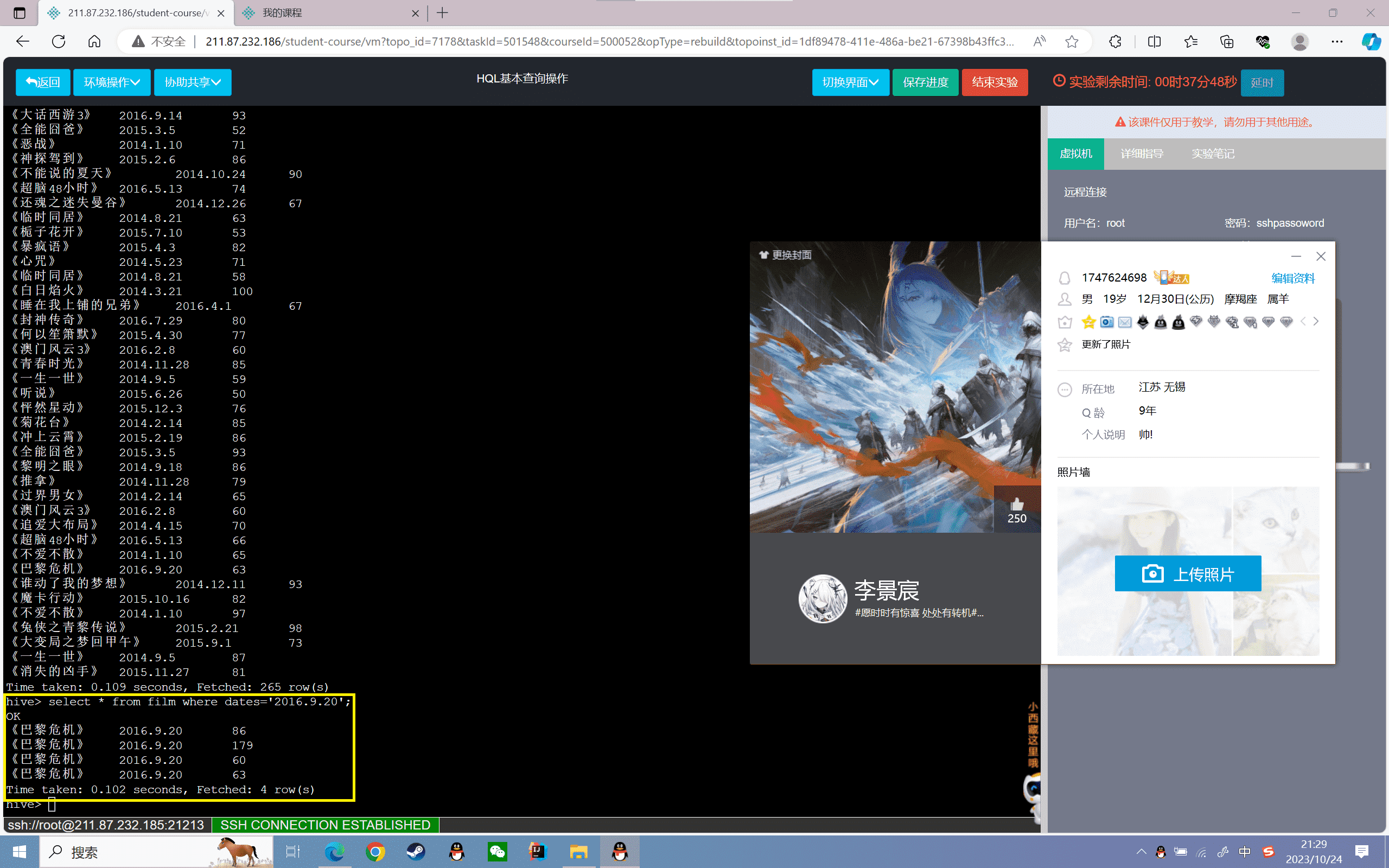
1 | hive>select * from film where dates='2016.9.20'; |
结果如下:
实验感悟
通过这个HQL基本查询操作的实验,我掌握了Hive的基本查询语法,包括选择指定列、WHERE条件筛选、LIKE模糊匹配、ORDER BY排序、LIMIT限制结果等。实验让我对Hive查询的理解更加深入, Hive的查询语法与传统SQL非常相似,可以通过简单的SQL基础进行Hive查询操作。本实验也让我对Hive表的创建、数据导入有了直接的操作体会。接下来还需要学习UDF、joins等更复杂的查询操作,以及Hive 的优化技巧。总体来说,这个实验达到了练习HQL查询的目的,提高了我使用Hive进行数据分析的能力,为后续的Hive学习奠定了基础。
实验 3.2
实验目的
掌握Hive的HQL查询聚合的常用操作
掌握Hive的HQL聚合语法使用
实验内容
1、启动Hadoop服务和Hive服务
2、聚合查询操作
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的数据聚合查询:
Hive的数据聚合查询是类似SQL的聚合查询,是在原来的基础上做了封装。它的原理是通过包含一个聚合函数(如 Sum 或 Avg )来汇总来自多个行的信息。
实验步骤
启动Hadoop服务和Hive服务,并创建表数据
1、启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~#jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
3、创建表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | hive> create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
4、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | hive> load data local inpath '/data/dataset/film_log3.log'into table film; |
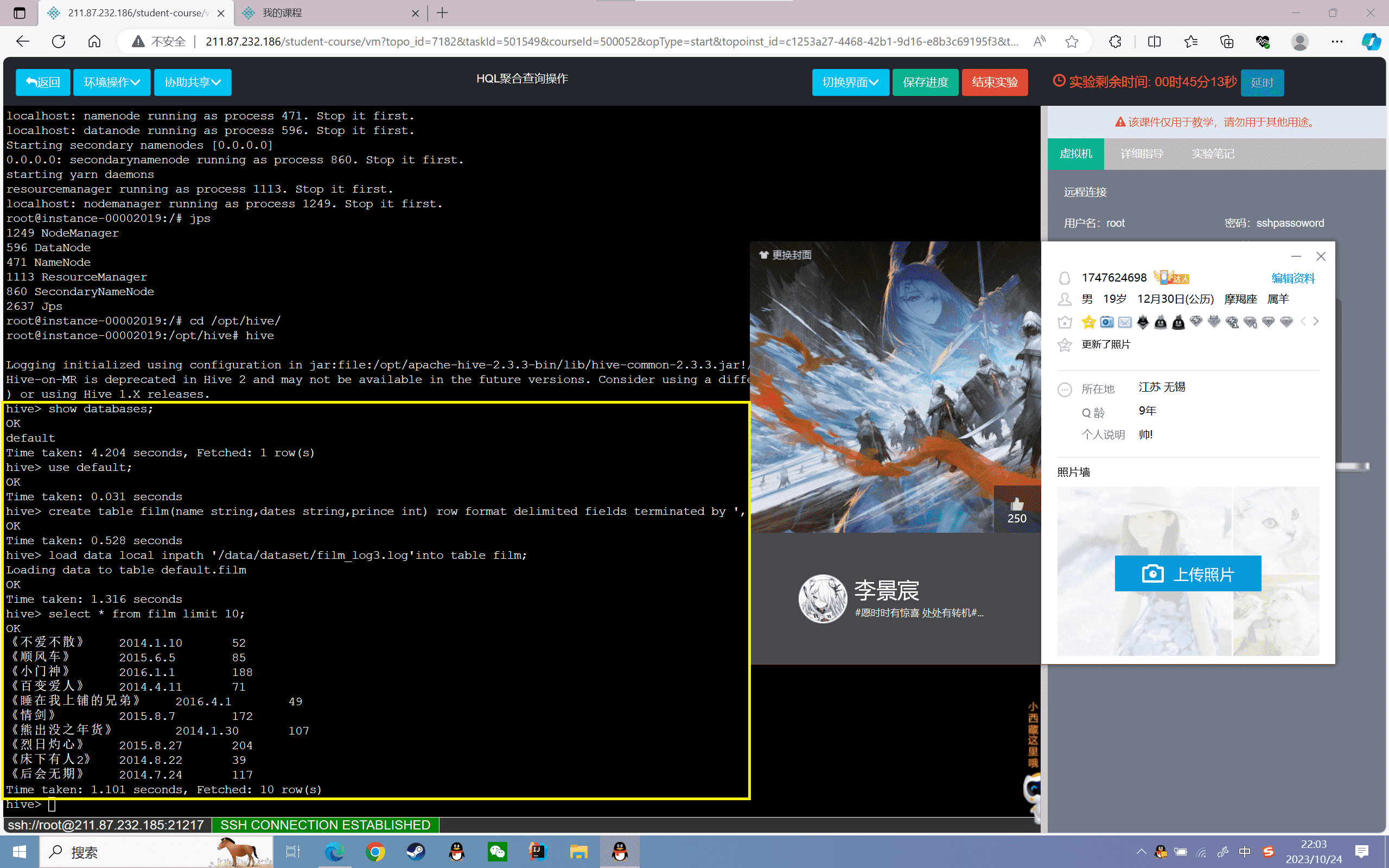
5、查看film表数据的前十条:
1 | hive> select * from film limit 10; |
结果如下:
聚合查询操作
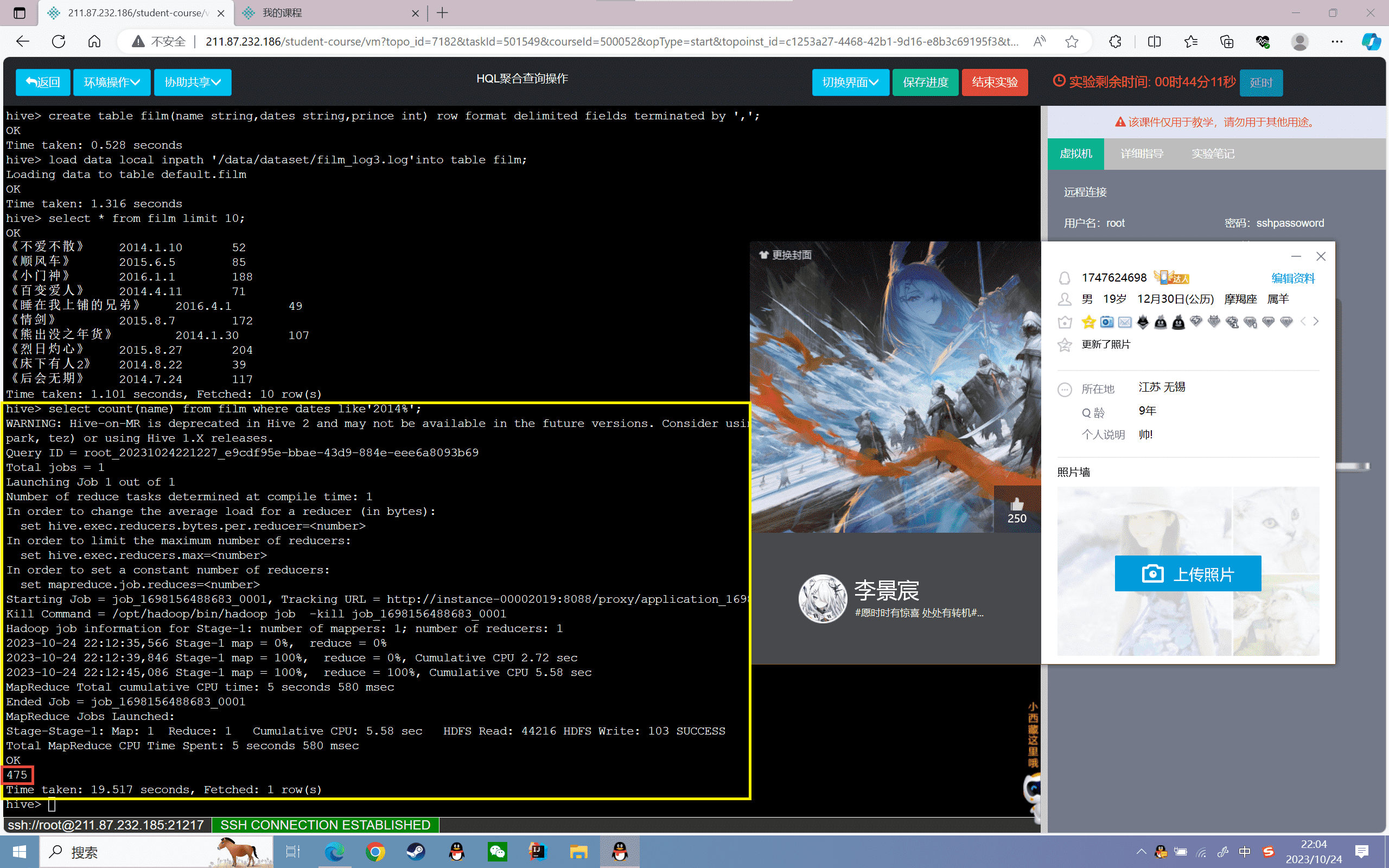
1、查询film表2014年的电影个数:
1 | hive> select count(name) from film where dates like'2014%'; |
结果如下:
2、查询film表2015年的电影票房平均值
1 | hive>select avg(prince) from film where dates like'2015%'; |
结果如下:
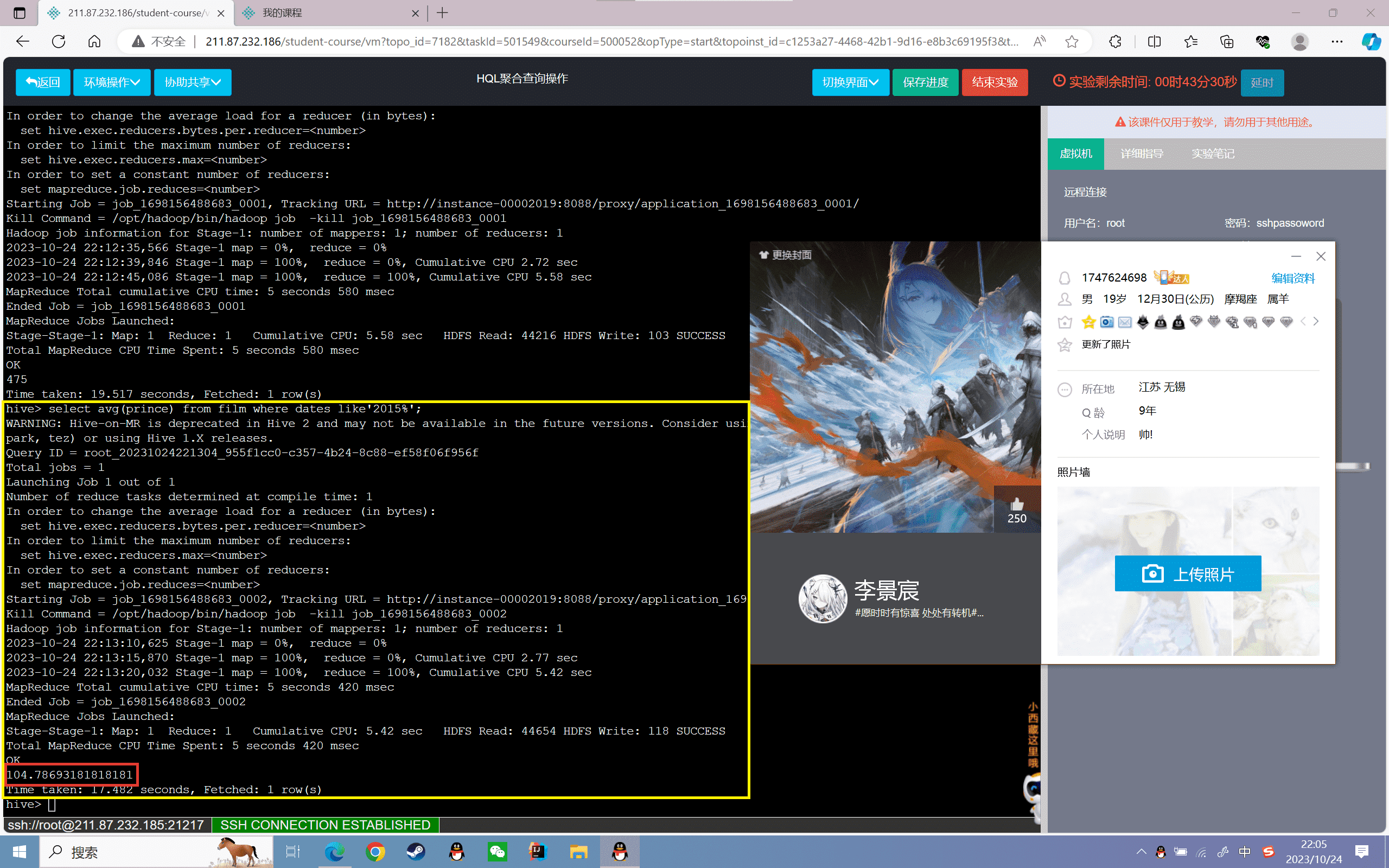
留两位小数据结果得
1 | hive>select round(avg(prince),2) from film where dates like'2015%'; |
结果如下:
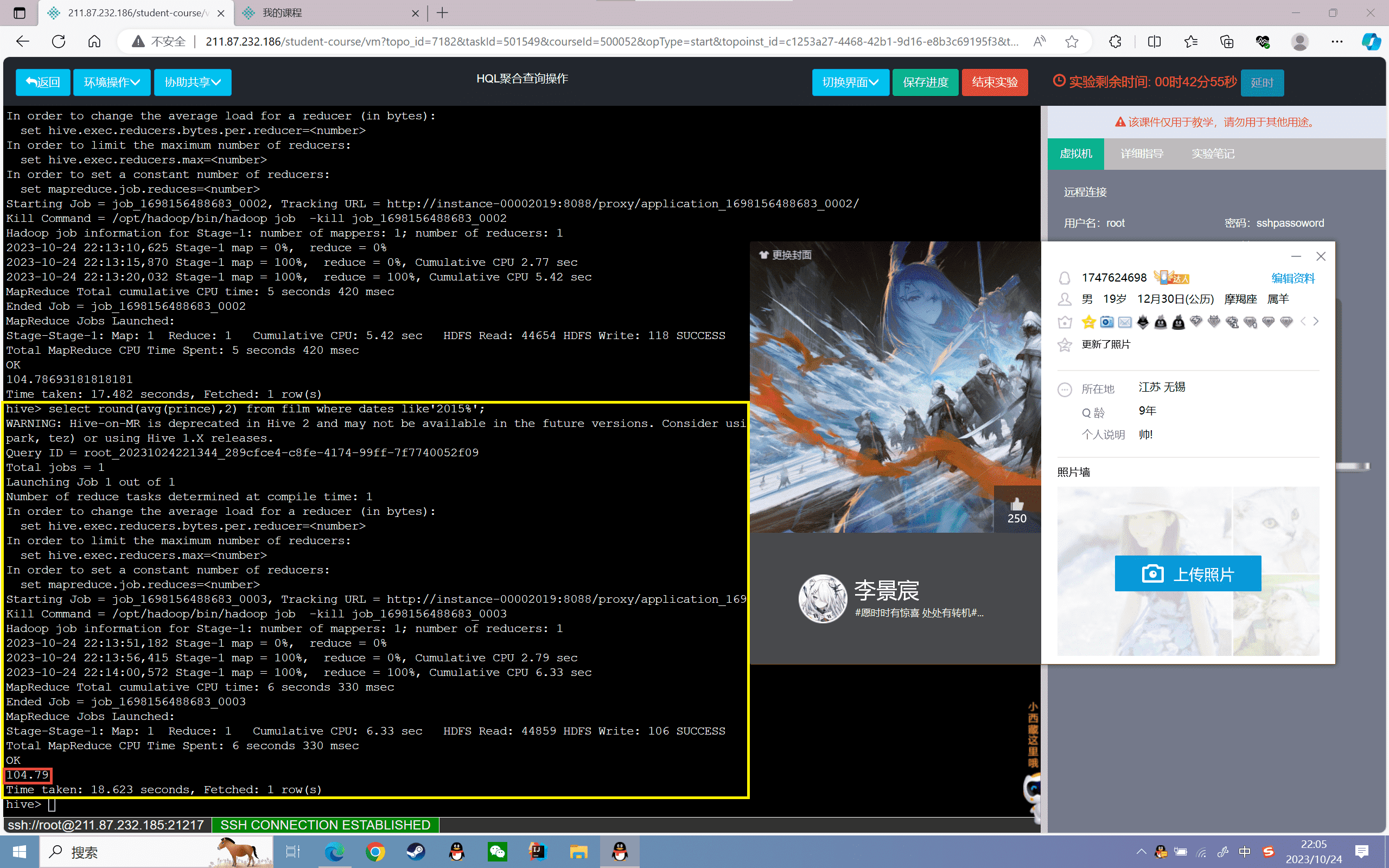
3、查询film表中2016年最高票房
1 | hive>select max(prince) from film where dates like'2016%'; |
结果如下:
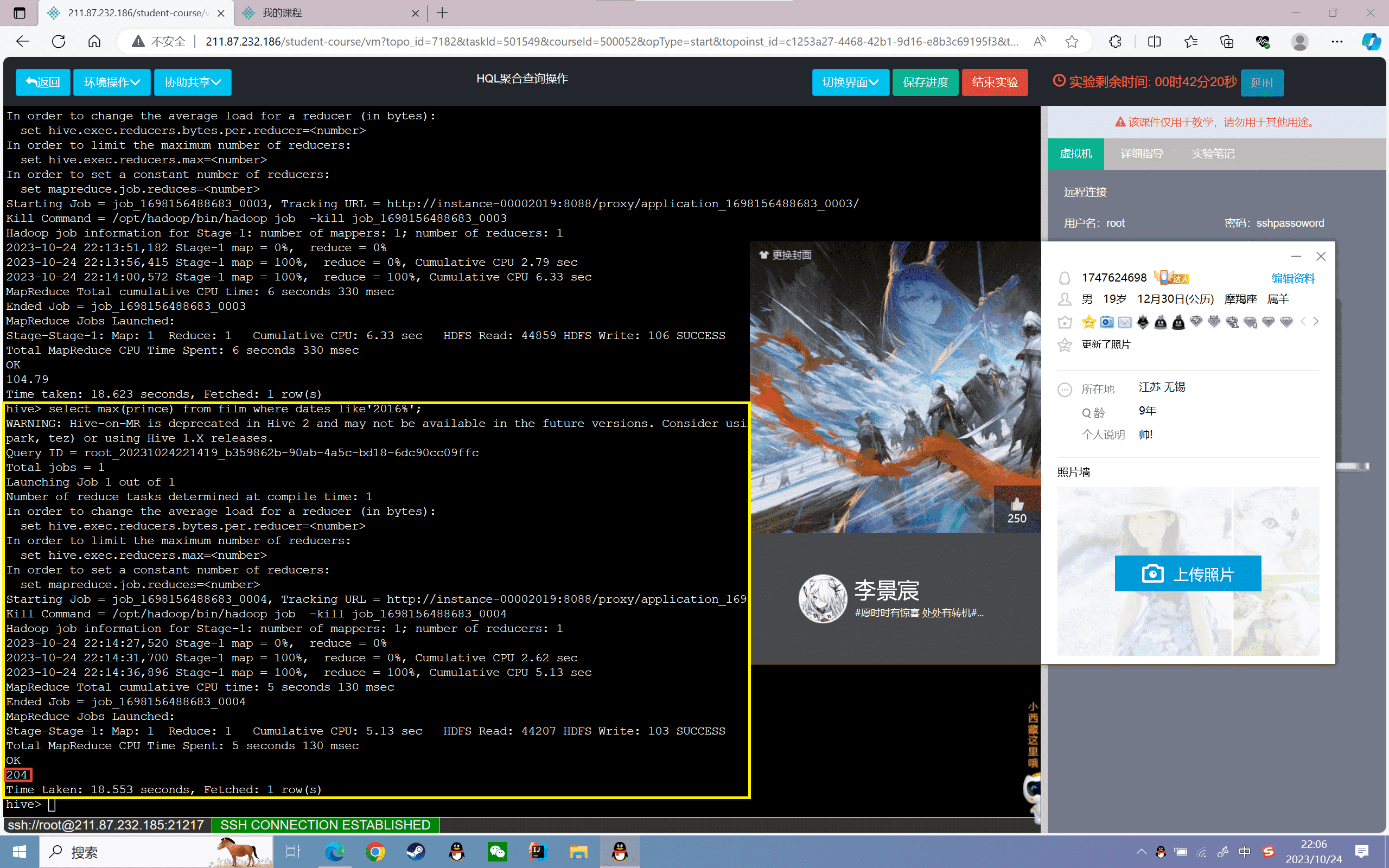
4、查询film表中2014年和2016年最低票房
1 | hive>select min(prince) from film where dates like'2014%' or dates like'2016%'; |
结果如下:
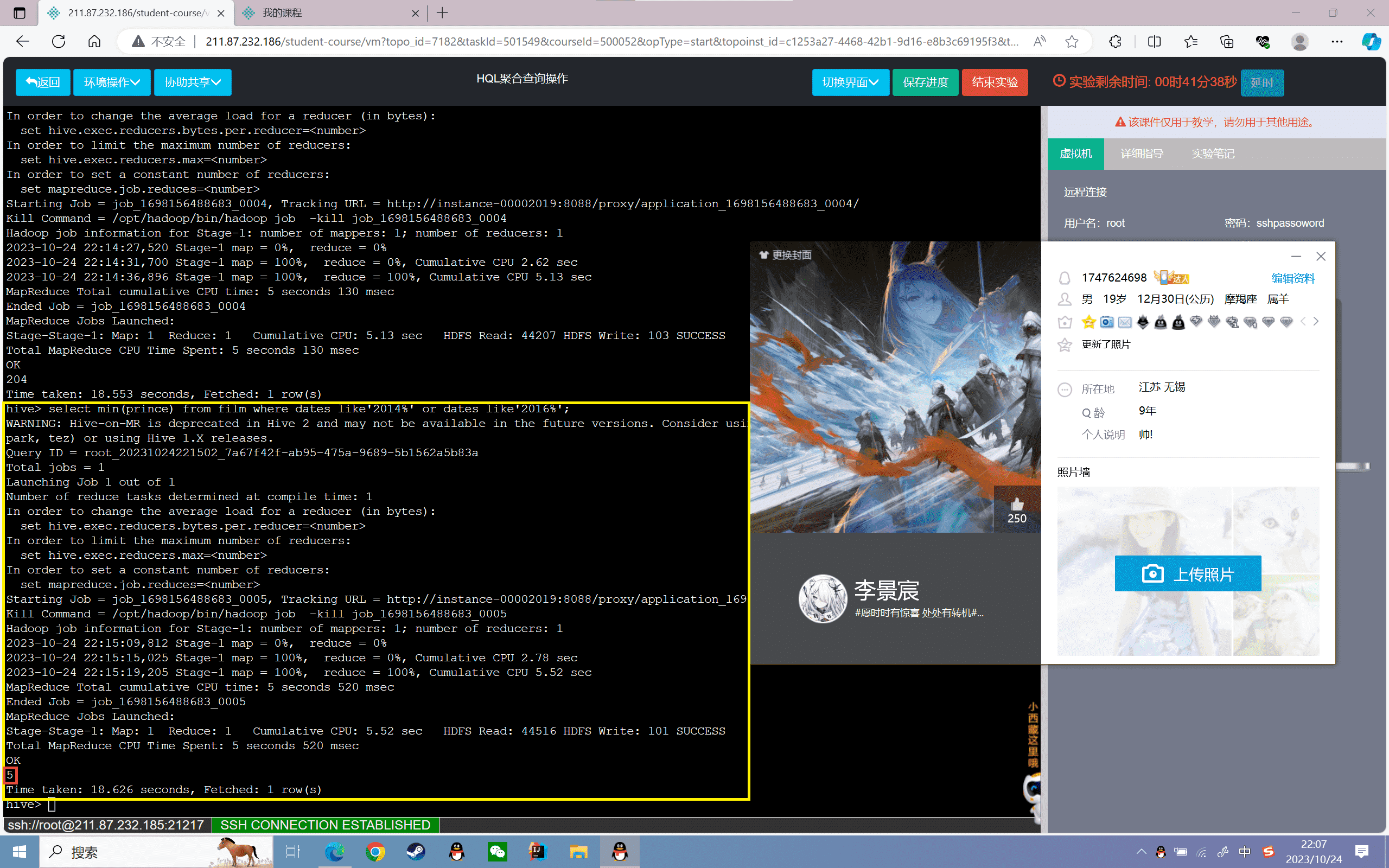
5、查询film表中票房前五的信息
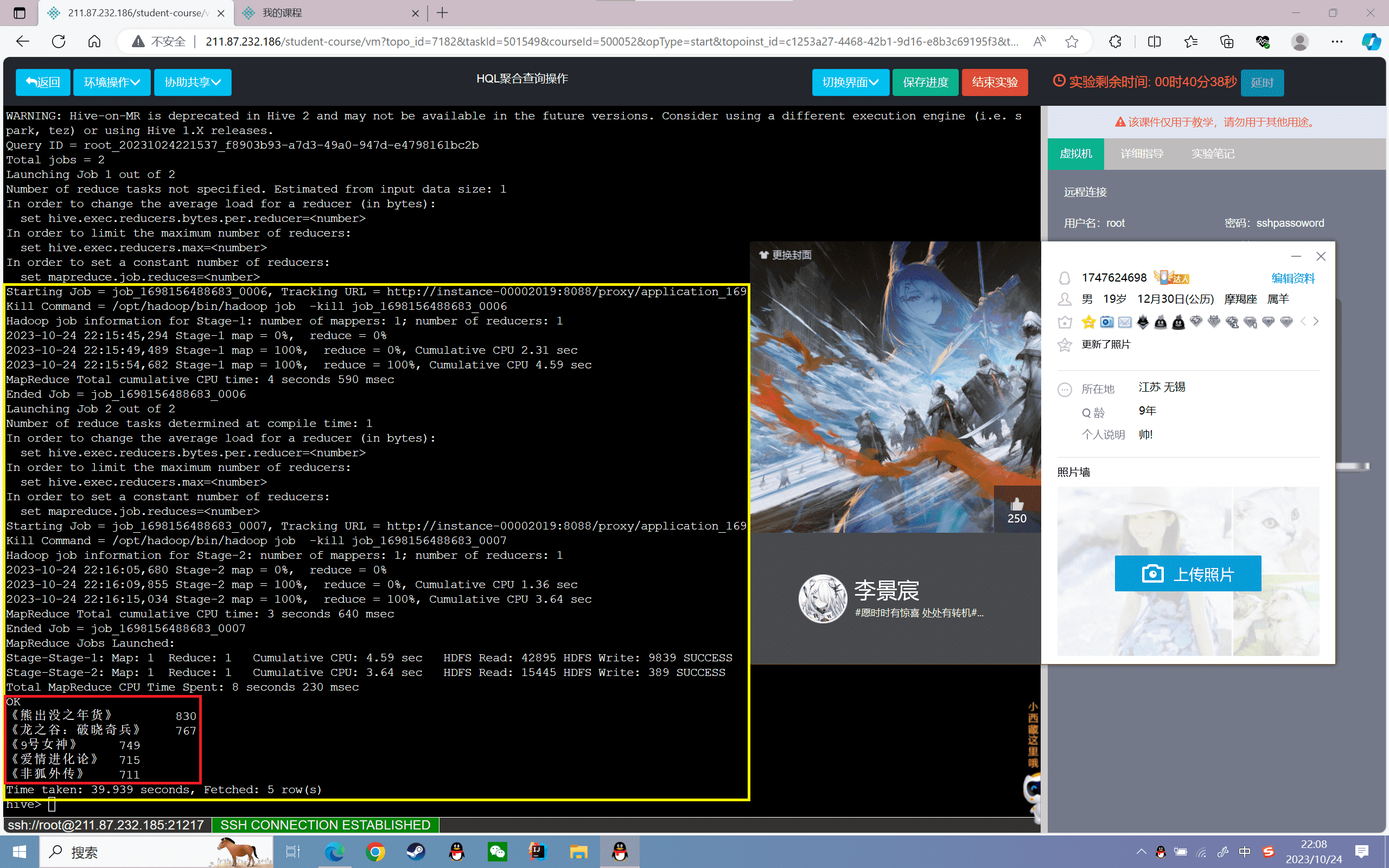
1 | hive>select name,sum(prince) p from film group by name order by p desc limit 5; |
结果如下:
6、查询film表中每部电影总票房大于700的电影信息
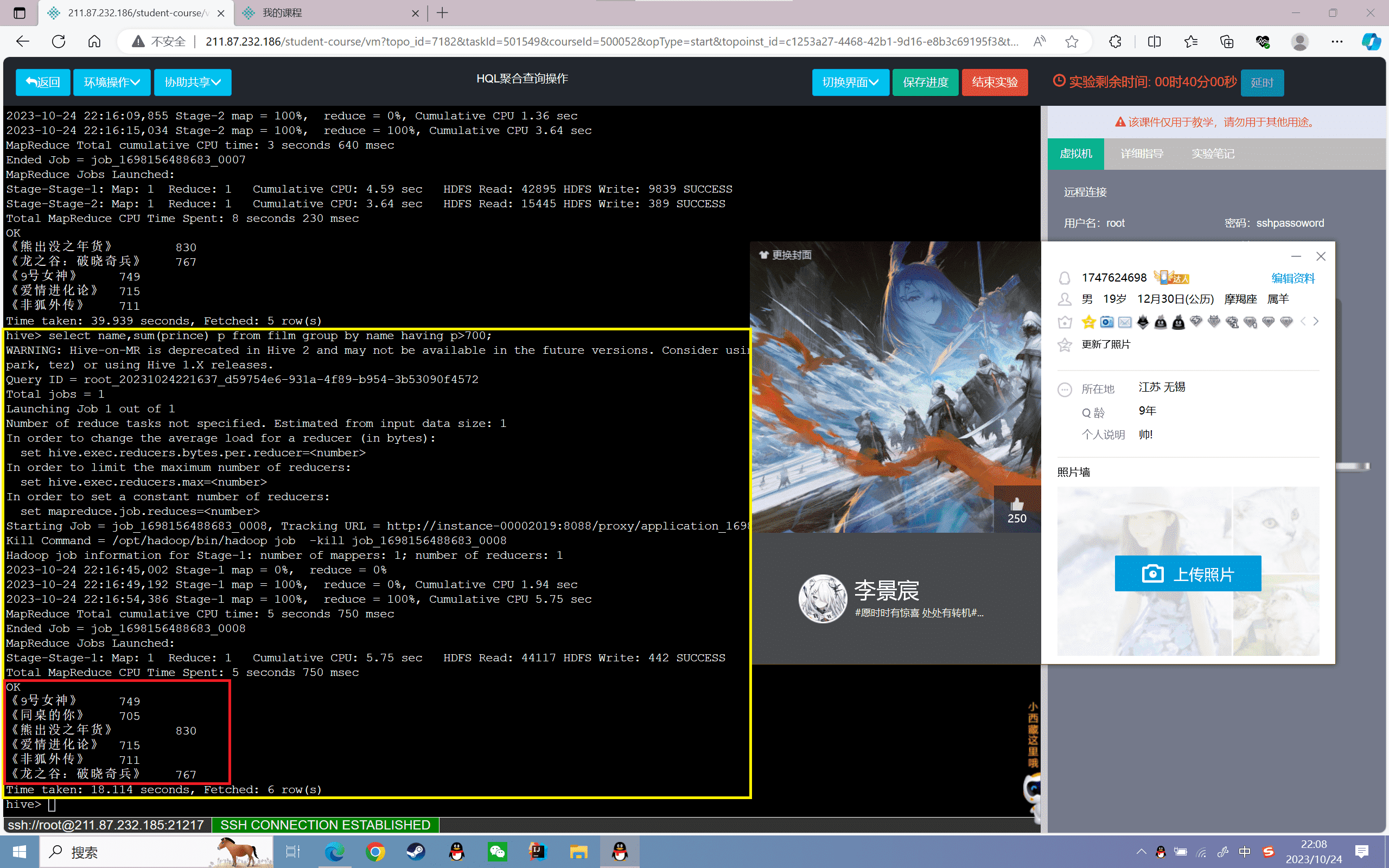
1 | hive>select name,sum(prince) p from film group by name having p>700; |
结果如下:
实验感悟
通过count()、avg()、max()、min()等聚合函数,我可以很方便地对Hive表进行统计分析,比如计算总数、平均值、最大最小值等。同时组合where子句,可以将运算限定在某个时间段或者条件内,使统计更有针对性。
另外,本实验还使用了group by进行分组,结合having子句筛选结果,这在SQL中是常见的聚合查询用法。以name分组并求和,然后having筛选总票房,实现了找出总票房前五的电影这样的效果。
此外,实验也让我对Hive运行机制有了更直观的感受,每次查询Hive都会跑一个MapReduce作业,因此查询会比较耗时。以后在编写Hive查询时,需要考虑优化,比如减少MR任务次数,采用合并小文件,增加map数等手段。
通过这个实验,我对Hive查询的理解更加深入,掌握了聚合函数的用法,以及与SQL类似的group by, having语法。这为后续进行更复杂的数据统计奠定了基础。我还需要继续学习join,rank等高级函数,以及提升Hive查询效率的方法。总而言之,这个实验达到了使用HQL进行聚合查询分析的目的,对提高我的数据分析能力很有帮助。通过count()、avg()、max()、min()等聚合函数,我可以很方便地对Hive表进行统计分析,比如计算总数、平均值、最大最小值等。同时组合where子句,可以将运算限定在某个时间段或者条件内,使统计更有针对性。
另外,本实验还使用了group by进行分组,结合having子句筛选结果,这在SQL中是常见的聚合查询用法。以name分组并求和,然后having筛选总票房,实现了找出总票房前五的电影这样的效果。
此外,实验也让我对Hive运行机制有了更直观的感受,每次查询Hive都会跑一个MapReduce作业,因此查询会比较耗时。以后在编写Hive查询时,需要考虑优化,比如减少MR任务次数,采用合并小文件,增加map数等手段。
通过这个实验,我对Hive查询的理解更加深入,掌握了聚合函数的用法,以及与SQL类似的group by, having语法。这为后续进行更复杂的数据统计奠定了基础。我还需要继续学习join,rank等高级函数,以及提升Hive查询效率的方法。总而言之,这个实验达到了使用HQL进行聚合查询分析的目的,对提高我的数据分析能力很有帮助。
实验 3.3
实验目的
掌握Hive的HQL多表查询操作
了解HQLJoin的几种常用连接方式
实验内容
1、启动Hadoop服务和Hive服务,并创建表数据
2、多表连接查询操作
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的多表联查:
通左连接(左边表中的数据优先全部显示)、右连接(右边表中的数据优先全部显示)、内连接(只显示符合条件的数据)、全连接(显示左右表中全部数据)等方式实现多个表的数据查询。
实验步骤
启动Hadoop服务和Hive服务,并创建表数据
1、启动Hadoop
2、进入hive安装目录,打开hive
3、创建表
创建员工信息表“employee”,分为员工名称、职务、入职日期、工资、绩效、部门编号五个字段,数据格式以“,”分割:
1 | hive> create table employee(name string,job string,hiredate string,salary int,commission double,deptid int) row format delimited fields terminated by ','; |
创建部门表“department”,分为部门编号、部门、所在城市三个字段,数据格式以“,”分割:
1 | hive> create table department(deptid int,position string,location string) row format delimited fields terminated by ','; |
4、导入数据
将本地的employee.csv和department.csv文件数据加载到employee表和department表:
1 | hive> load data local inpath '/data/dataset/employee.csv'into table employee;hive> load data local inpath '/data/dataset/department.csv'into table department; |
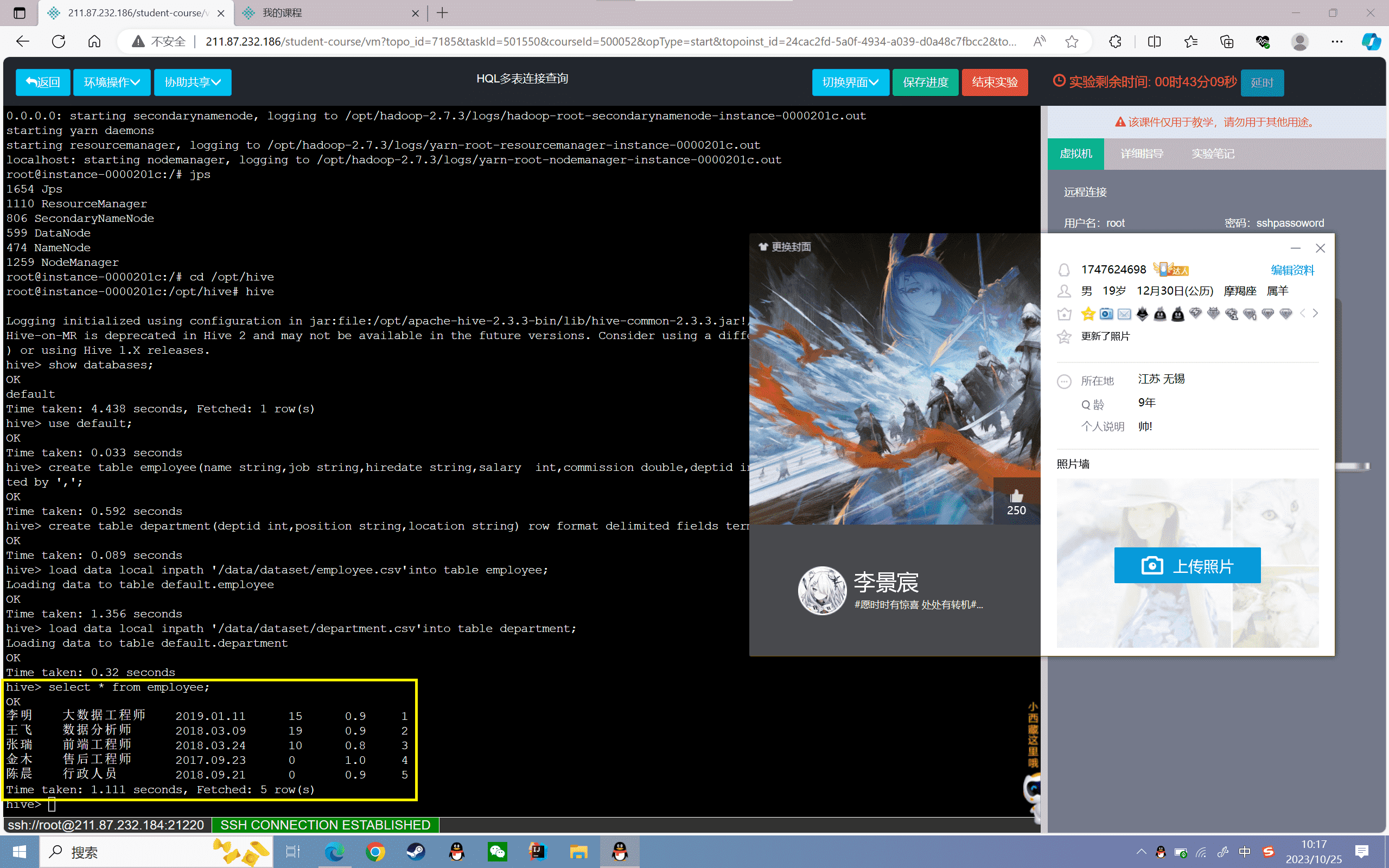
5、查看导入表的数据:
1 | hive> select * from employee; |
1 | hive> select * from department; |
5.2、多表连接查询操作
1、查询员工姓名和部门
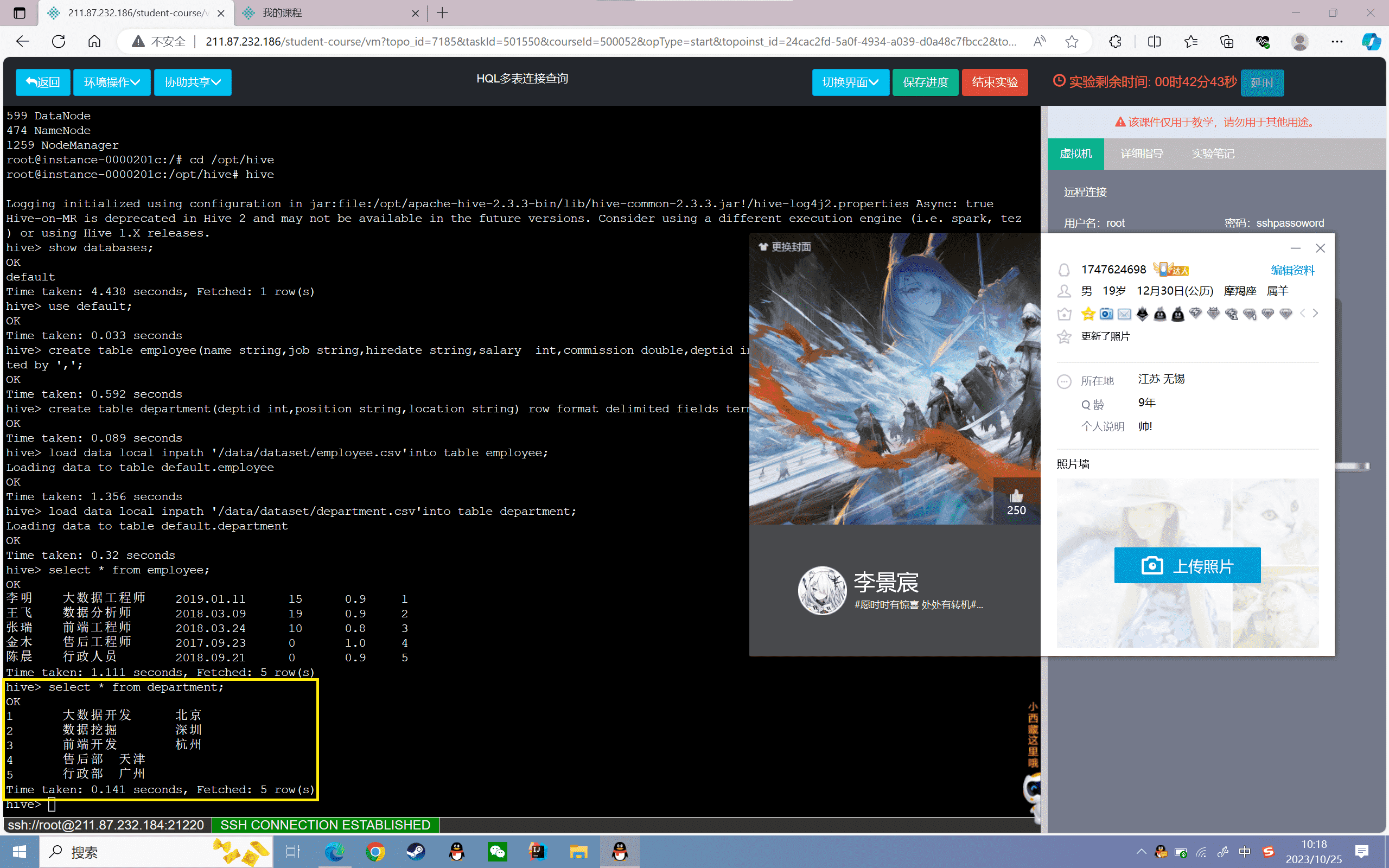
因为员工姓名和部门分别在两个表中,所以需要使用两表联查,使用“join”,其中员工表为主表
1 | hive>select e.name, d.position from employee e join department d on e.deptid=d.deptid; |
结果如下:
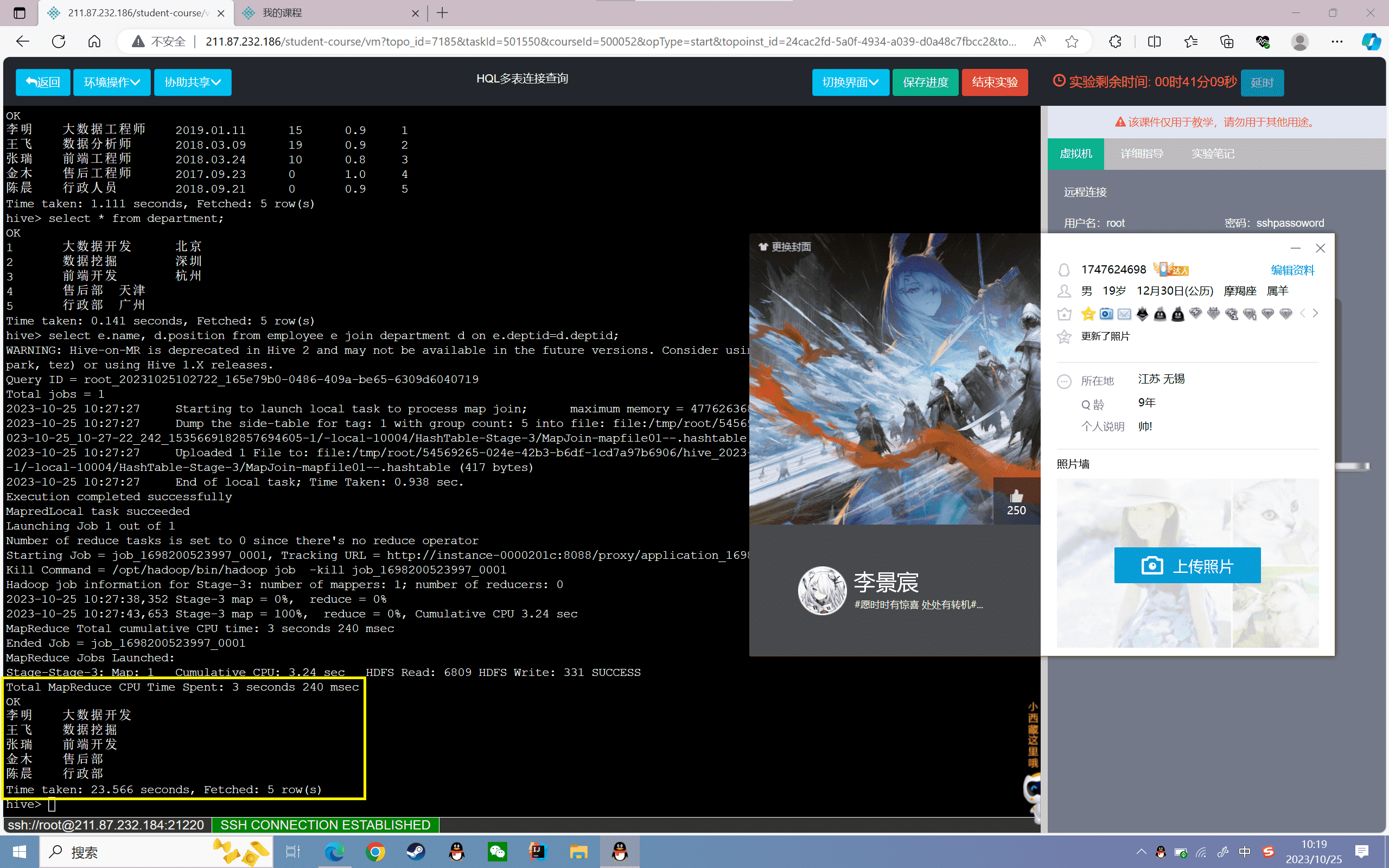
2、查询员工姓名、部门和所在地区,其中“员工信息表”为主表
1 | hive>select e.name, d.position, d.location from employee e left join department d on e.deptid=d.deptid; |
结果如下:
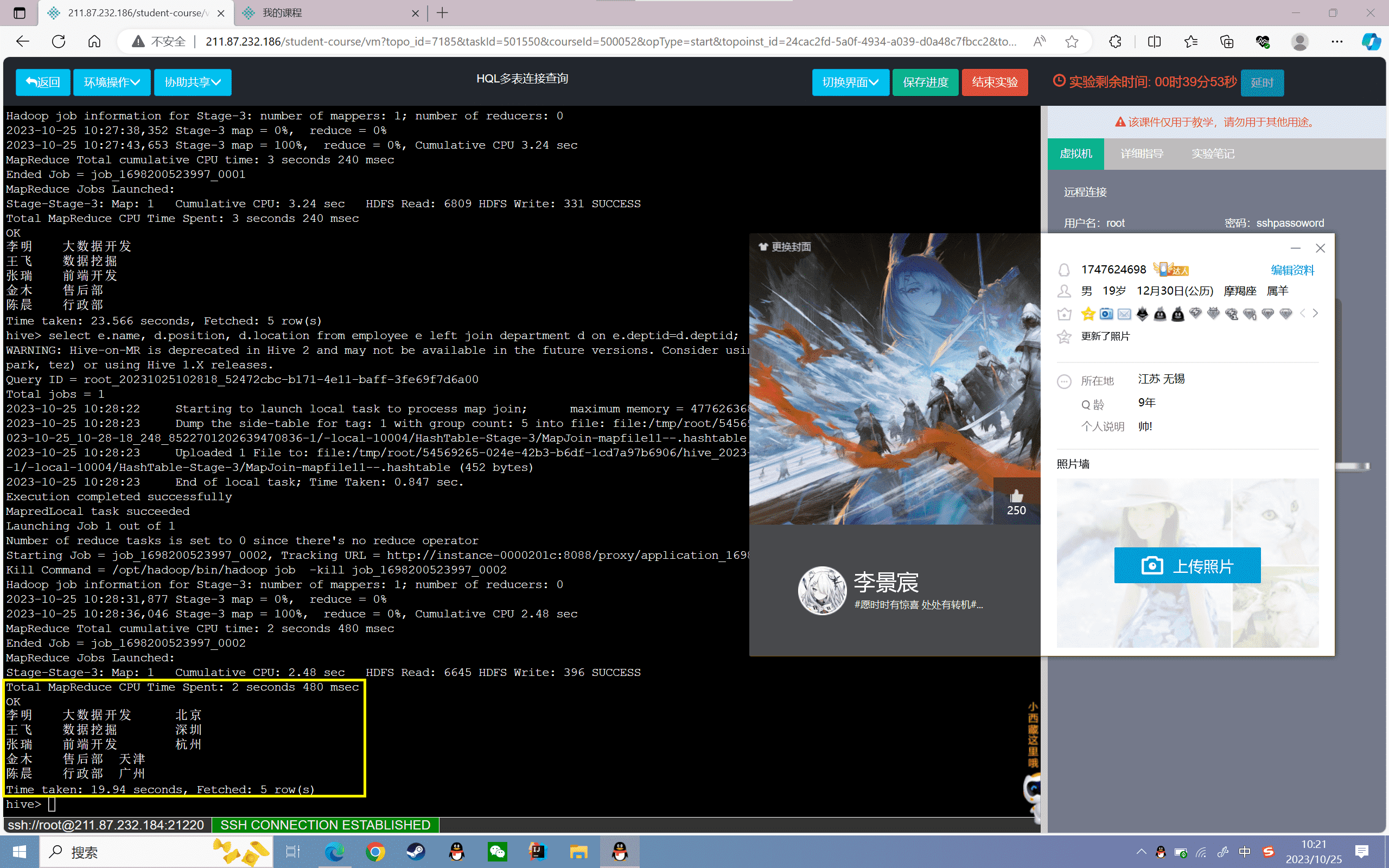
3、查询员工姓名、部门和入职日期,其中“员工信息表”为主表
1 | hive>select e.name, d.position, e.hiredate from department d right join employee e on e.deptid=d.deptid; |
结果如下:
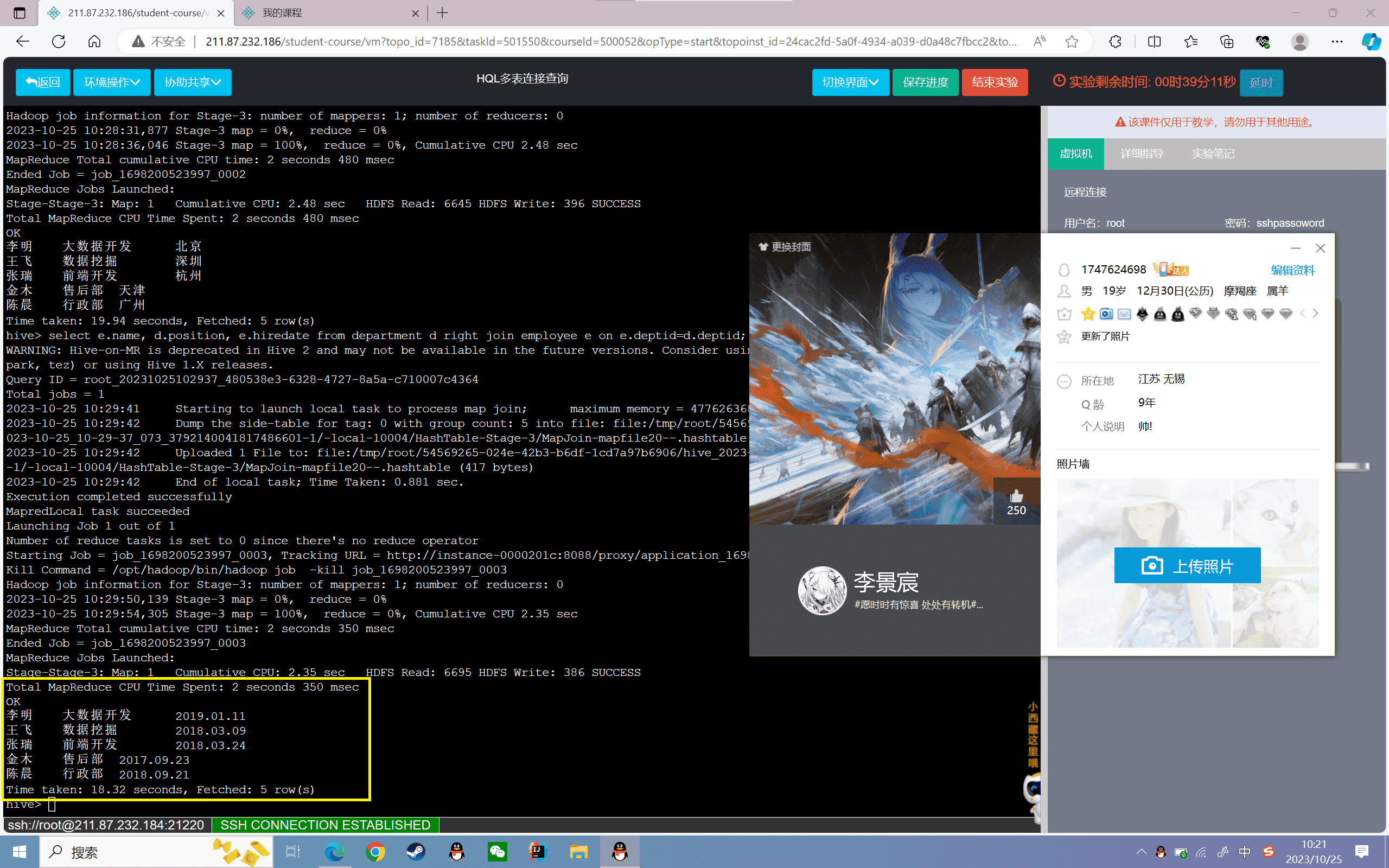
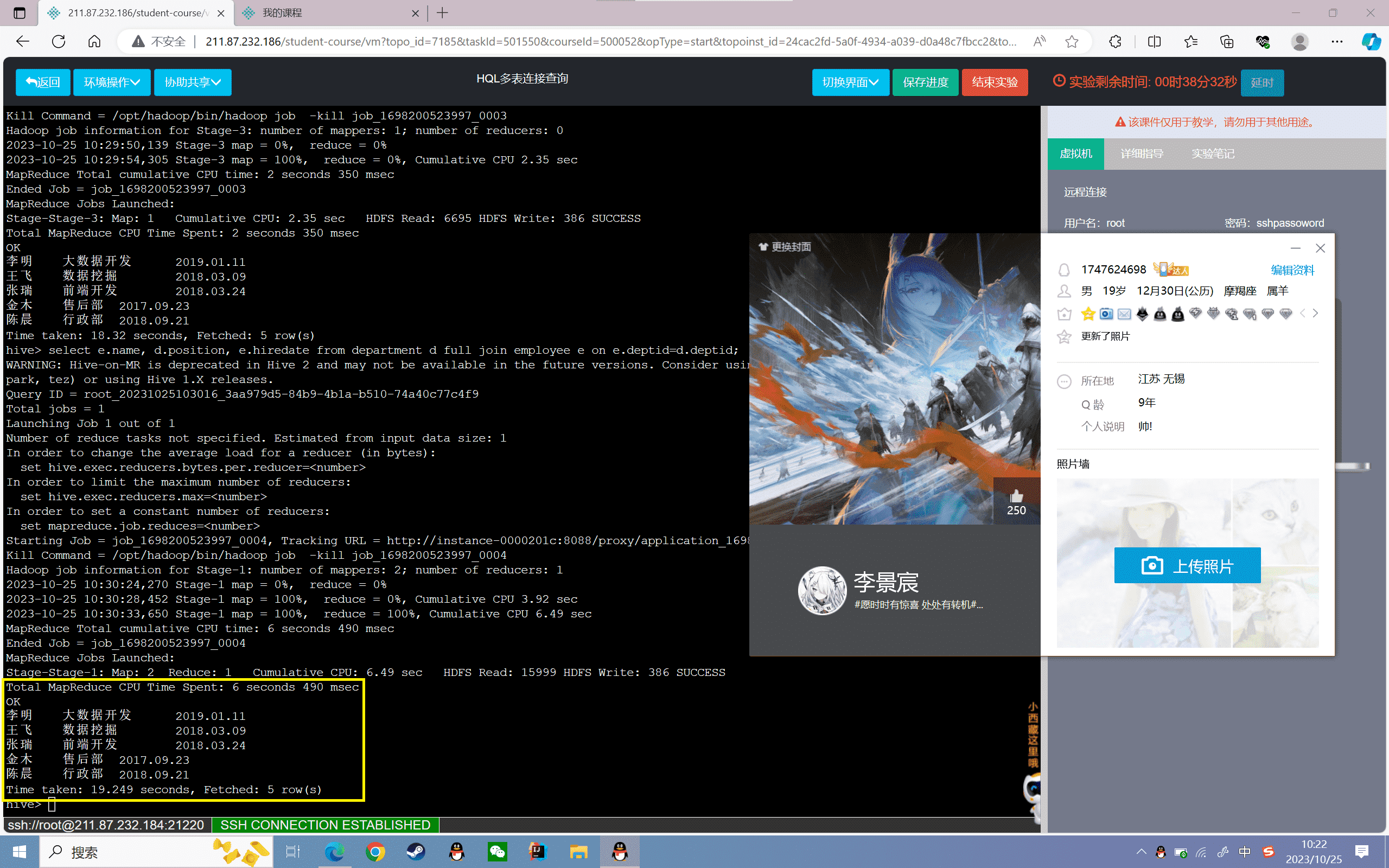
4、查询员工姓名、职务和入职日期,其中“员工信息表”为主表
1 | hive>select e.name, d.position, e.hiredate from department d full join employee e on e.deptid=d.deptid; |
结果如下:
六、实验感悟
实验中,我创建了两个表employee和department,分别代表员工信息和部门信息。两个表通过deptid字段建立关系。然后通过join对两个表进行连接,实现了查询员工姓名及其所在部门等功能。
join连接可以指定不同的连接方式,如内连接仅显示符合连接条件的结果,左连接会将左边表全部显示出来,右连接则会将右边表全部显示。所以我们可以根据需求选择不同的连接方式。
另外,在join查询时需要指定连接条件on从句,这对保证查询正确非常关键。on从句也体现了关系型数据库的设计思想,两个表通过主外键建立连接。
通过本实验,我掌握了Hive的join多表连接的使用,理解了不同join连接方式的区别,以及join的查询语法。掌握join连接对实现关系型数据分析是非常重要的。后续还需要学习更复杂的连接查询,以及join的优化方法。总体上,本实验达到了练习Hive多表联查的目的,使我对Hive查询的理解更上一层楼。
实验 3.4
实验目的
掌握Hive的HQL常用的查询结果存储方法
实验内容
1、启动Hadoop服务和Hive服务,并创建表数据
2、HQL查询结果存储
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3.3、Hadoop-2.7.3
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Hive的查询结果处理:
1、存储到Hive的新建数据表中,将查询的结果保存到新建的表中,如果查询成功保存表中,查询失败,则表不会创建
2、存储到HDFS或者本地上,直接将hive查询的结果保存到指定的路径下。
实验步骤
启动Hadoop服务和Hive服务,并创建表数据
1、启动Hadoop:
1 | start-all.sh |
2、进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,如下图所示
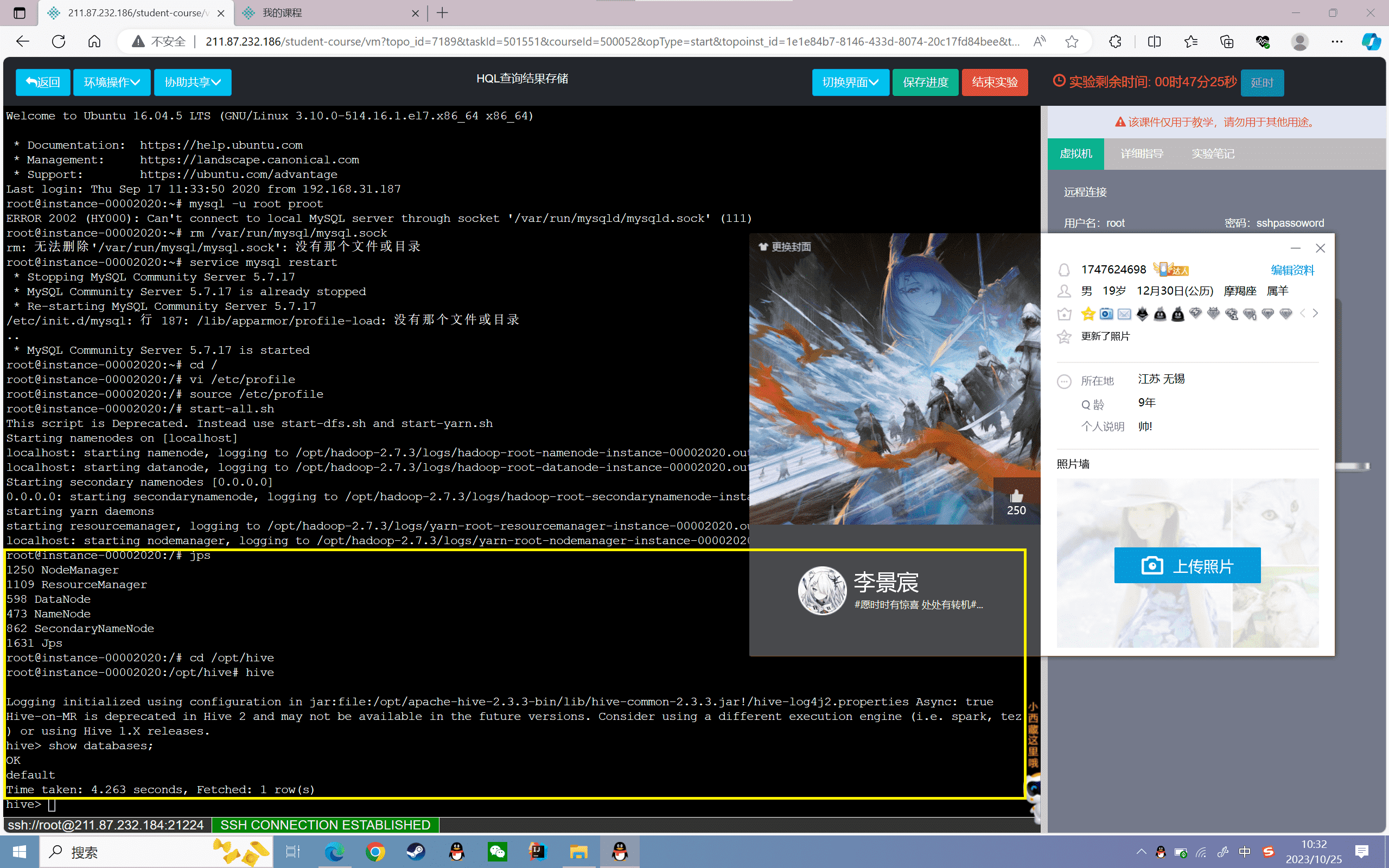
3、创建表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | hive> create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
4、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | hive> load data local inpath '/data/dataset/film_log3.log'into table film; |
5、查看film表数据的前十条:
1 | hive> select * from film limit 10; |
结果如下:
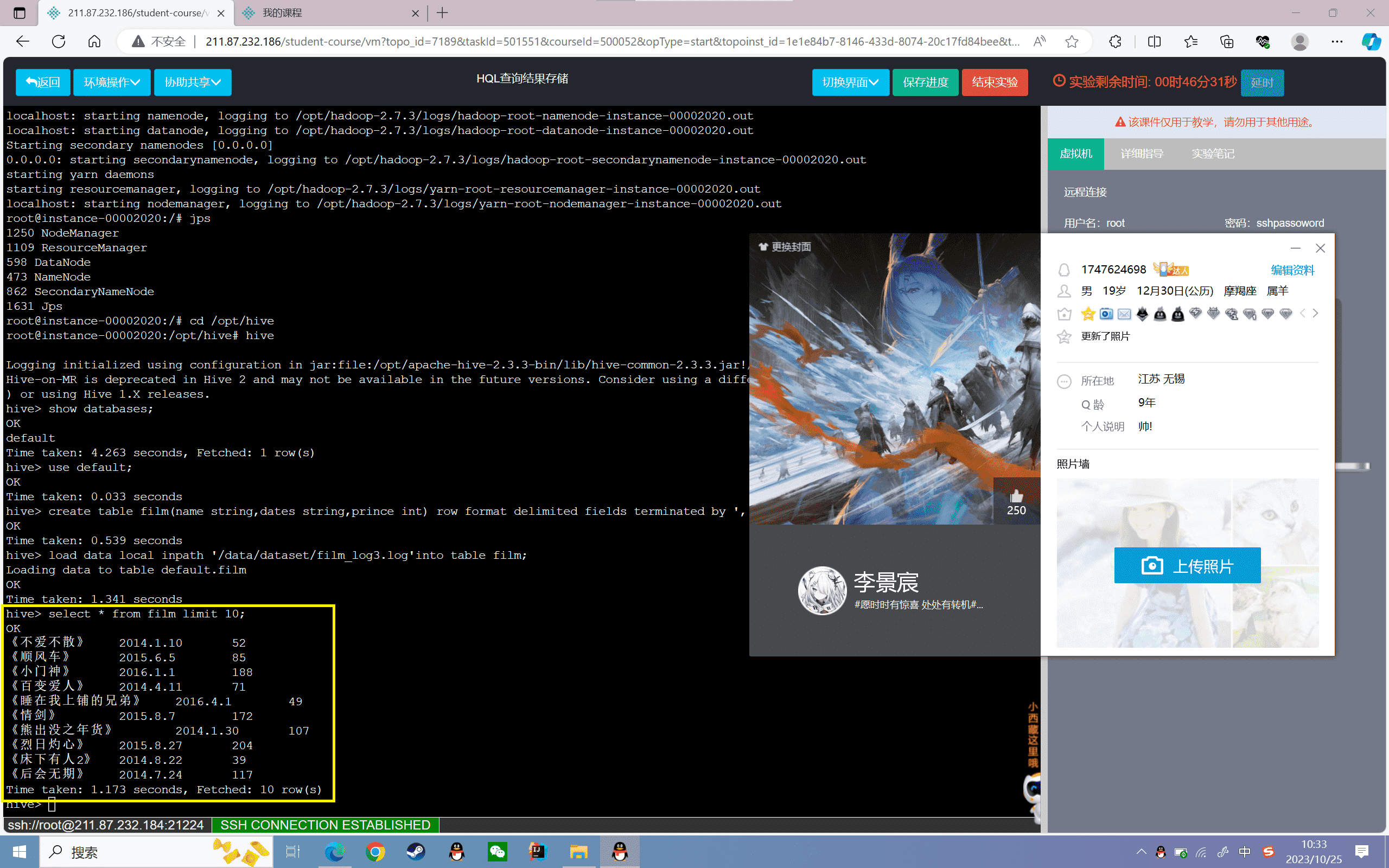
HQL查询结果存储
1、查询2014年所有票房信息并将结果存储到新表“film_2014”中
1 | hive>create table film_2014 as select * from film where dates like'2014%'; |
查看存储表内的前10条信息
1 | hive> select * from film_2014 limit 10; |
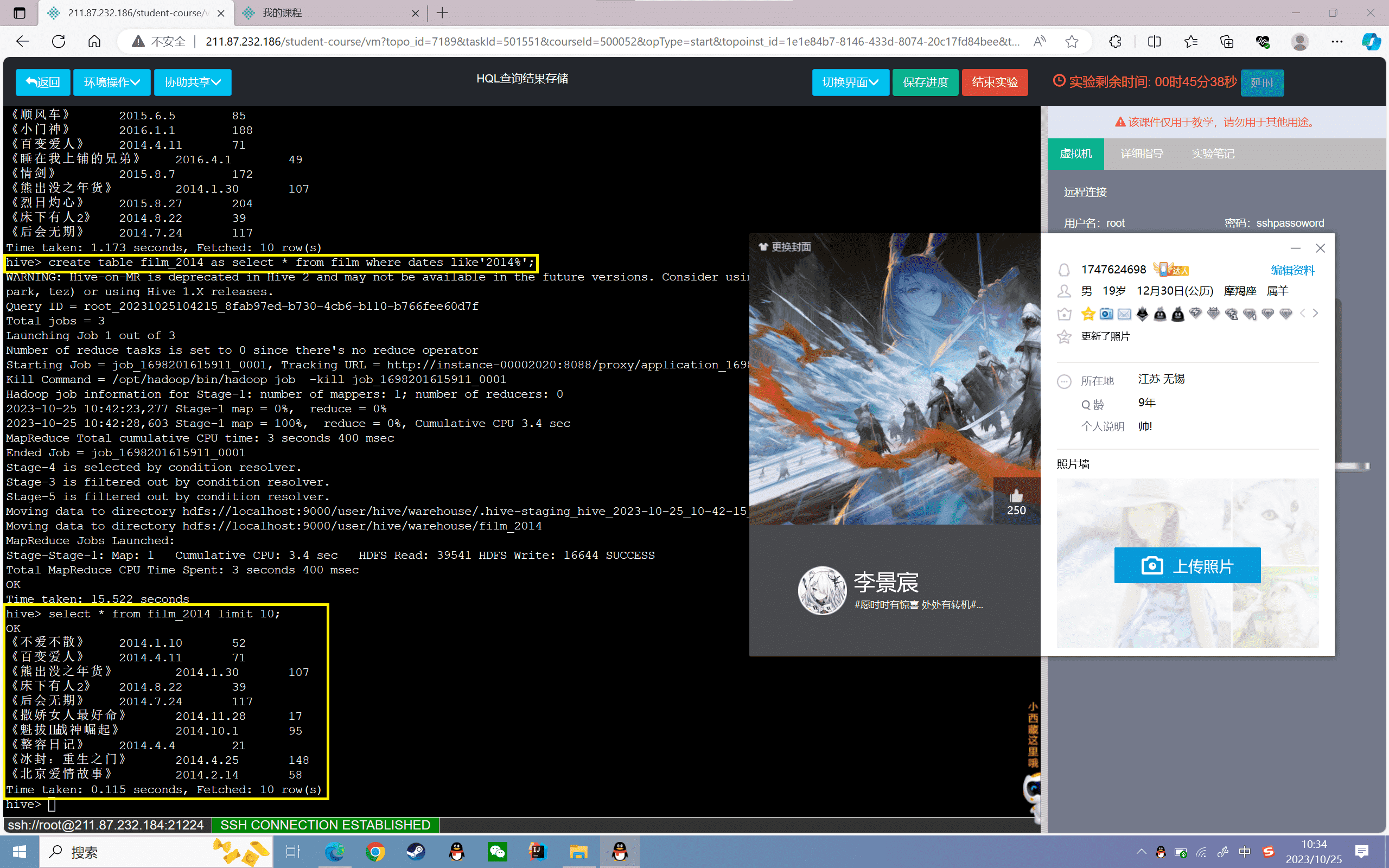
2、将2015年票房前十数据存储到linux下的“/data/result”目录下
1 | hive>insert overwrite local directory'/data/result'select name,sum(prince) p from film where dates like'2015%' group by name order by p desc limit 10; |
查看文件夹下的数据信息
1 | root@localhost:~# cat /data/result/000000_0 |head -10 |
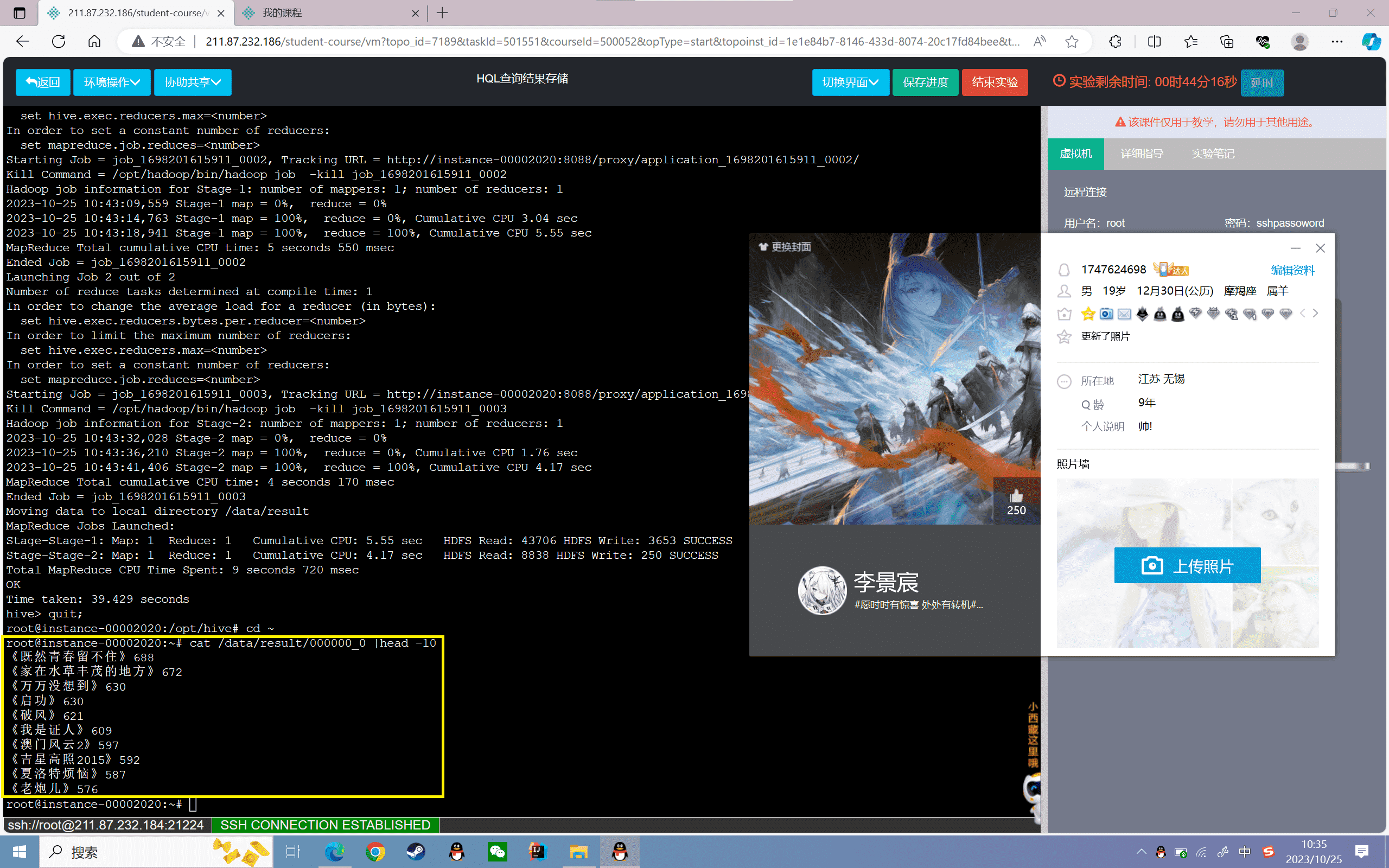
3、查询film表中2014年的所有电影平均票房,并存到HDFS的“/result”目录下
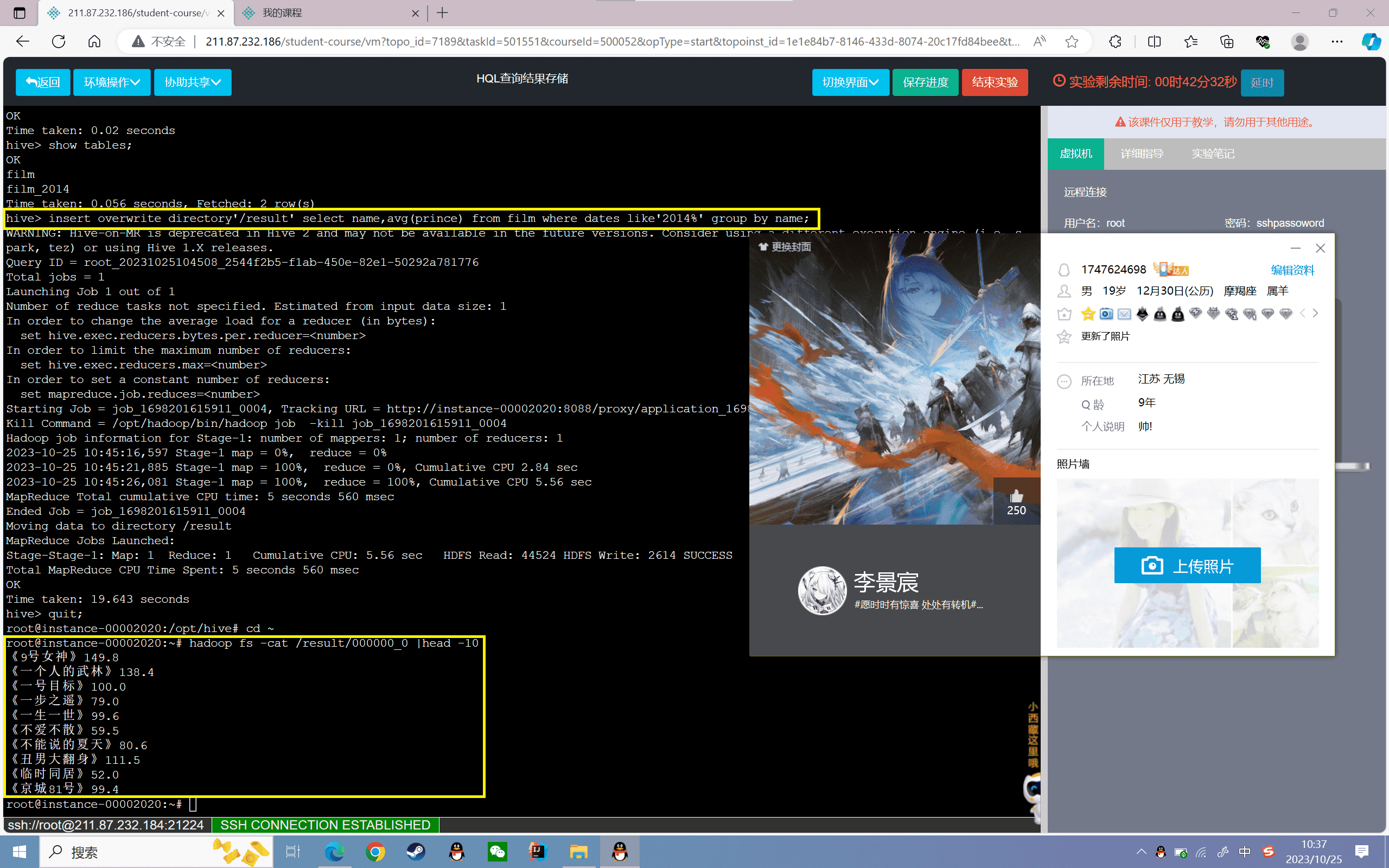
1 | hive> insert overwrite directory'/result' select name,avg(prince) from film where dates like'2014%' group by name; |
查看HDFS文件夹下的数据信息
1 | root@localhost:~# hadoop fs -cat /result/000000_0 |head -10 |
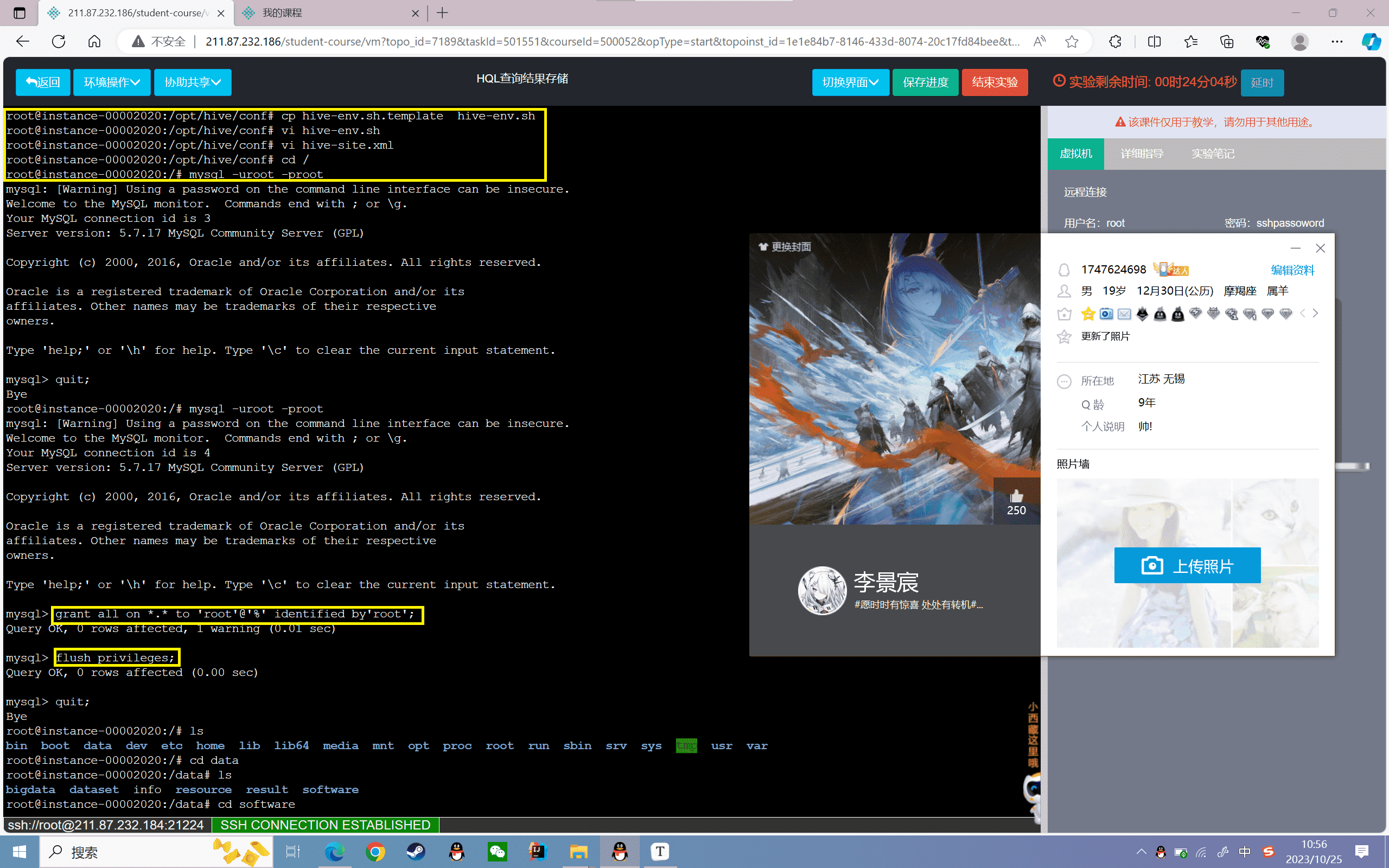
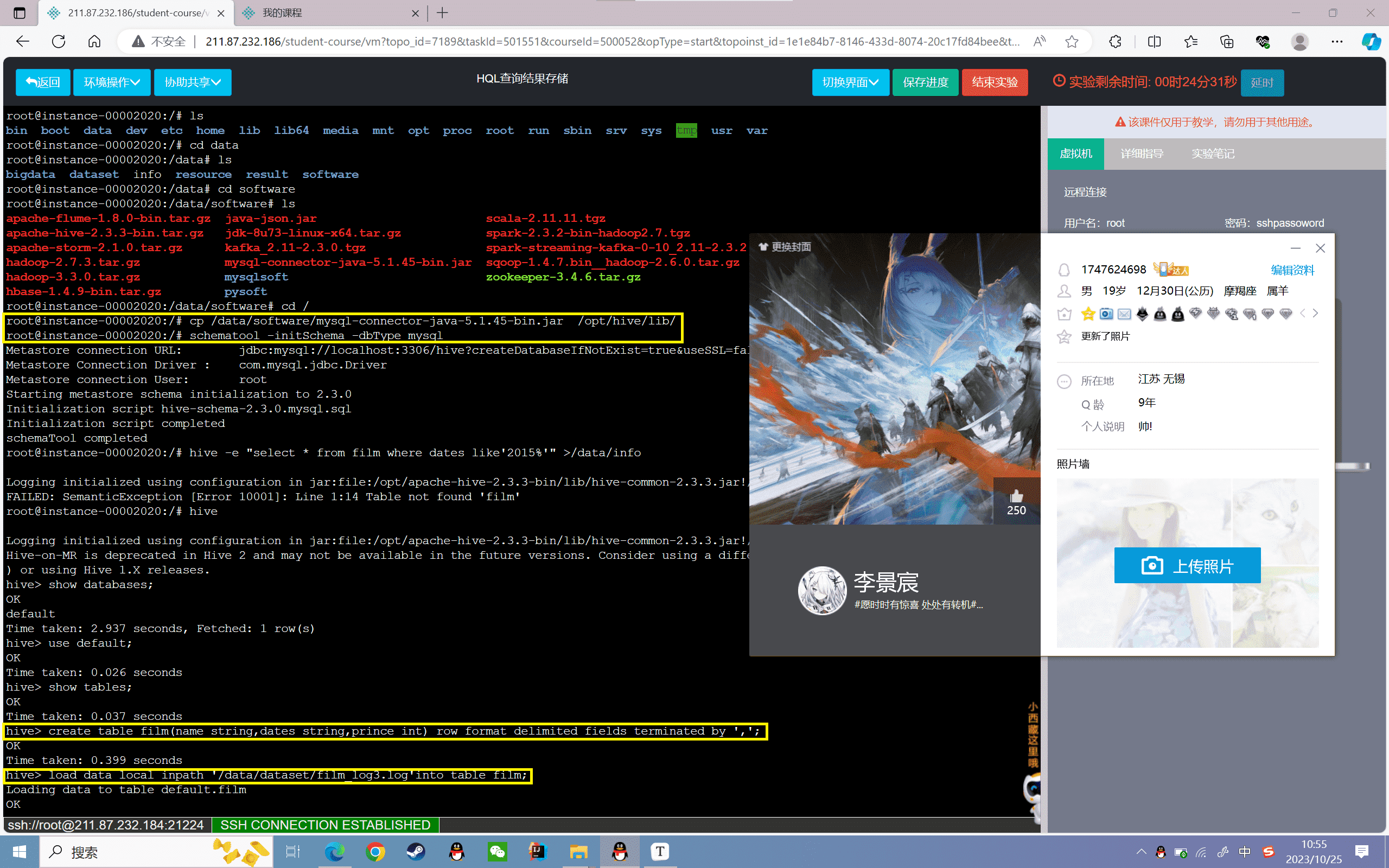
4、查询2015年的电影信息,并存储到本地/data/info文件下
首先进行hive的本地化配置,并重新导入film数据集,详细过程见实验一
1 | root@localhost:~# hive -e "select * from film where dates like'2015%'" >/data/info |
查看文件的数据信息
1 | root@localhost:~# cat /data/info |head -10 |
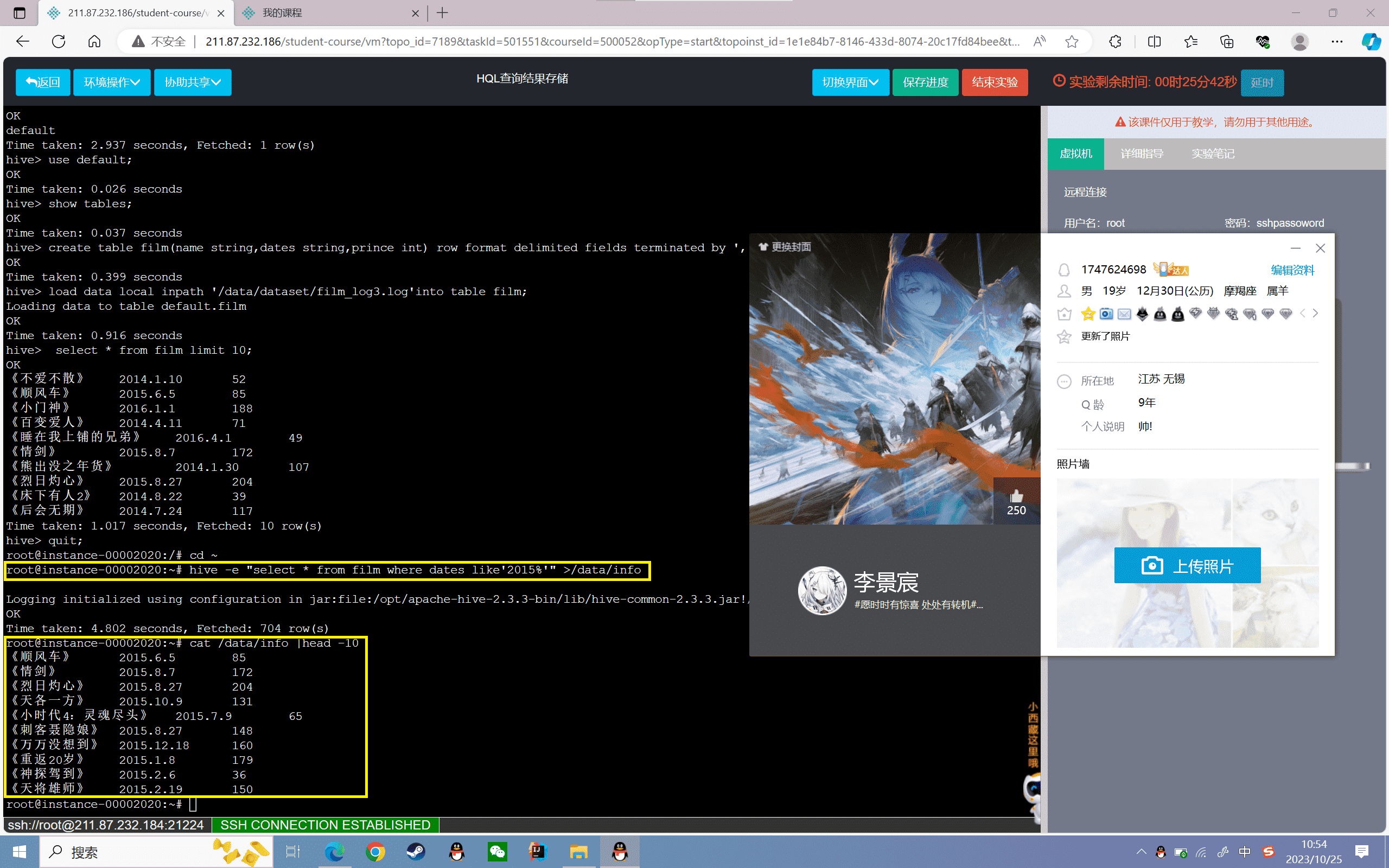
实验感悟
实验中,我运用了create table as和insert overwrite两种语法将查询结果存为新表。前者如果查询成功则创建新表,失败则不创建;后者无论成功失败都会覆盖目标表/目录。
然后我使用insert overwrite将查询结果存储到本地文件系统和HDFS指定目录下。对本地系统需要指定local关键字,HDFS系统直接指定HDFS路径即可。
保存查询结果的好处是避免每次都要重新执行复杂的查询语句,提高查询效率。我也注意到Hive默认查询结果存储在HDFS的临时目录下,可能被删除,所以保存查询结果是非常必要的。
通过本实验,我掌握了Hive的查询结果保存方法,可以将经过筛选、JOIN、统计后的结果进行持久化存储,作为后续分析使用。此外,保存查询结果到外部也有利于和其他工具连接,进行更复杂的分析处理。总之,本实验达到了学习Hive查询结果存储的目的,使我可以灵活地进行数据分析。
实验 4
实验目的
了解JDBC的原理
掌握Hive JDBC API的使用
实验内容
1、配置环境并启动Hadoop和hiveserver2服务
2、启动IntelliJ Idea并创建Java项目
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3、Hadoop-2.7
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
连接Hive的代码:
forName():通过该方法可以加载HiveServer2 JDBC的驱动程序
getConnection(URL,username,password):通过该方法可以创建JDBC的驱动程序,用来连接Hive。参数URL,jdbc:hive2://ip:port/数据库;参数username,用户名;参数password,密码。
实验步骤
配置环境并启动Hadoop和hiveserver2服务
1、修改hadoop配置文件core-site.xml
1 | vi /opt/hadoop/etc/hadoop/core-site.xml |
添加如下属性:
1 | <property> |
2、启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
1 | root@localhost:~# jps8423 SecondaryNameNode8712 NodeManager8072 NameNode8203 DataNode9036 Jps8588 ResourceManager |
3、启动hiveserver2服务
1 | cd /opt/hive/./bin/hiveserver2 |
启动IntelliJ Idea并创建Java项目
1.启动IntelliJ Idea。在终端窗口下,执行以下命令:
1 | cd /opt/idea-IC-191.7479.19/bin$ ./idea.sh |
2.在idea中创建Java项目,依次选择“Create New Project->java->next->next”,并命名为”hive_jdbc”,最后选择“Finish”,其它都默认即可。
3.Hive程序开发和运行,需要依赖Hive相关的jar包。
先将所需的hadoopjar包拷贝到hive的lib下
1 | cp /opt/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar /opt/hive/lib/ |
依次选择”File->Project structure…”菜单项,进入项目结构界面,手动导入Hive的jar包到项目中。如下图所示:
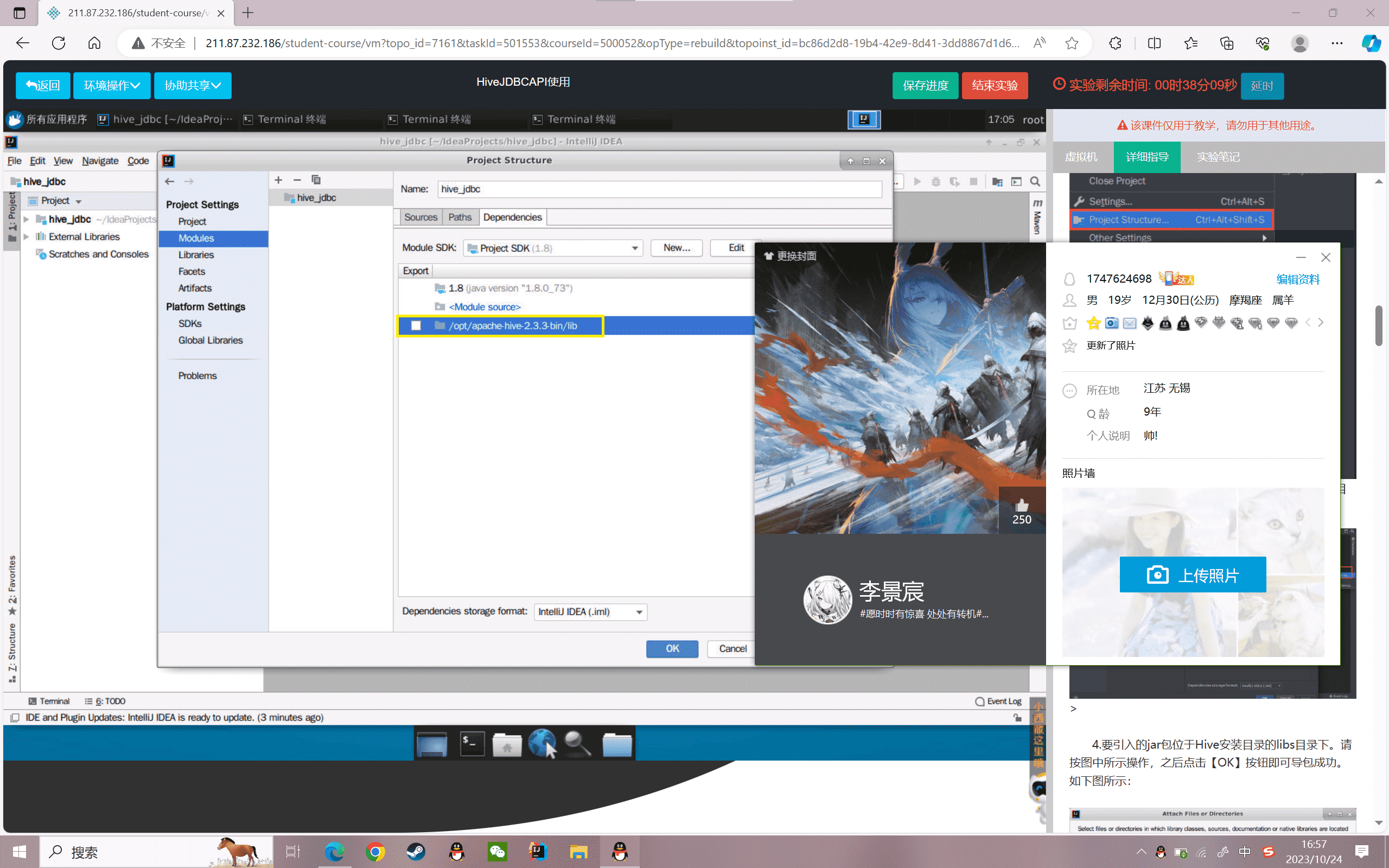
4.要引入的jar包位于Hive安装目录的libs目录下。请按图中所示操作,之后点击【OK】按钮即可导包成功。
5.查看成功导入的部分jar包。如下图所示:
编写Hive API使用代码
1.选中项目”hive_jdbc”的src目录上,单击右键,依次选择”New->Java Class”,创建Java类。如下图所示:
2.在弹出的对话框中,命名”HiveAPI”,并选择”class”类型。
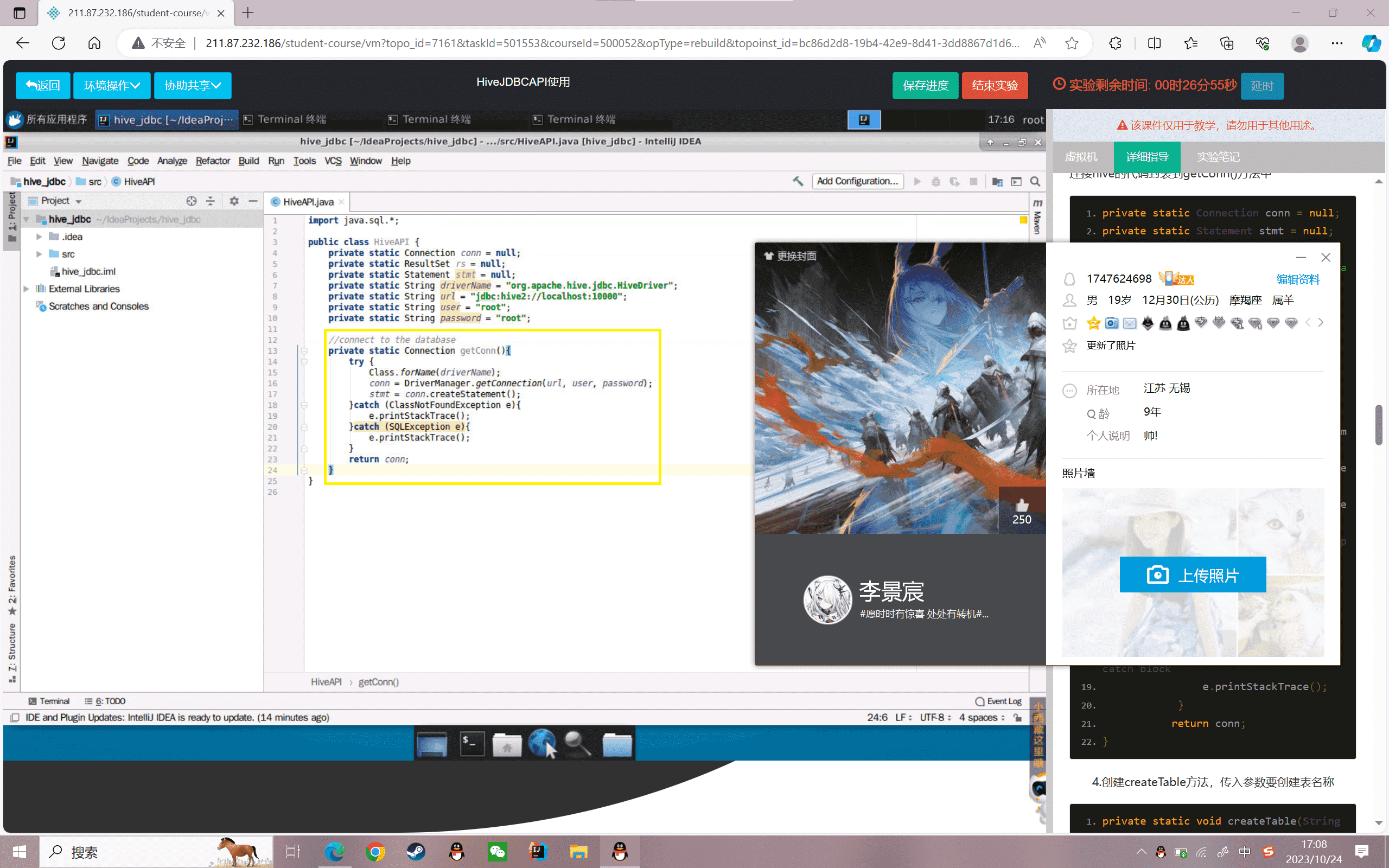
3.创建getConn()方法,连接Hive的远程客户端,将连接hive的代码封装到getConn()方法中
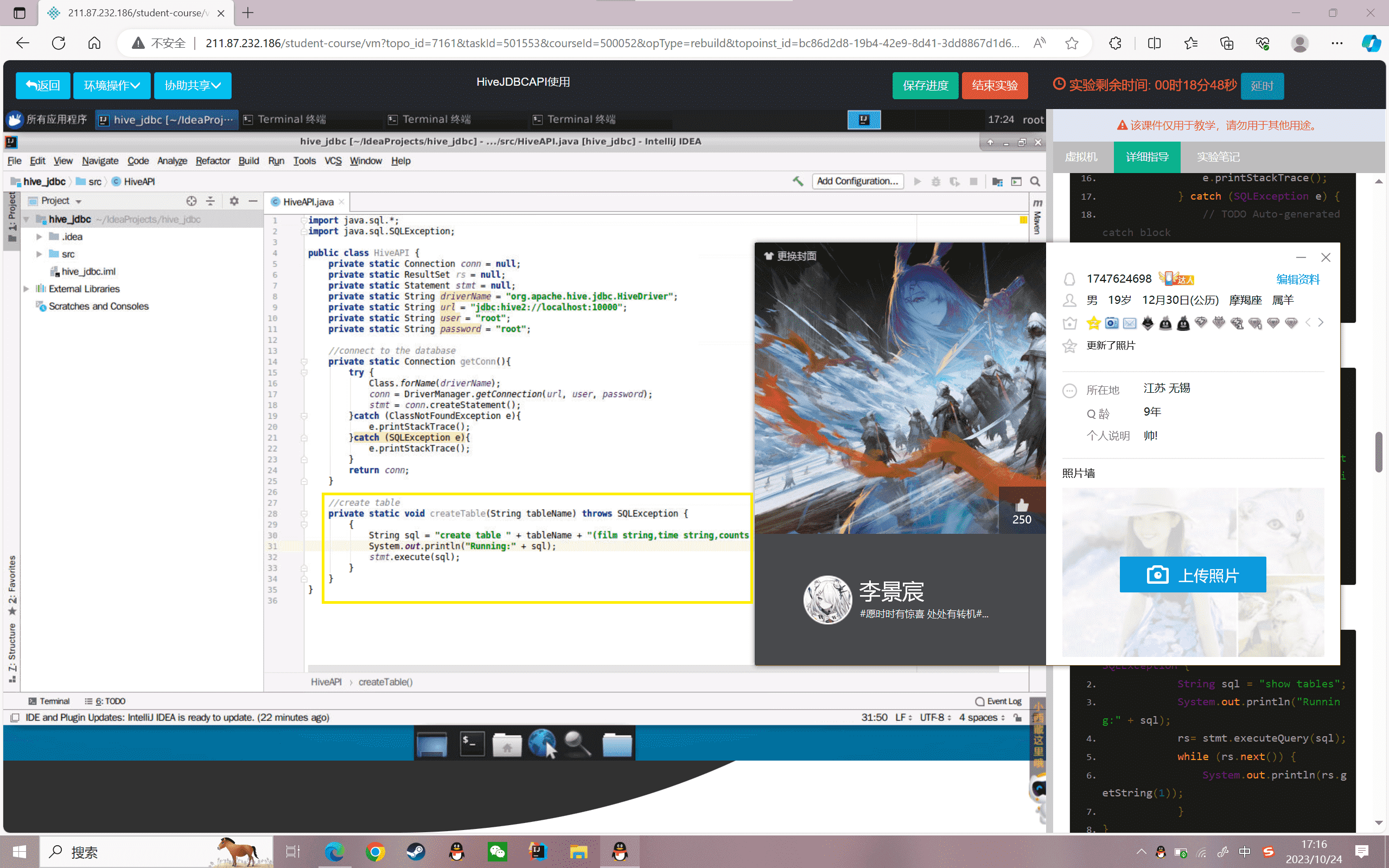
4.创建createTable方法,传入参数要创建表名称
5.创建showTables方法,输出所有的表名称
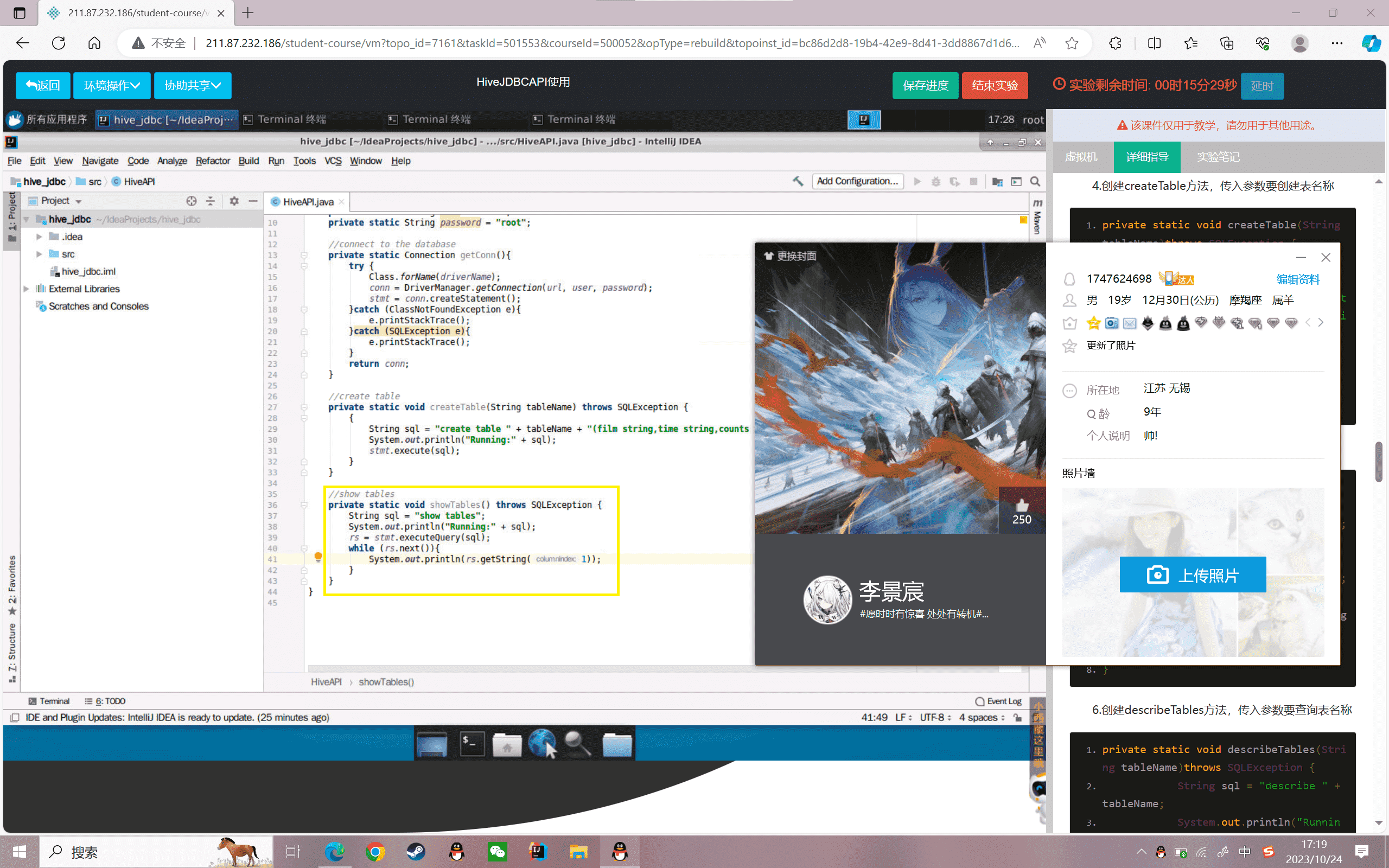
6.创建describeTables方法,传入参数要查询表名称
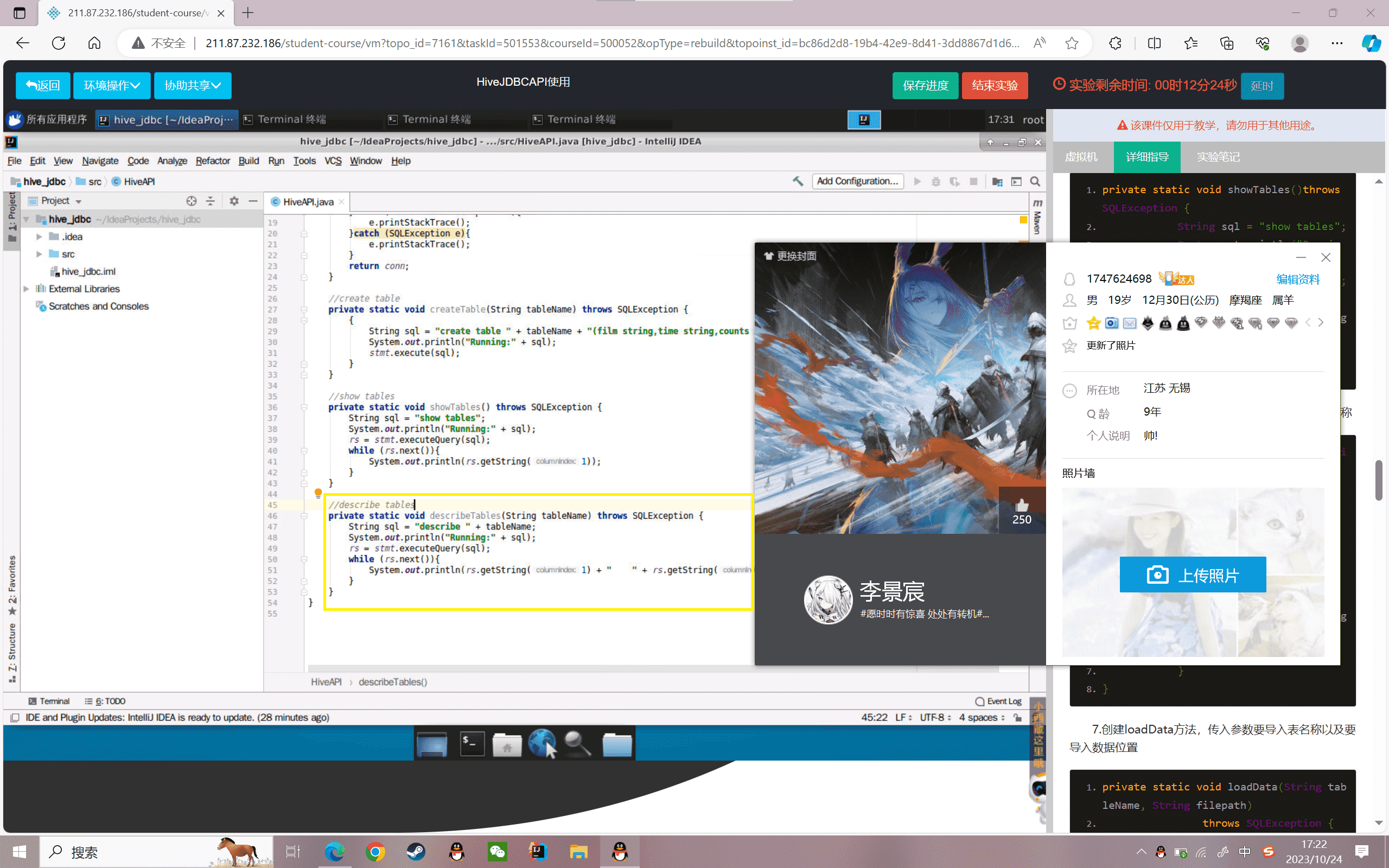
7.创建loadData方法,传入参数要导入表名称以及要导入数据位置
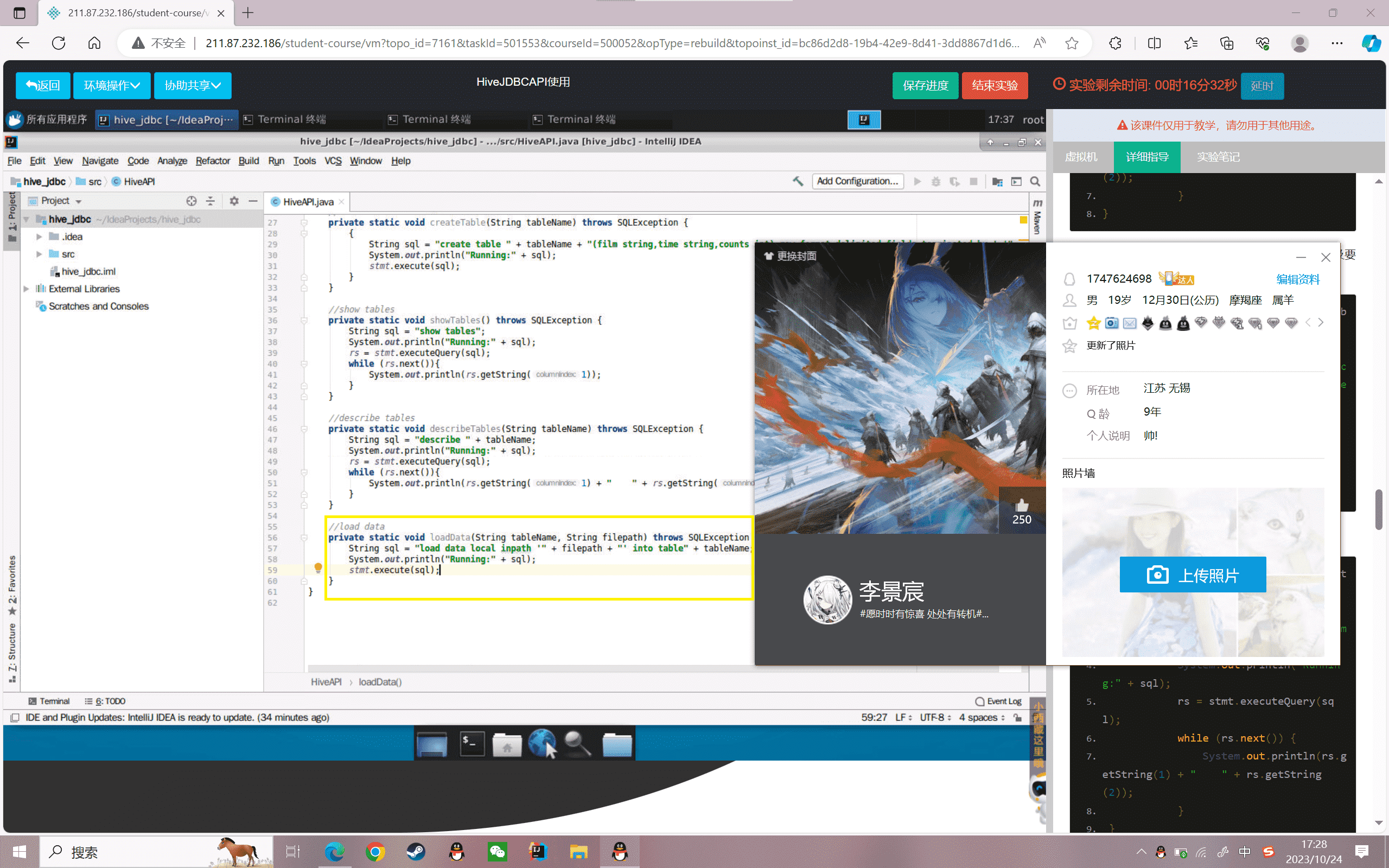
8.创建selectData方法,传入参数要查询表名称
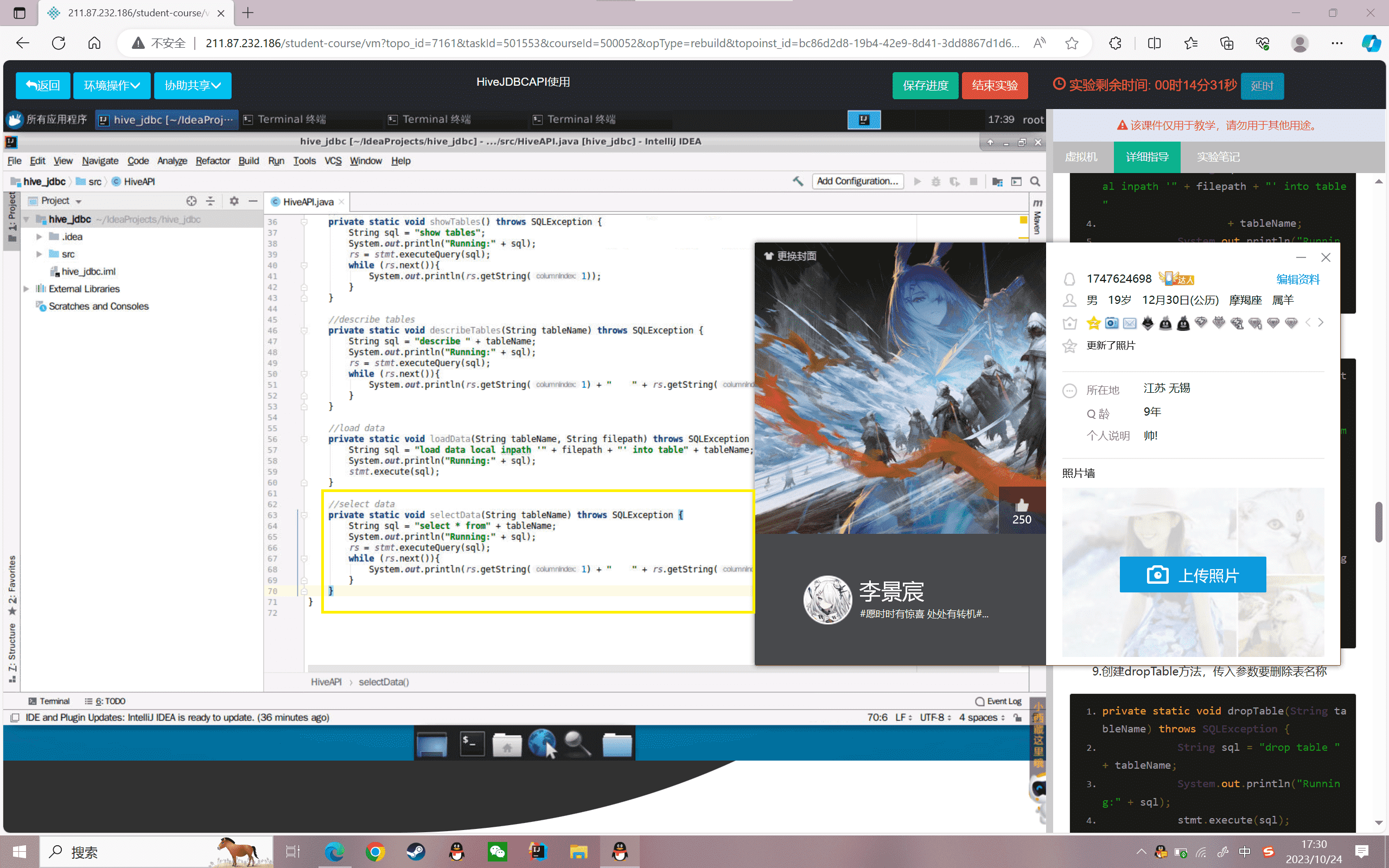
9.创建dropTable方法,传入参数要删除表名称
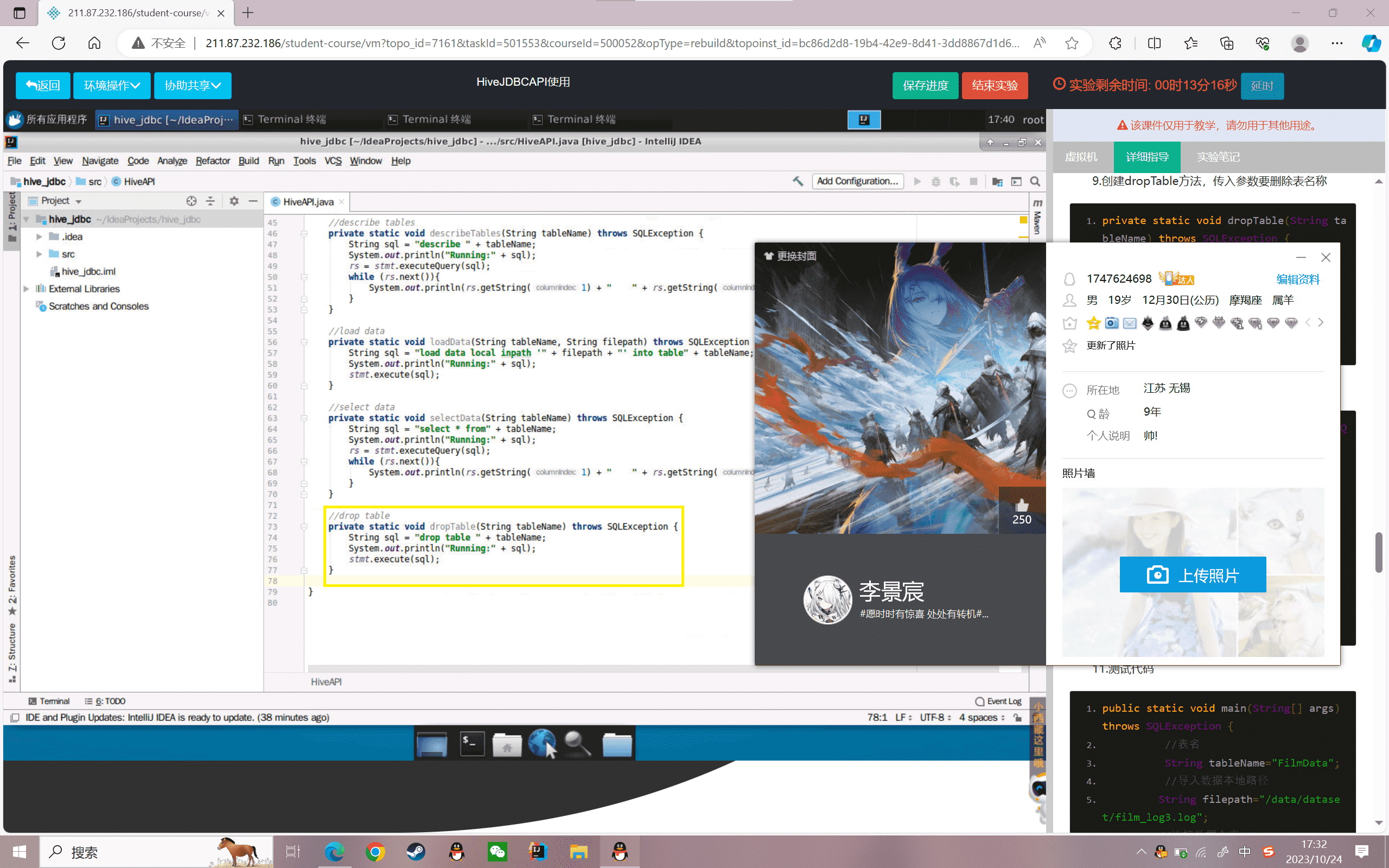
10.关闭连接数据仓库的传输资源
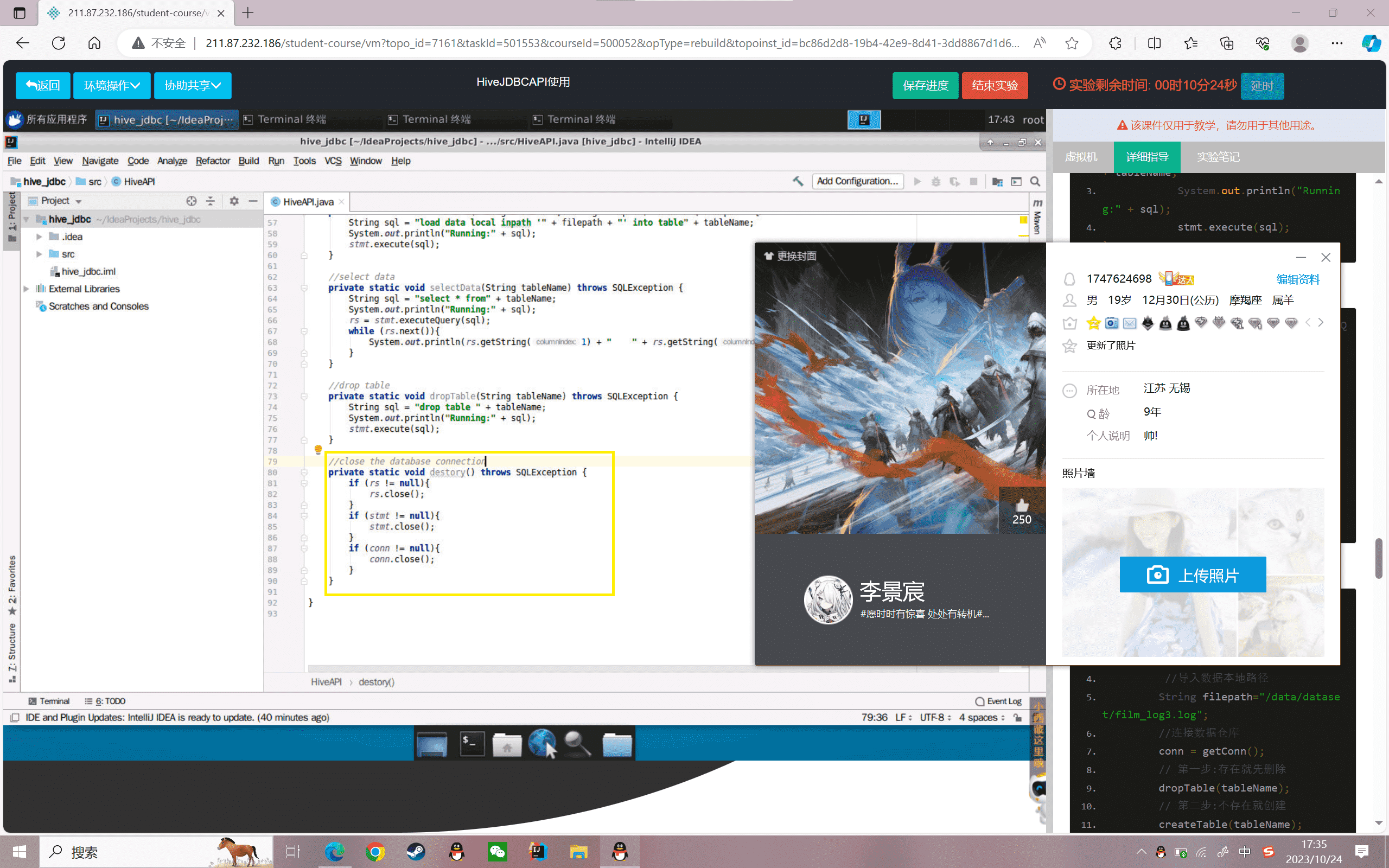
11.测试代码
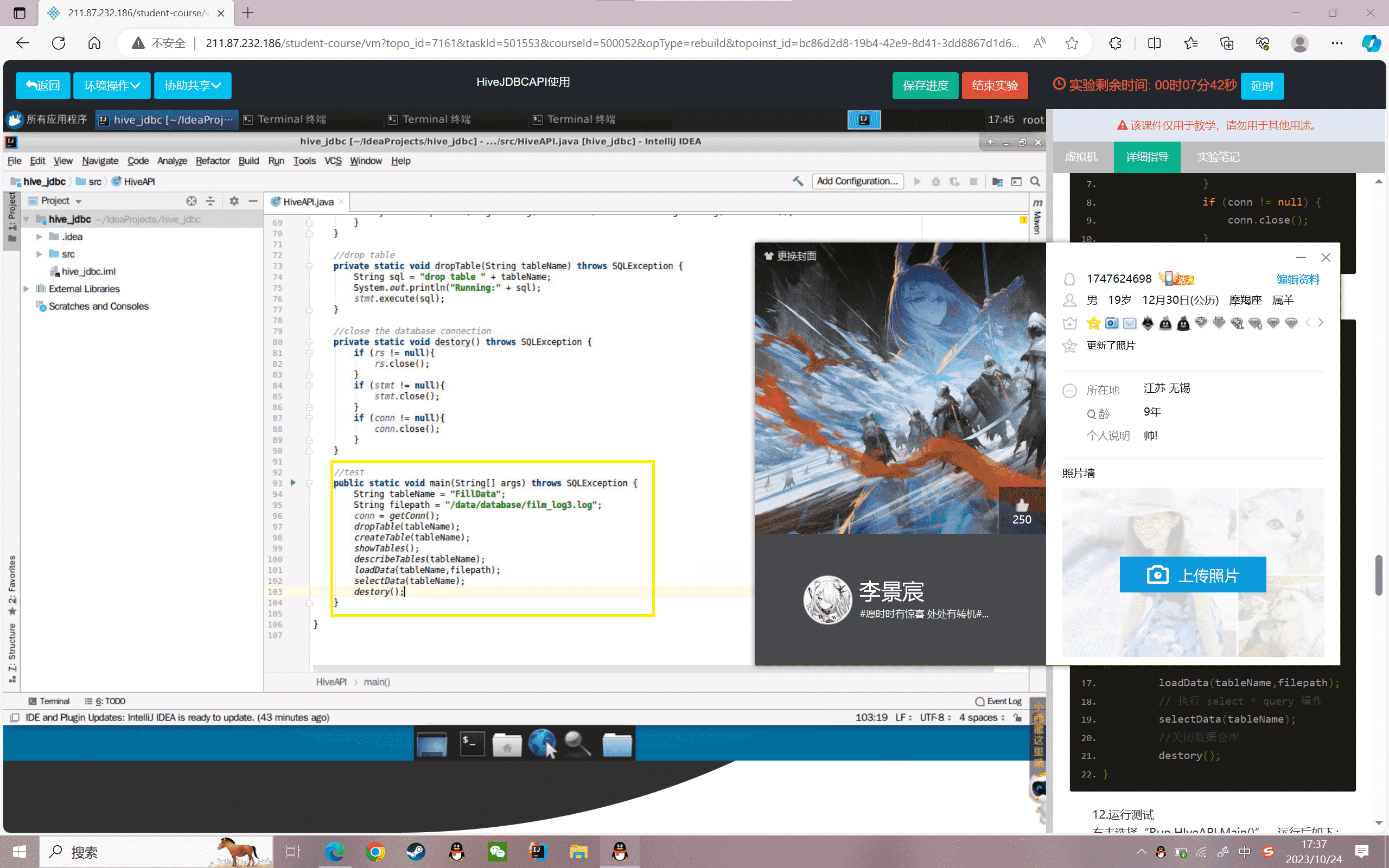
12.运行测试
右击选择“Run HIveAPI.Main()”,运行后如下:
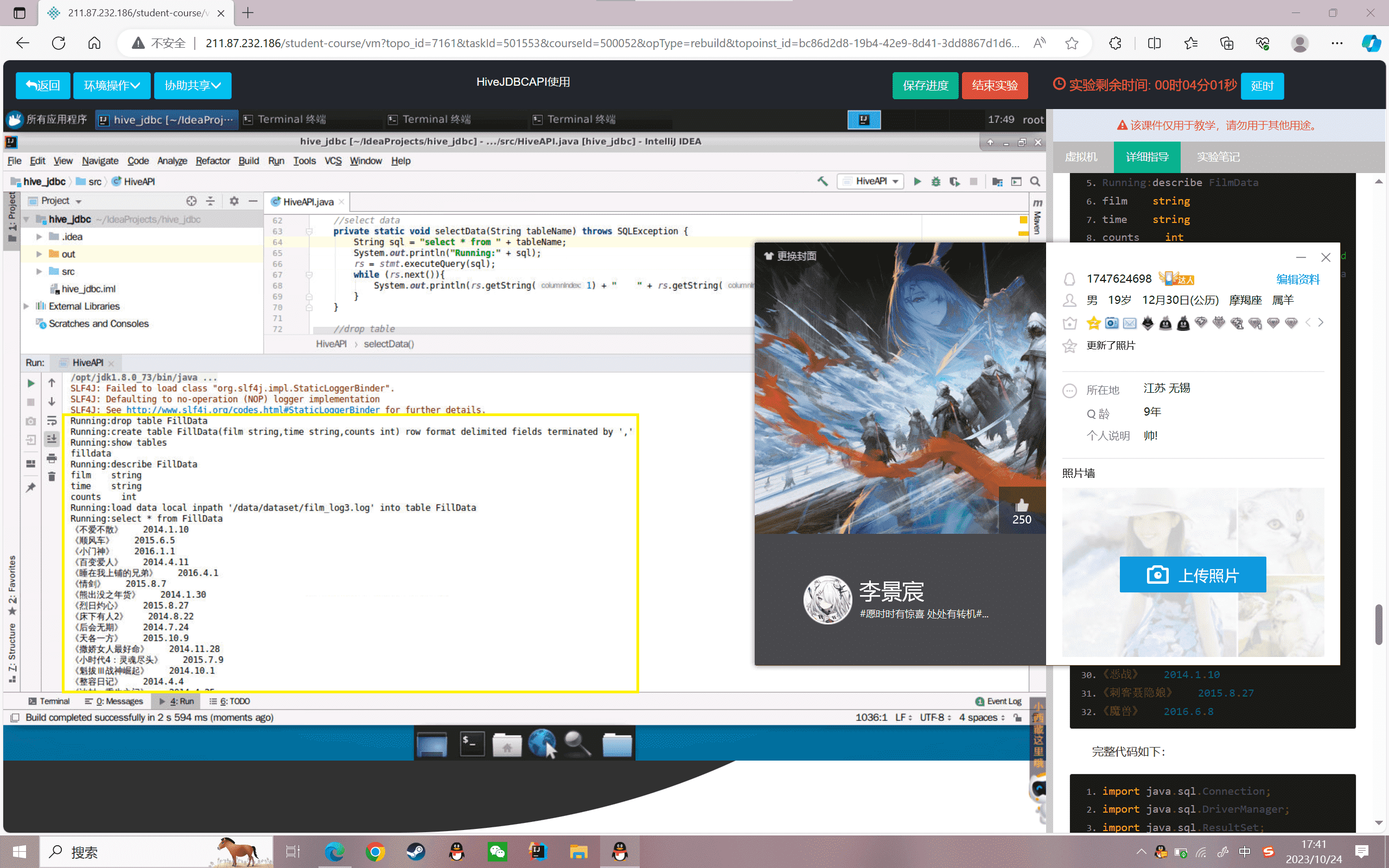
完整代码如下:
1 | package com.jc.springboot.config; |
实验感悟
通过实验,我掌握了Hive JDBC API的基本使用方法,包括加载驱动、建立连接、创建表、加载数据、查询数据等。我了解到JDBC可以通过Java代码调用Hive的SQL,实现对Hive上数据的操作,这为我以后进行Hive上数据分析提供了思路。
实验中,我对JDBC的相关类也有了进一步的认识。如DriverManager类可以获取连接,Statement类可以用于执行SQL语句,ResultSet类用于存储查询结果等。这些知识为我今后使用JDBC提供了基础。
在编码方面,我学习到了模块化编程的思想,如将连接Hive的代码封装成方法,根据功能将CRUD分成不同方法等。这让我的代码更加清晰易读。
通过这个实验,我对Hive的应用场景也有了一定的了解,即使用JDBC可以通过Java程序对Hive进行操作,这在需要将Hive数据应用到其他业务系统时很有用。
总之,通过这个实验,我对JDBC的用法有了一定的掌握,也对Hive的应用有了更深的理解。今后我还会继续学习JDBC的高级用法,以及Hive的其他功能,为以后的数据仓库开发打下基础。
对抗不能复制粘贴的努力
这次实验的代码是不能直接通过粘贴板进行cv,在虚拟机里使用idea编程是一件很痛苦的事情,那么有没有什么办法能偷懒呢?答案就是ssh传输协议。

在这里我们知道了虚拟机的ip、用户名、密码和ssh端口号,那么就可以使用ssh协议将本地编辑好的代码传到虚拟机上去,这里我使用软件filezilla来实现。
首先,配置站点信息:
点击连接,成功了
选择合适的路径,双击要上传的文件,在提示成功之后,就可以在虚拟机中看到了
实验 5.1
实验目的
掌握Sqoop的安装部署
了解Sqoop的部署环境
掌握Sqoop的部署后测试
实验内容
1、启动Hadoop服务
2、Sqoop的安装部署
3、Sqoop的部署测试
实验原理
本实验主要是对Sqoop的安装部署并测试。Sqoop的主要用途是HDFS和关系型数据之间数据相互迁移,迁移过程是转换为MapReduce任务,所以安装环境需要部署Hadoop和MySQL,以及部署完成后与MySQL的连通测试。
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、sqoop-1.4、Hadoop-2.7、mysql5.7
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验步骤
启动Hadoop服务
1、检查MySQL是否安装
1 | mysql -u root -proot |
2、检测是否安装Hadoop
启动Hadoop:
1 | start-all.sh |
查看守护进程是否启动,如下图所示:
Sqoop的安装部署
1、解压Sqoop
进入软件包所在文件夹中:
1 | cd /data/software |
将Sqoop解压安装到“/data/bigdata/”目录下:
1 | tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /data/bigdata/ |
查看解压后的Sqoop安装文件:
2、修改Sqoop的配置文件
进入到Sqoop的配置文件目录下:
1 | cd /data/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/conf |
修改sqoop-env.sh文件
目录下默认情况没有sqoop-env.sh文件,需要将sqoop-env-template.sh文件复制并重命名为sqoop-env.sh:
1 | cp sqoop-env-template.sh sqoop-env.sh |
进入sqoop-env.sh文件中:
1 | vi sqoop-env.sh |
修改该文件内容如下:
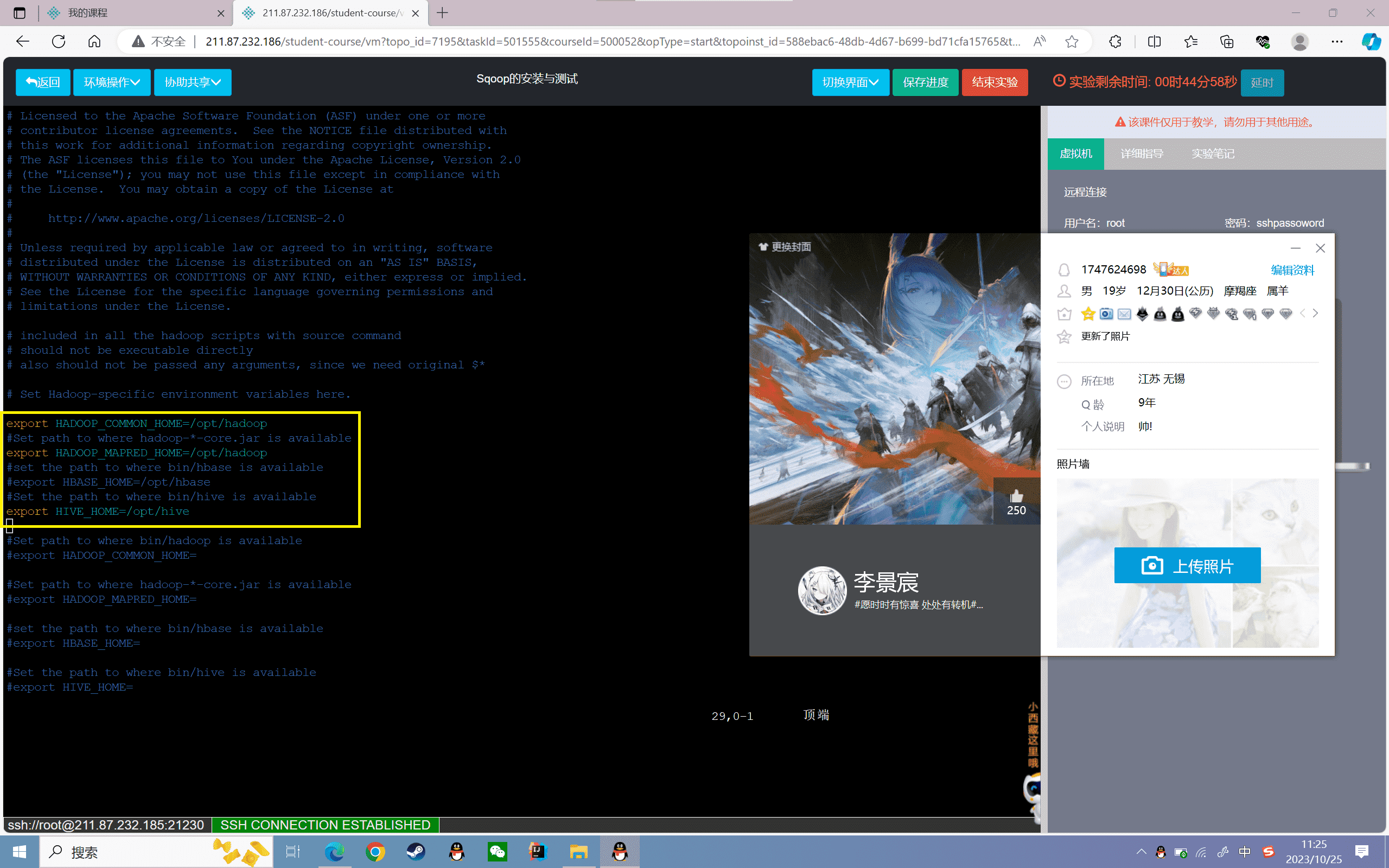
可以根据实际安装的软件来编写配置文件(hive、hbase)
3、将MySQL的驱动包放入sqoop的lib 目录下:
1 | cp /data/software/mysql-connector-java-5.1.45-bin.jar /data/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/lib/ |
Sqoop的部署测试
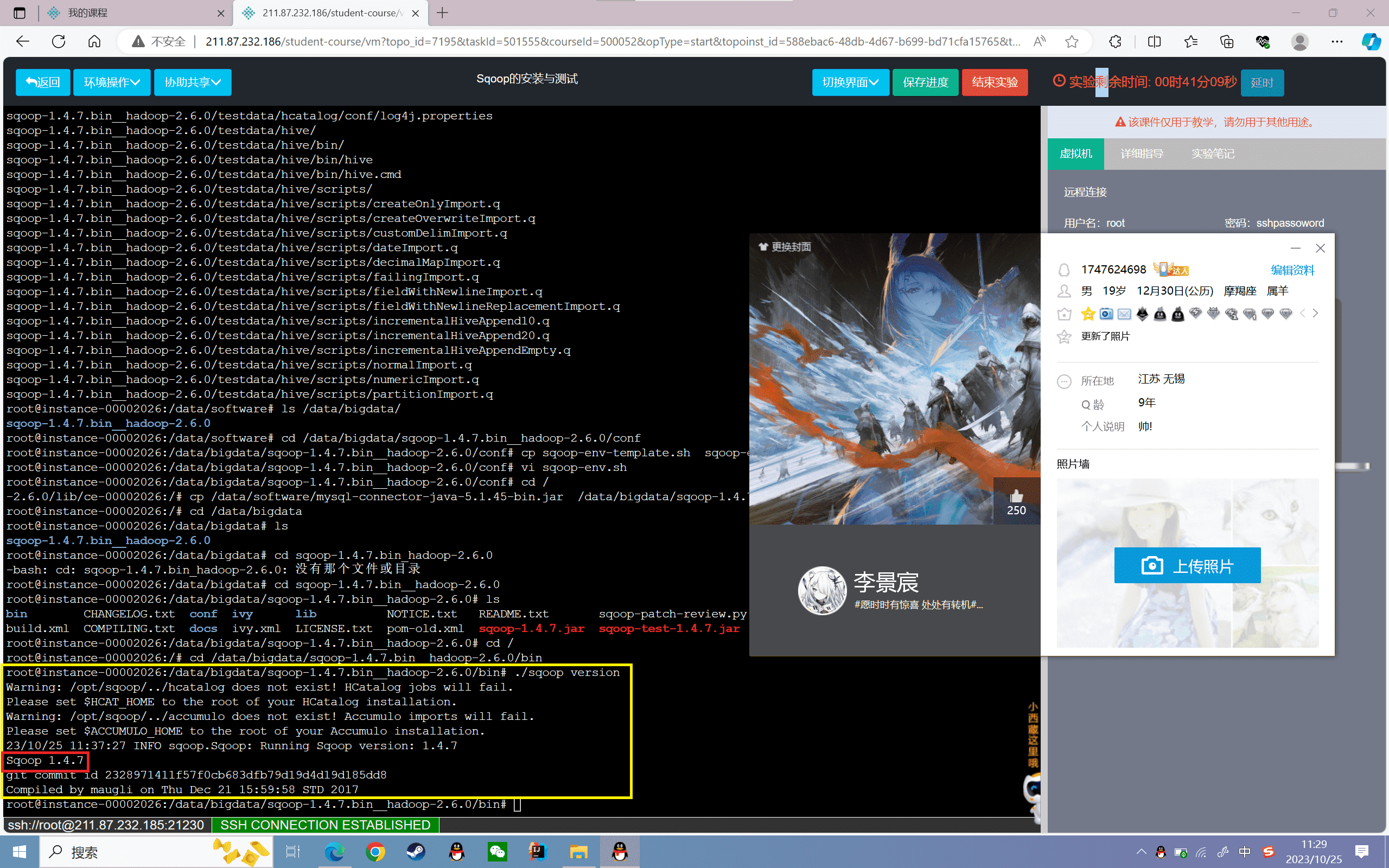
1、查看Sqoop的版本号:
1 | cd /data/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/bin./sqoop version |
查看结果,如下图所示:
2、查看Sqoop的命令帮助:
1 | ./sqoop help |
查看结果,如下图所示:
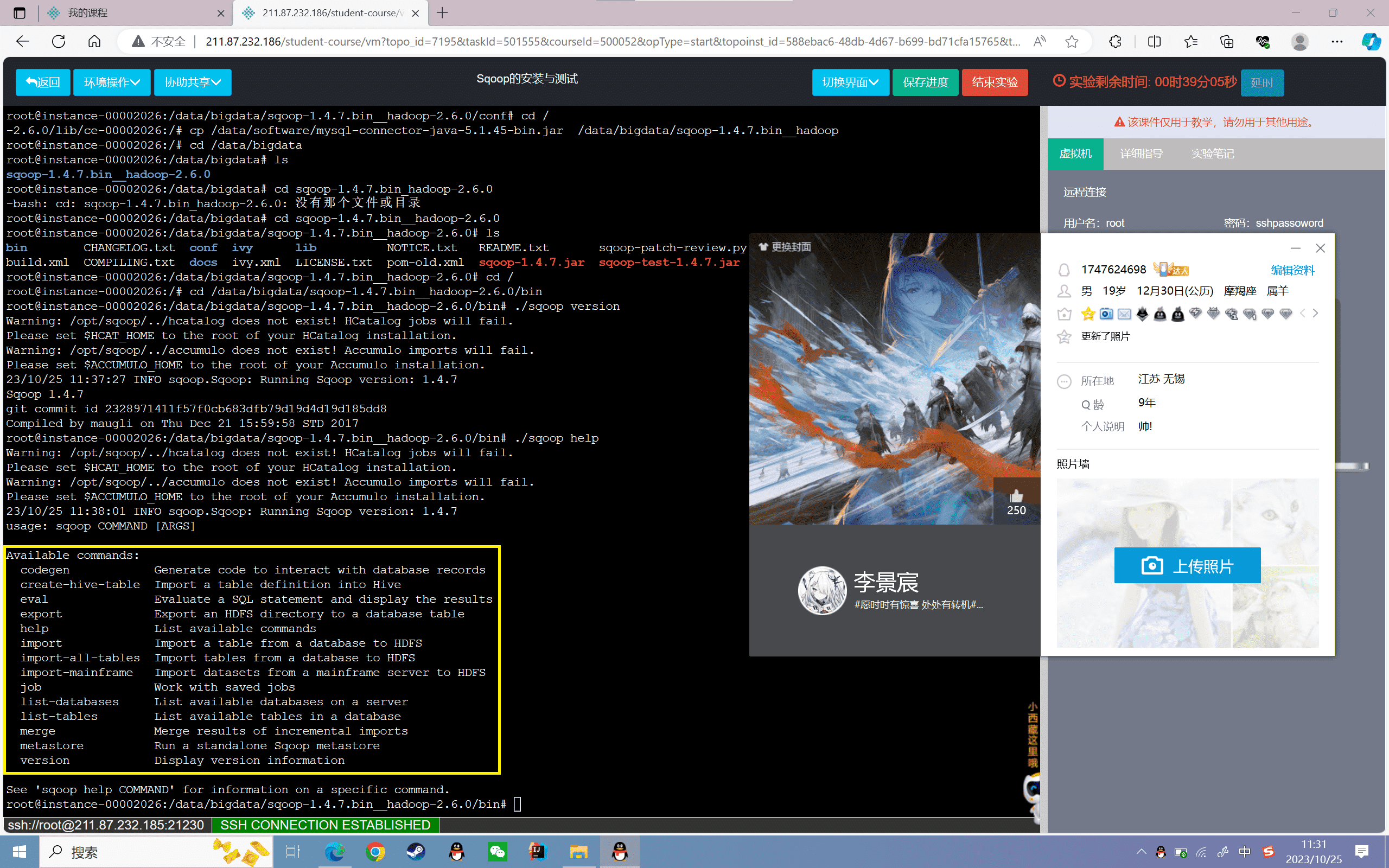
3、连接MySQL数据库
1 | service mysql start |
可以看到MySQL中遍历出来的数据库,如下如图所示:
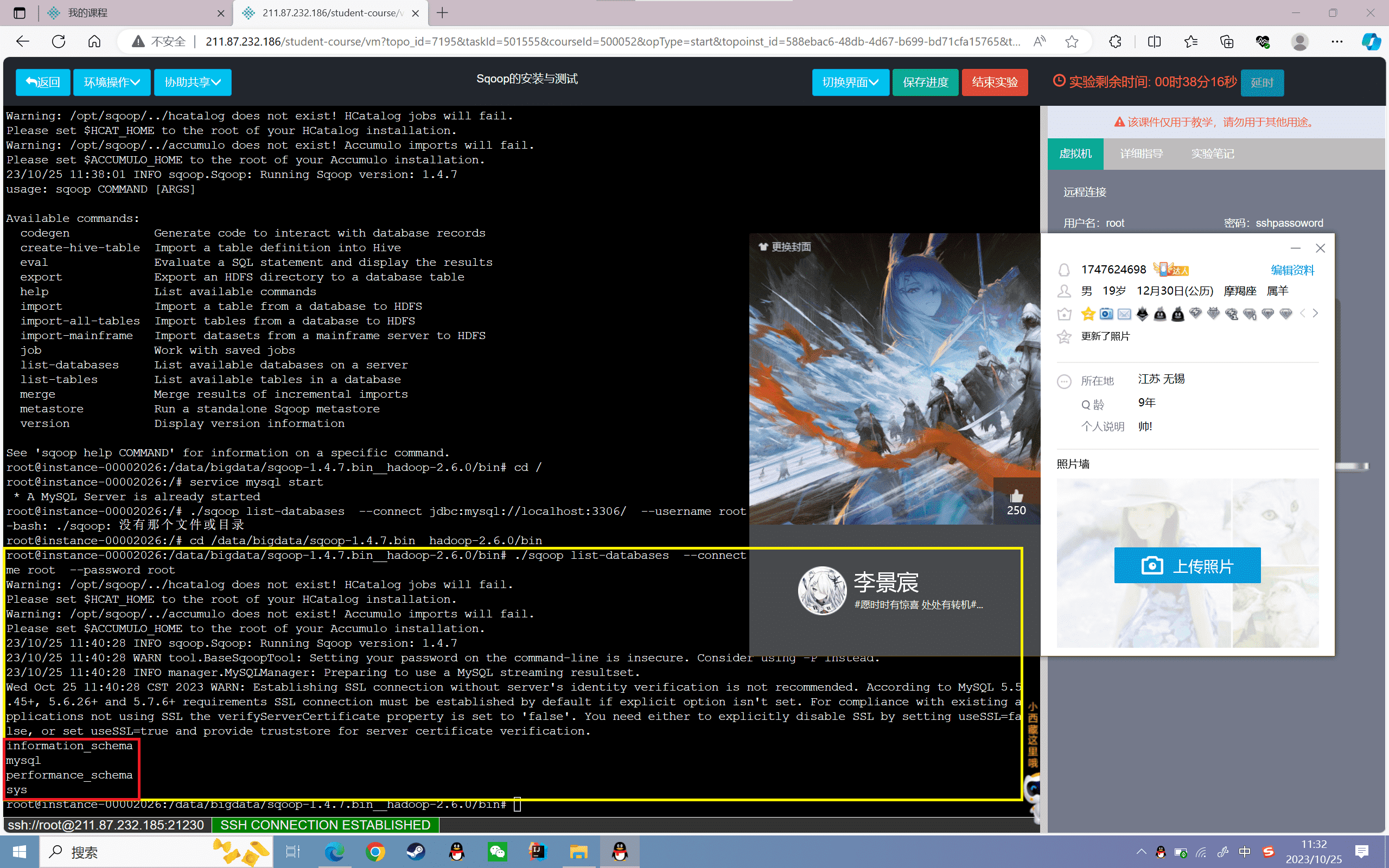
通过上面测试可以发现Sqoop已经部署成功,可以使用了
实验感悟
Sqoop是一款开源的工具,主要用于在Hadoop和传统数据库之间进行数据的传输。它可以将关系型数据库如MySQL的数据导入到HDFS中,也可以将HDFS的数据导出到关系型数据库中。
本实验首先启动了Hadoop集群服务,然后解压并配置Sqoop的安装目录,主要是设置了Hadoop、Hive的环境变量。随后将MySQL的JDBC驱动拷贝到Sqoop的lib目录下,这样Sqoop就可以连接MySQL数据库了。
通过查看版本信息、帮助文档、连接MySQL数据库等测试,我验证了Sqoop安装成功,可以进行数据迁移。这为后续导入导出数据到Hive,进行统计分析奠定了基础。
本实验使我对Sqoop有了直观的使用体会,掌握了它的安装部署方法。它架起了关系型数据库和HDFS之间的数据桥梁,可以让我充分利用Hive、MapReduce对数据进行并行处理。总之这次实验达到了学习Sqoop的目的,是使用Hadoop生态系统的重要一步。
实验 5.2
实验目的
掌握数据导入Hive表的方式
理解三种数据导入Hive表的原理
实验内容
1、启动Hadoop和Hive服务并创建数据表
2、将Hive表中的数据导出
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3、Hadoop-2.7、MySQL-5.7、Sqoop1.4
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Export工具将文件从HDFS导出到关系型数据库。目标表必须存在于数据库中,根据用户指定的分隔符读取输入文件并解析为一条记录。
默认操作是将这些数据以“insert ”的方式插入到数据库表中;在“更新模式”中,Sqoop将使用“update”的方式更新记录。

Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
实验步骤
启动Hadoop和Hive服务并创建数据表
1、检查MySQL是否安装
2、检测是否安装Hadoop
3、启动Mysql和Hive:
1 | service mysql start |
4、创建表
创建film表,分为电影名称、上映日期、票房三个字段,数据格式以“,”分割:
1 | hive> create table film(name string,dates string,prince int) row format delimited fields terminated by ','; |
5、导入数据
将本地的film_log3.log文件数据加载到film表:
1 | hive> load data local inpath '/data/dataset/film_log3.log'into table film; |
6、查看film表数据的总条数:
1 | hive> select count(*) from film; |
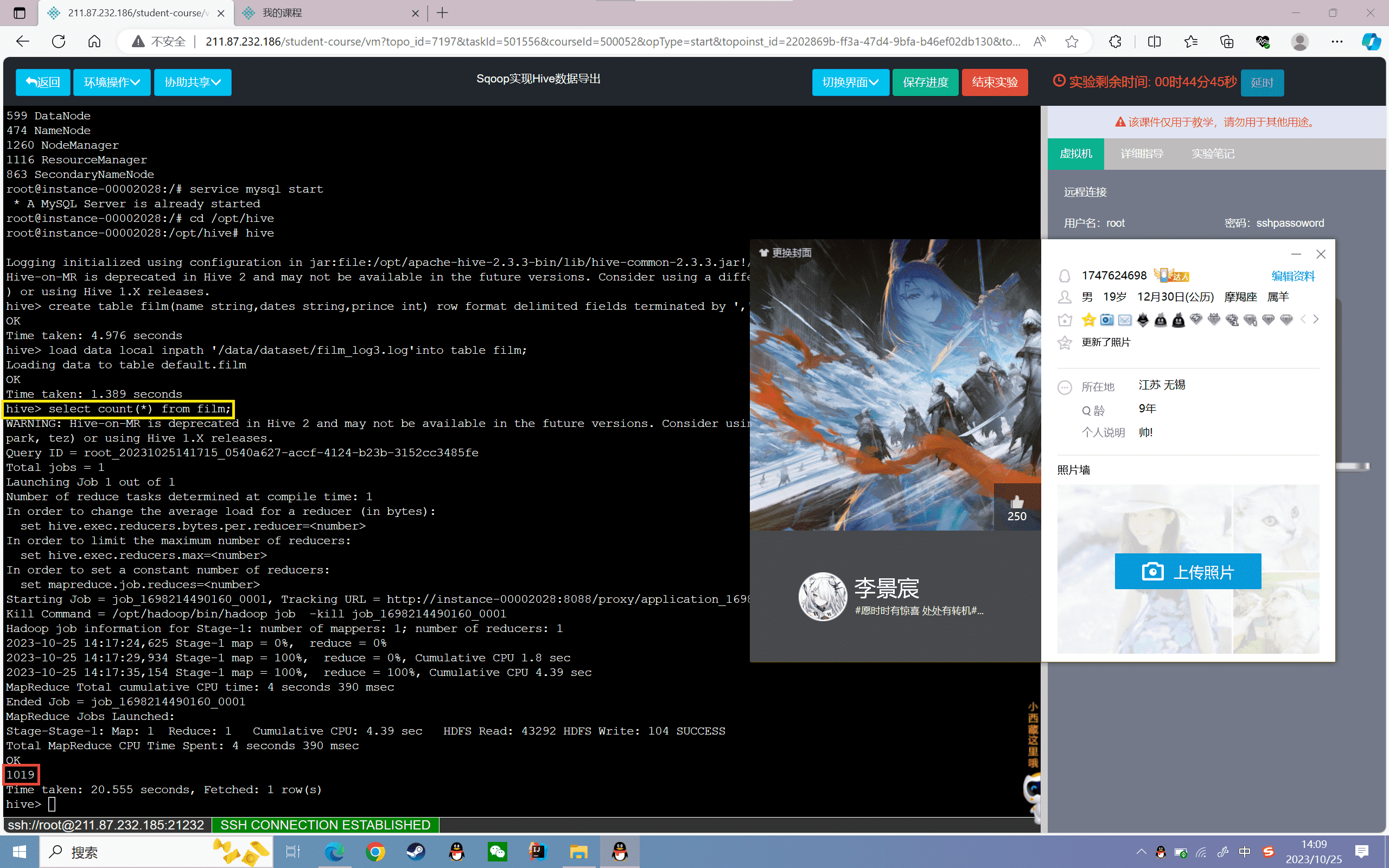
7、使用MySQL创建film_info表
1 | mysql -uroot -prootcreate database data;use data;create table film_info(name varchar(50),dates varchar(50),prince double)engine=innodb charset=utf8; |
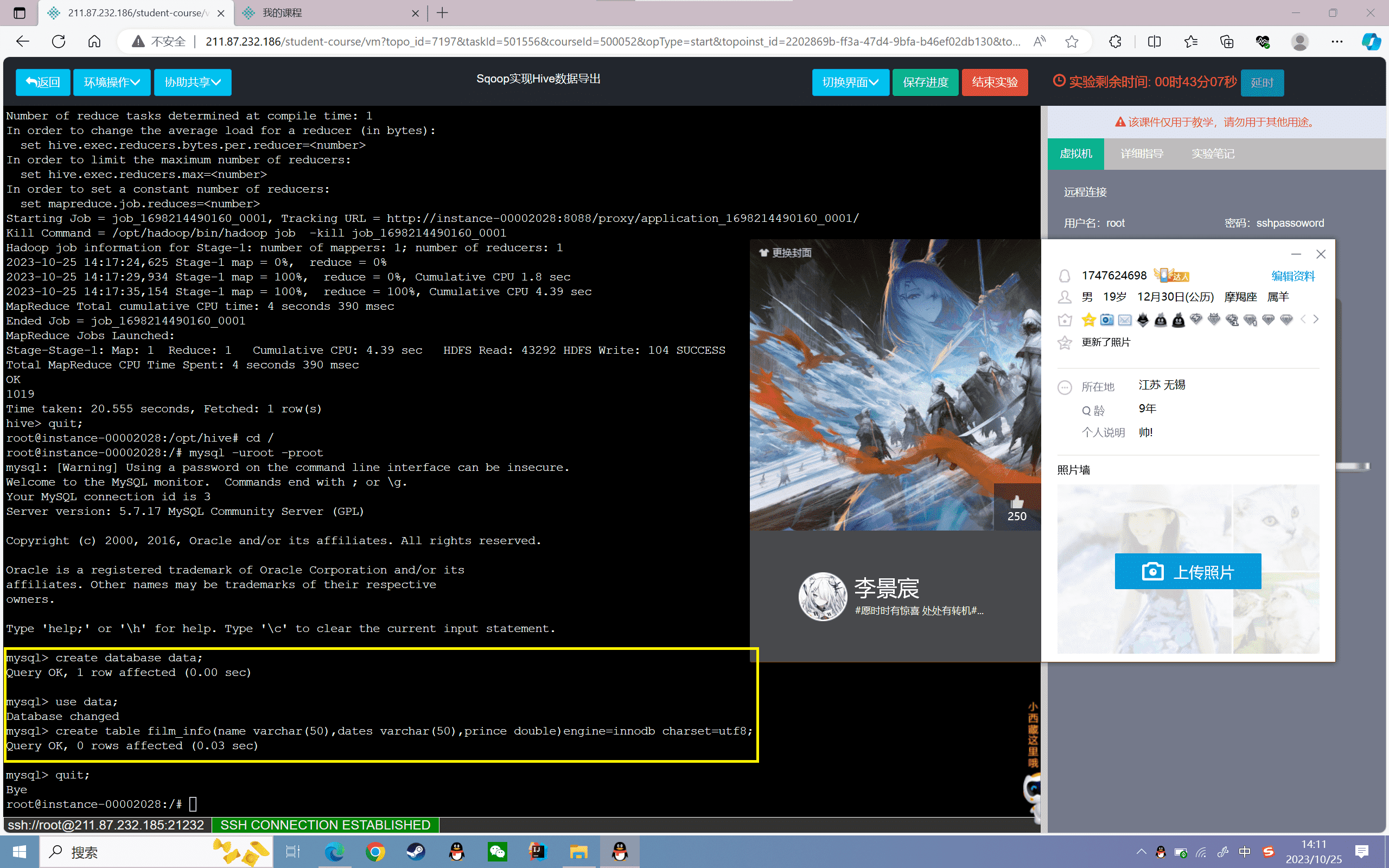
将Hive表中的数据导出
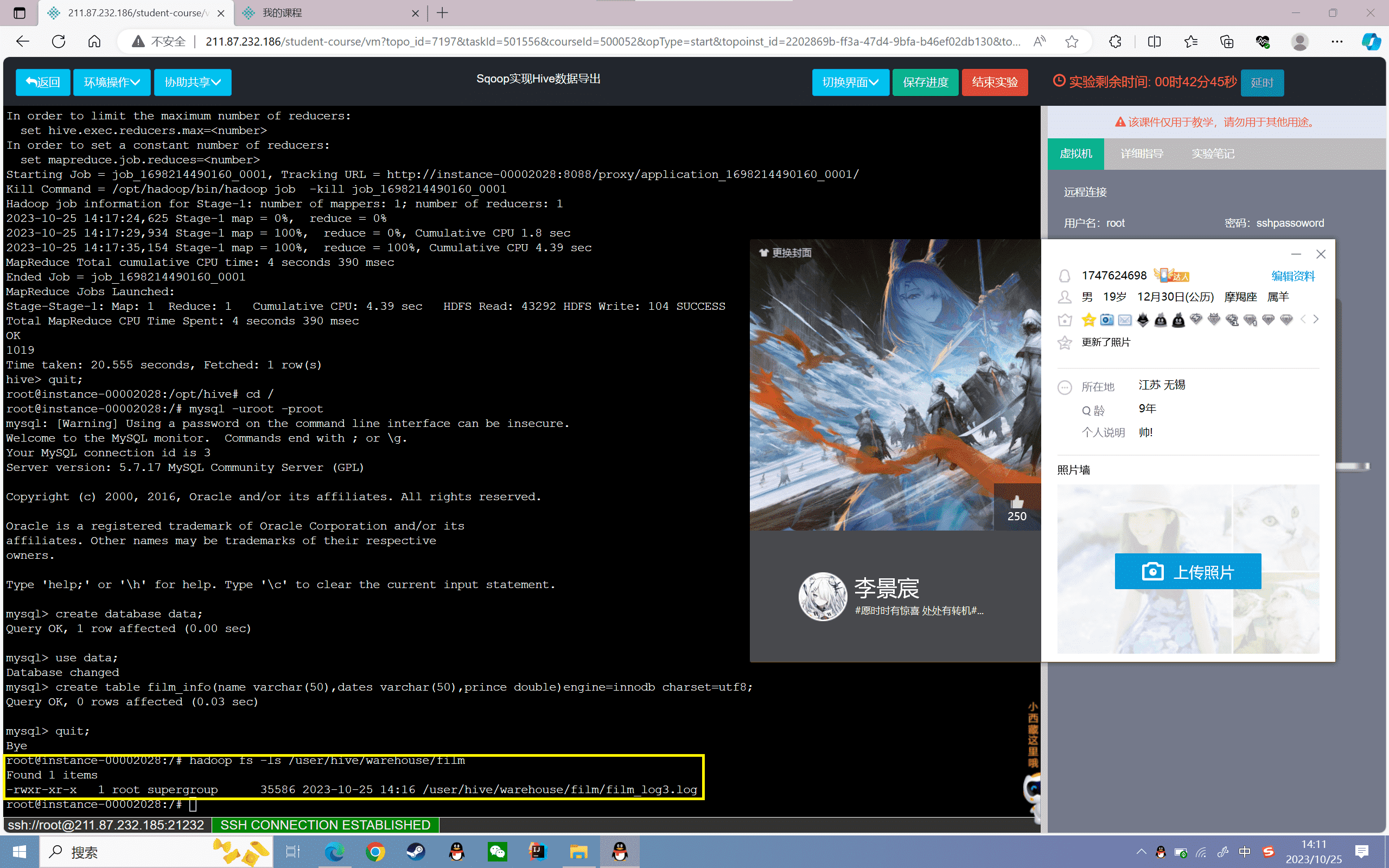
1、查看hive中的film表在HDFS上的存储位置
1 | hadoop fs -ls /user/hive/warehouse/film |
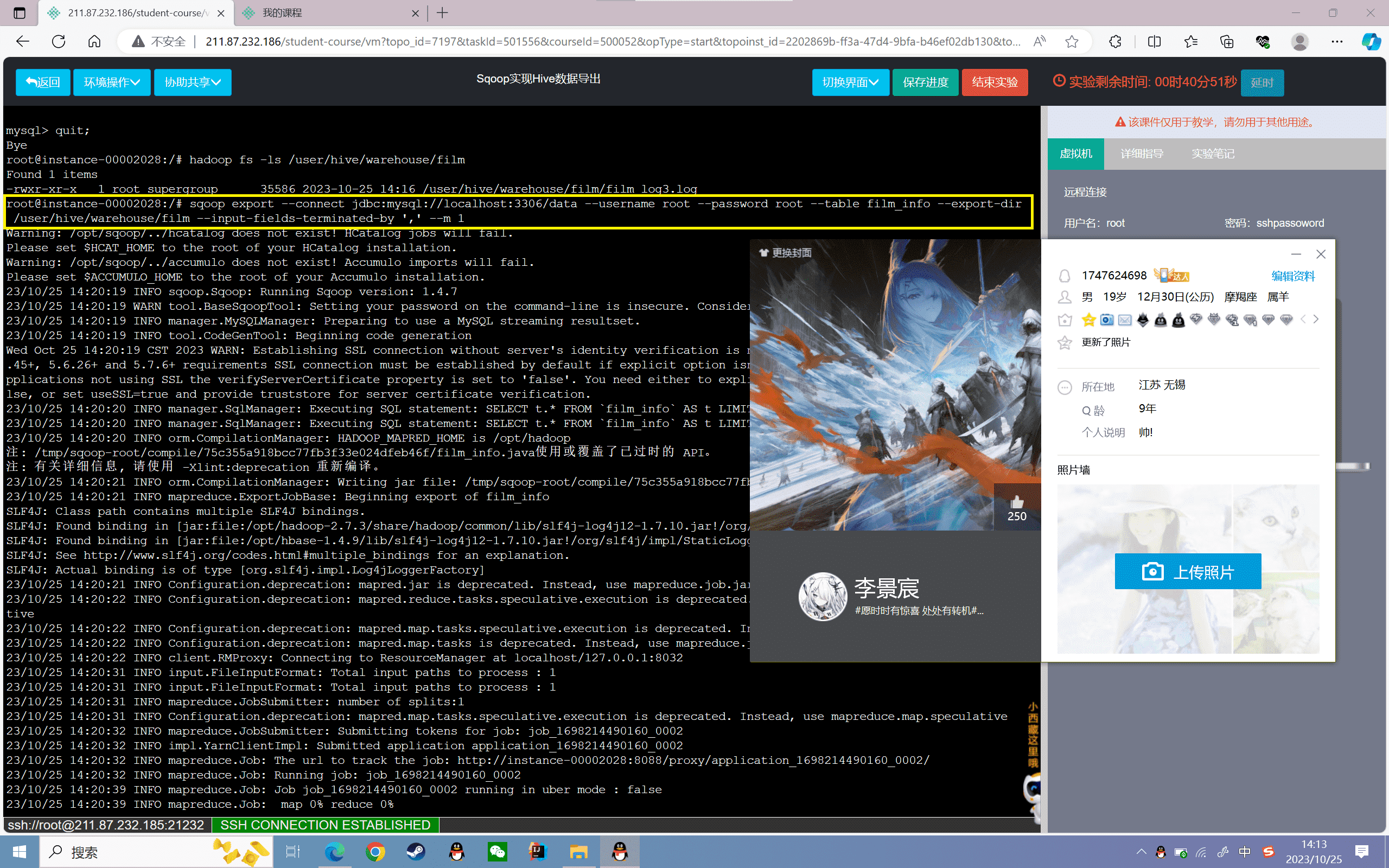
2、将hive的film表数据导出到指定表film_info中
1 | sqoop export --connect jdbc:mysql://localhost:3306/data --username root --password root --table film_info --export-dir /user/hive/warehouse/film --input-fields-terminated-by ',' --m 1 |
3、查看导出的结果
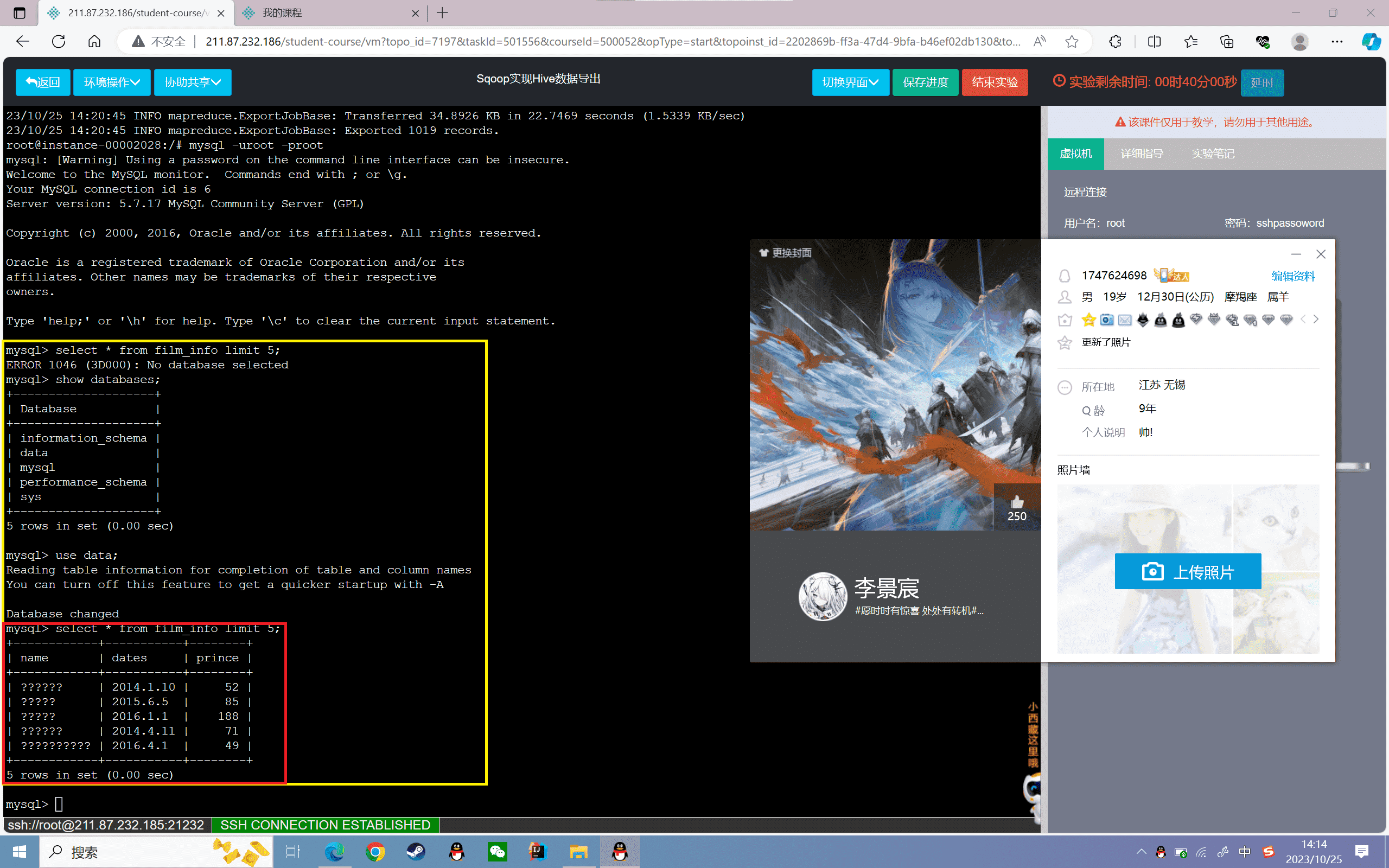
1 | mysql> select * from film_info limit 5; |
发现name这一列中文都是乱码,是因为导出的编码格式没有指定
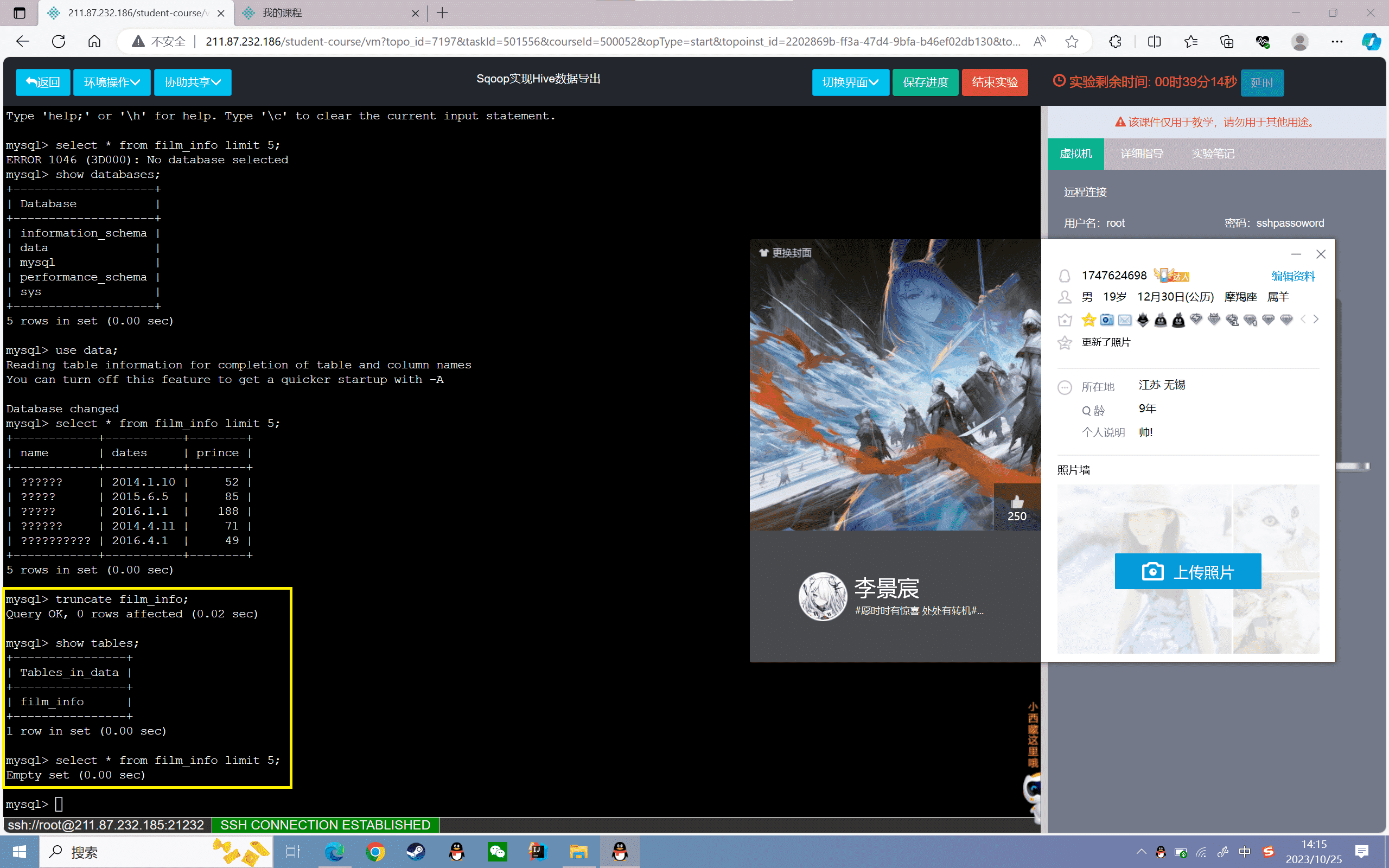
4、修改编码格式
1 | #清空表 |
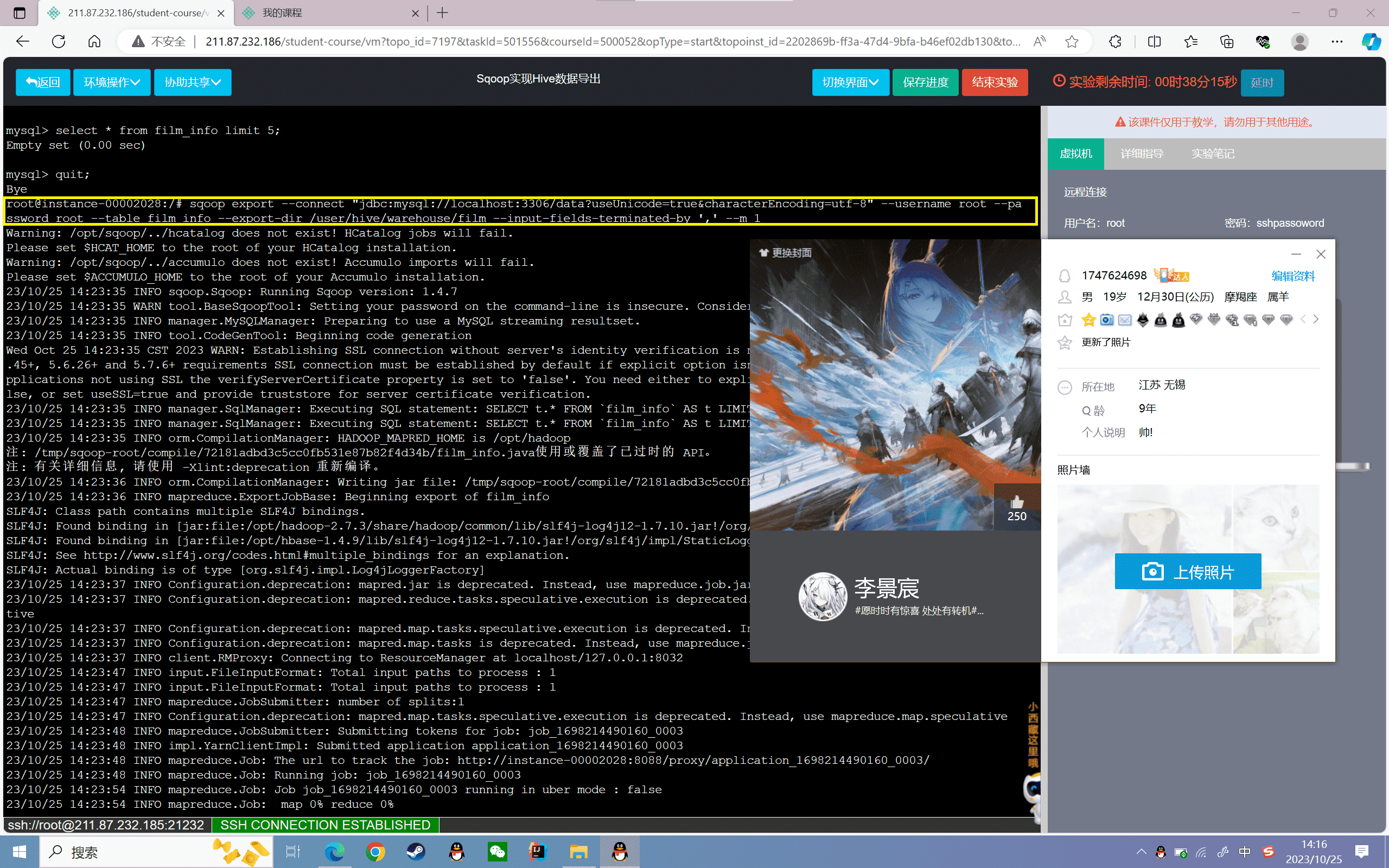
指定编码格式为“UTF-8”
1 | sqoop export --connect "jdbc:mysql://localhost:3306/data?useUnicode=true&characterEncoding=utf-8" --username root --password root --table film_info --export-dir /user/hive/warehouse/film --input-fields-terminated-by ',' --m 1 |
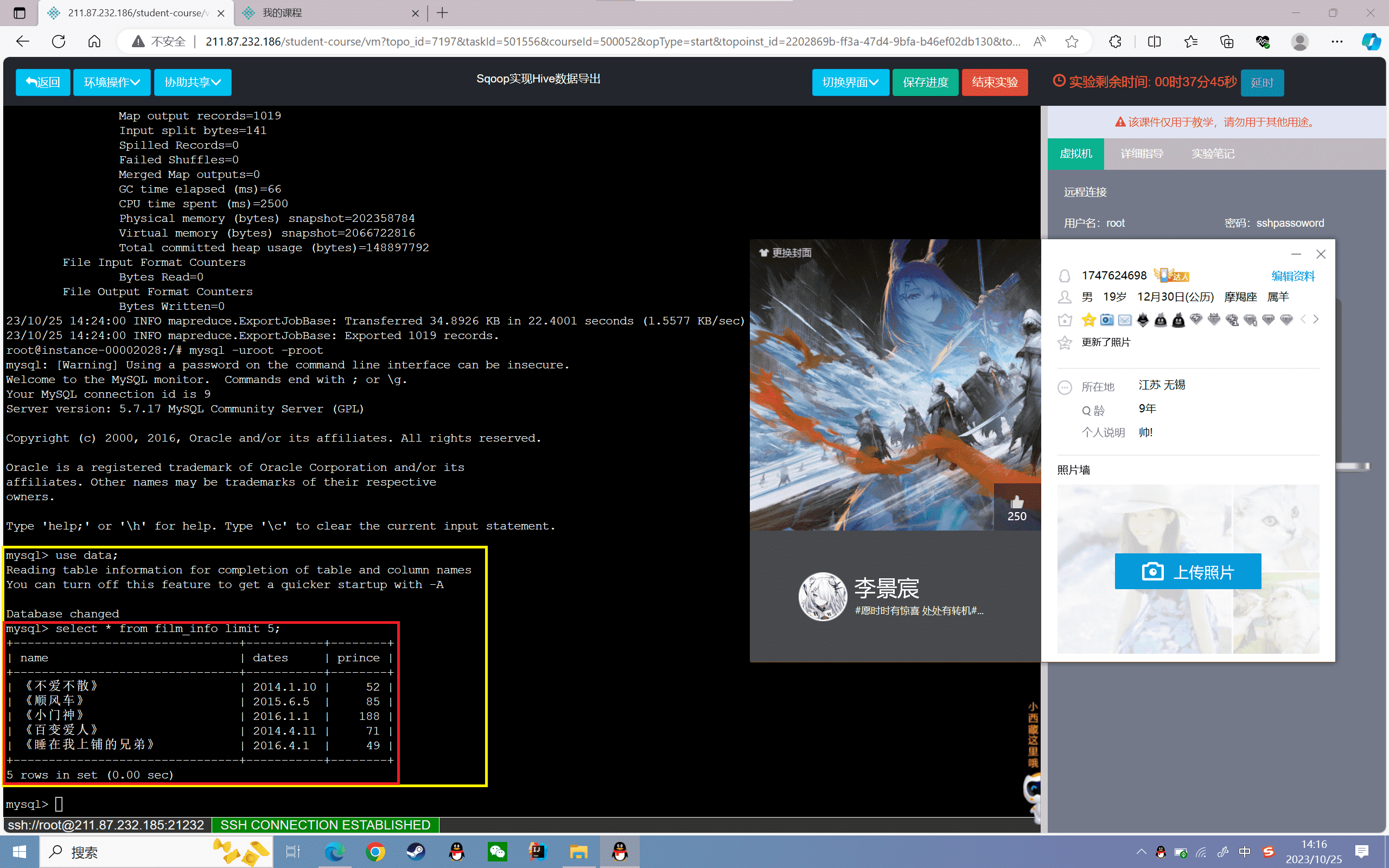
5、查看导出的结果
1 | mysql> select * from film_info limit 5; |
实验感悟
实验首先创建了Hive的film表,并加载数据。然后通过指定connect参数连接MySQL,以及export-dir指定HDFS路径,使用sqoop export将film表的数据导出到MySQL的film_info表中。
这样实现了从Hadoop生态到关系型数据库的顺利数据迁移。值得注意的是,在导出时需要根据实际情况指定参数,如本实验由于默认导出的编码不对,汉字出现了乱码,所以额外指定了characterEncoding的参数。
另外,由于Sqoop导入导出底层都是通过MapReduce任务实现的,所以可以实现并行数据迁移,效率很高。这为我们构建数据仓库提供了很大的便利。
通过这个实验,我掌握了Sqoop导出数据的方法,理解了它的实现原理。Sqoop充当了Hadoop和传统数据库之间的桥梁,让不同系统的数据能够相互流通,为数据分析提供了巨大的便利。总之,这个实验达到了使用Sqoop导出数据的目的,使我能够熟练运用这一重要工具。
实验 5.3
实验目的
掌握数据导入Hive表的方式
理解三种数据导入Hive表的原理
实验内容
1、启动Hadoop和Hive服务并创建数据表
2、使用Sqoop导入Hive
3、使用Sqoop导入Hive分区
实验环境
硬件:ubuntu 16.04
软件:JDK-1.8、hive-2.3、Hadoop-2.7、MySQL-5.7、Sqoop1.4
数据存放路径:/data/dataset
tar包路径:/data/software
tar包压缩路径:/data/bigdata
软件安装路径:/opt
实验设计创建文件:/data/resource
实验原理
Import工具指的是将单个表从关系型数据库中导入到HDFS。其中表的每一行都表示为HDFS中的单独记录,记录可以存储在文本文件、二进制表示的Avro或者SequenceFiles中。

Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
实验步骤
启动Hadoop和Hive服务并创建数据表
1、检查MySQL是否安装
2、检测是否安装Hadoop
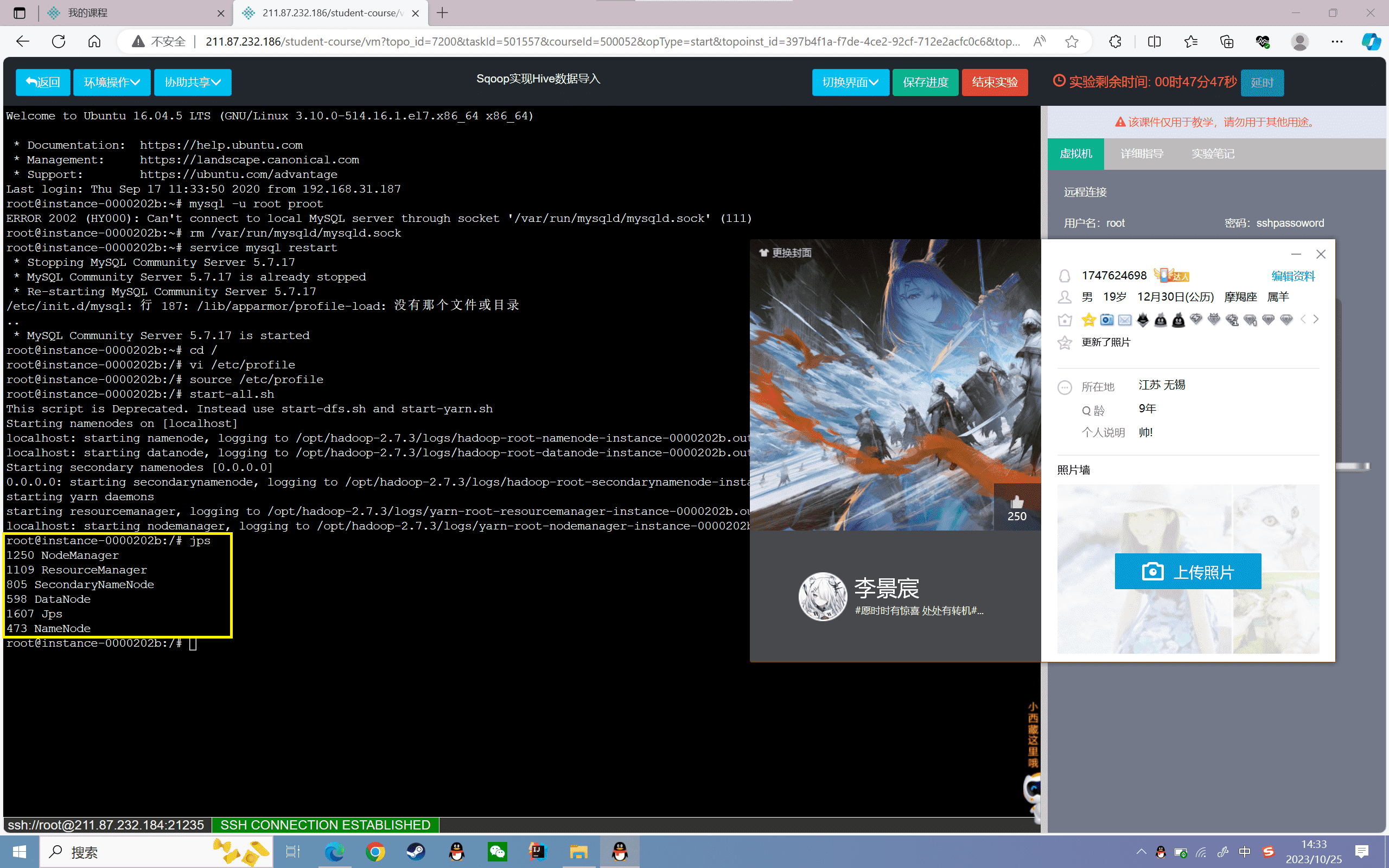
2、启动MySQL:
1 | service mysql startmysql -uroot -proot |
3、创建data数据库和info表:
1 | mysql> create database data;mysql> use data; |
4、插入数据
1 | mysql> insert into info(name,age,score)values("zhangfei",1,90); |
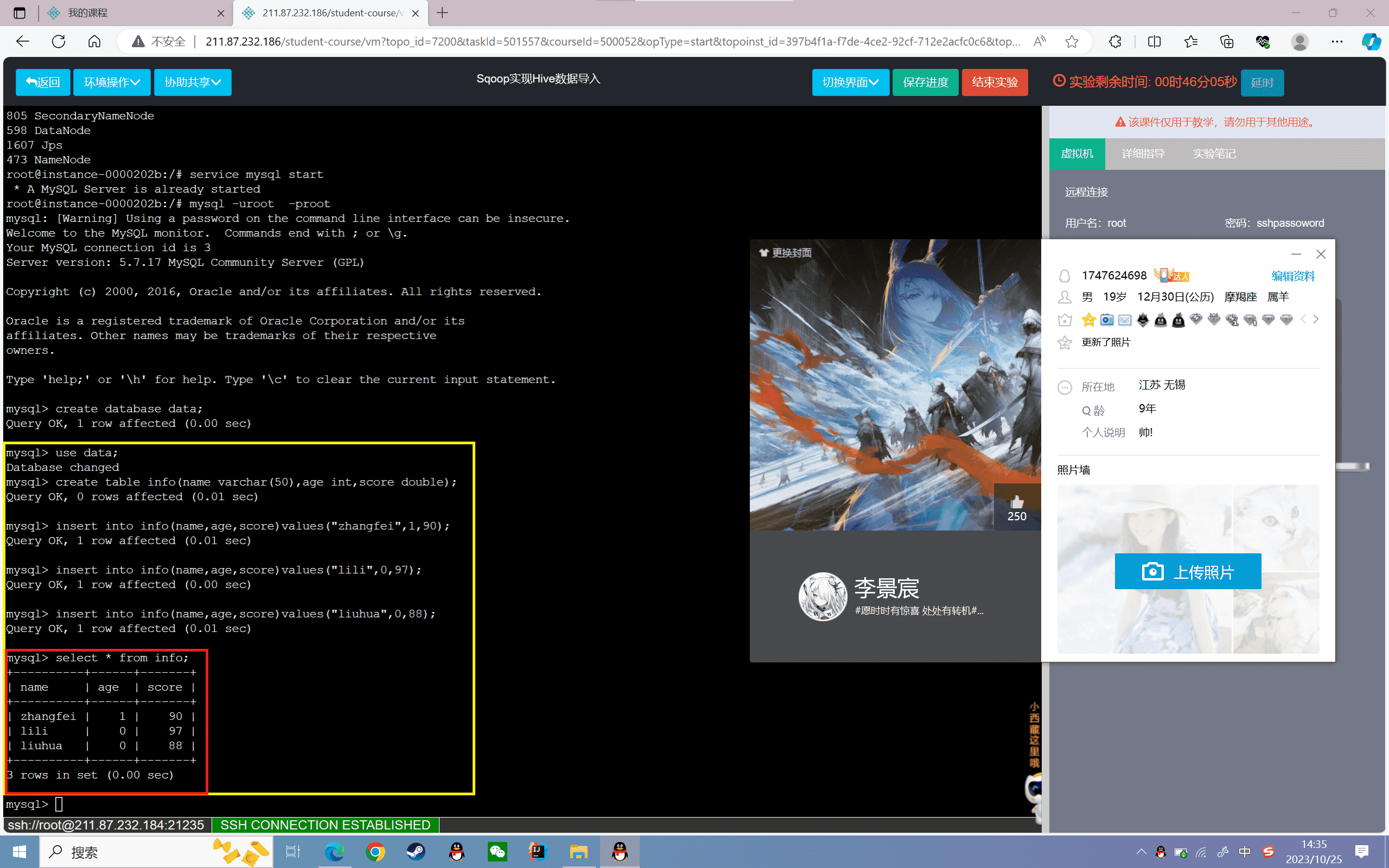
5、查看数据
1 | mysql> select * from info; |
6、将hive下的jar拷贝到sqoop下
1 | cp /opt/hive/lib/hive-common-2.3.3.jar /opt/sqoop/lib/ |
7、使用Sqoop将Mysql的info表字段信息复制到Hive中info中
所有关于hive的操作需要进入到hive的安装目录下进行,进入hive安装目录,打开hive
1 | cd /opt/hive/hive |
进入hive的交互式命令行界面,然后退出hive执行sqoop命令:
1 | sqoop create-hive-table --connect jdbc:mysql://localhost:3306/data --username root -password root --table info --hive-table info |
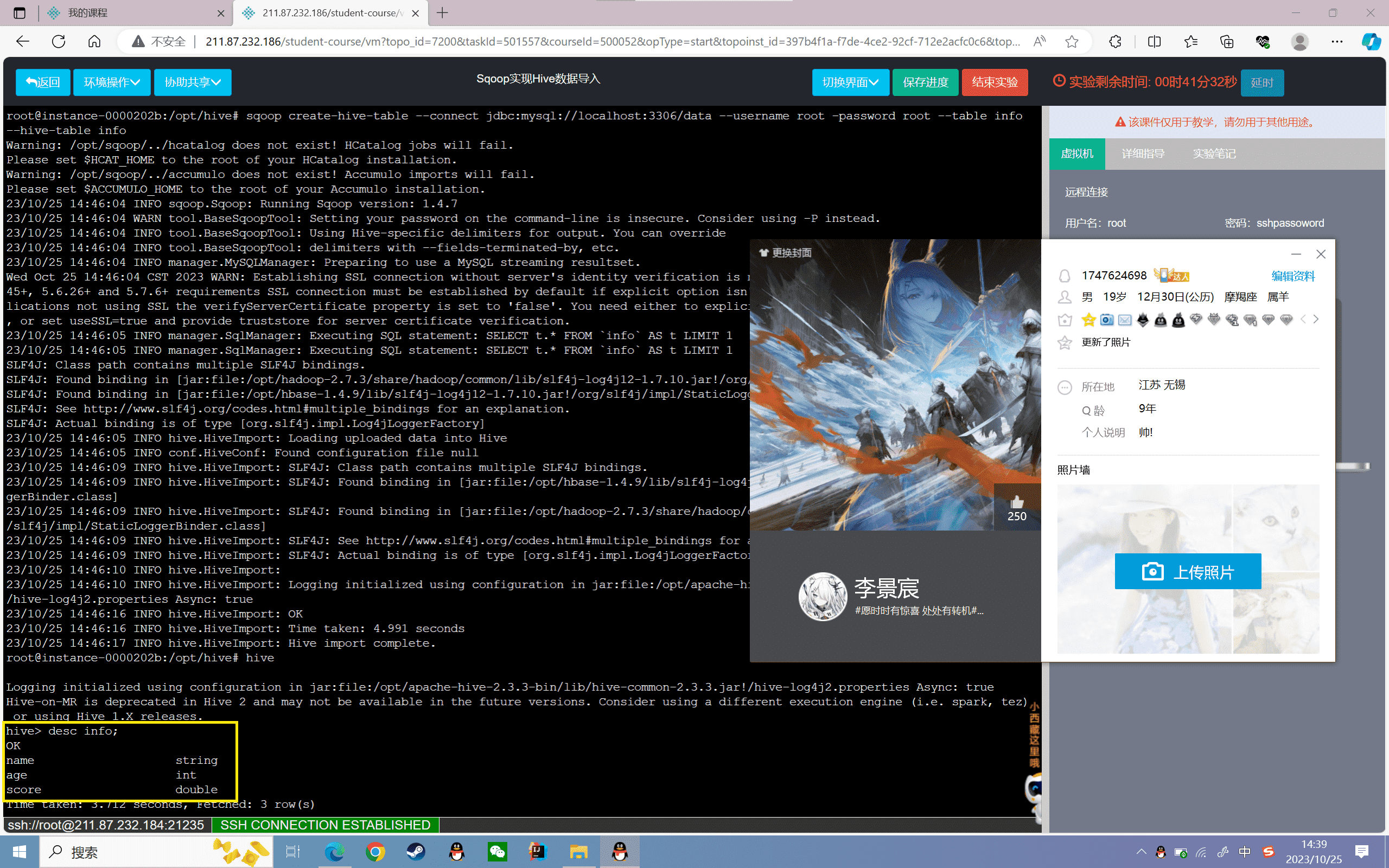
8、进入Hive中看info表字段信息
1 | hive> desc info; |
使用Sqoop导入Hive
直接导入
1、删除hive的info表在hdfs的存储位置
1 | hadoop fs -rmr /user/hive/warehouse/info |
2、将Mysql的info表导入HDFS的info表目录下
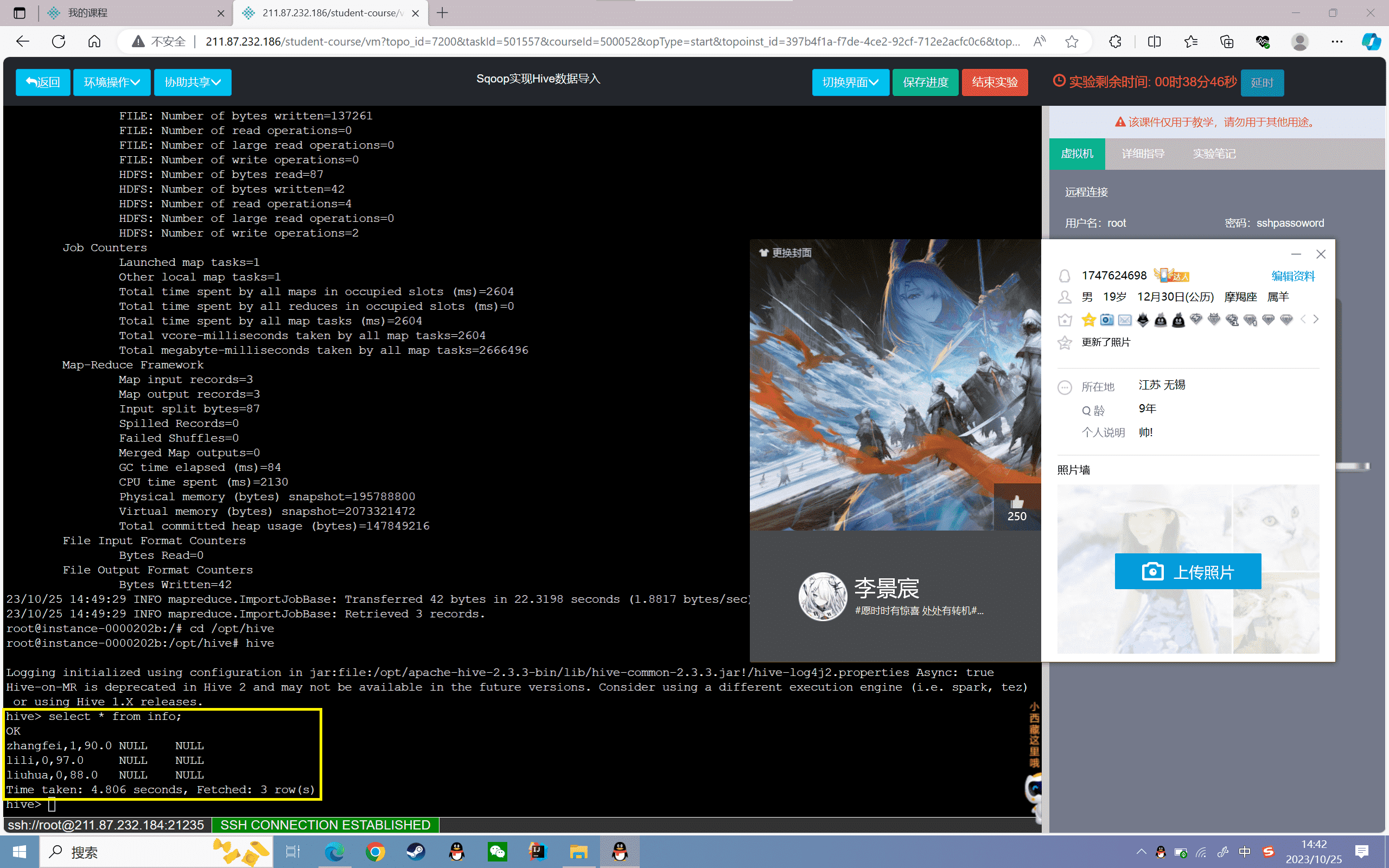
1 | sqoop import --connect jdbc:mysql://localhost:3306/data --username root --password root --table info --m 1 --target-dir /user/hive/warehouse/info/ --fields-terminated-by ',' |
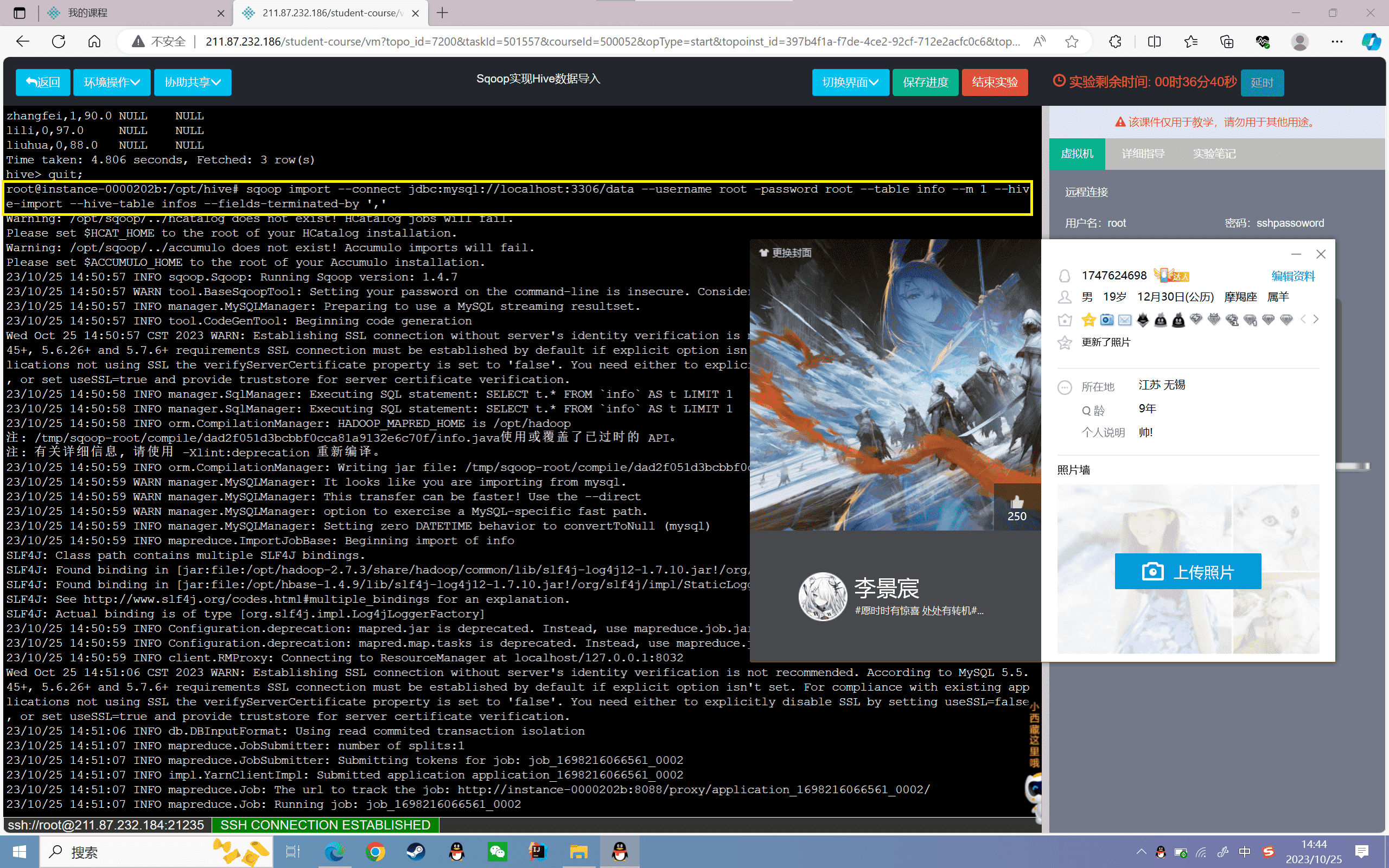
3、查看数据
1 | hive> select * from info; |
全量导入
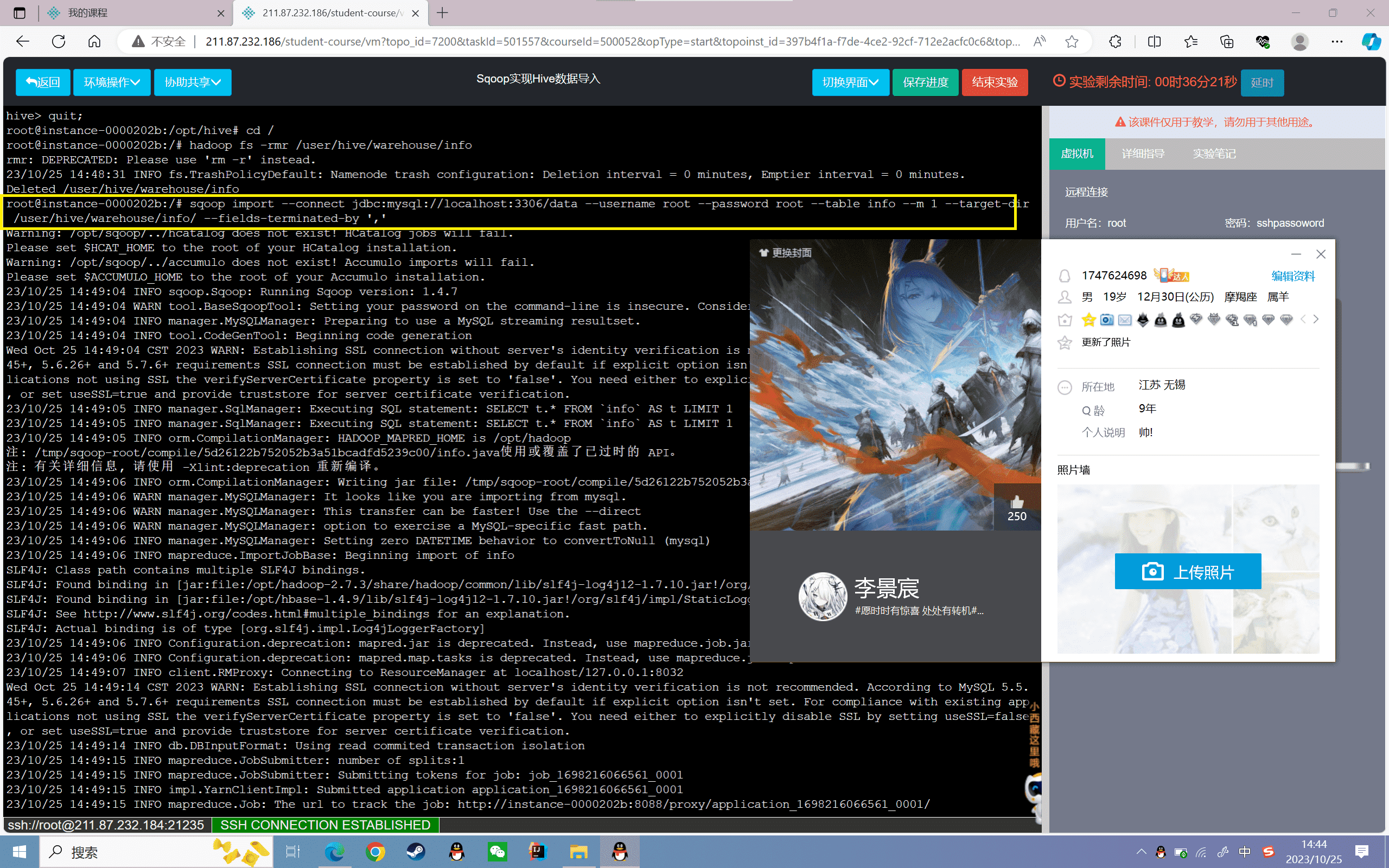
4、使用Sqoop将Mysql的info表字段信息复制到Hive中infos中
1 | sqoop import --connect jdbc:mysql://localhost:3306/data --username root -password root --table info --m 1 --hive-import --hive-table infos --fields-terminated-by ',' |
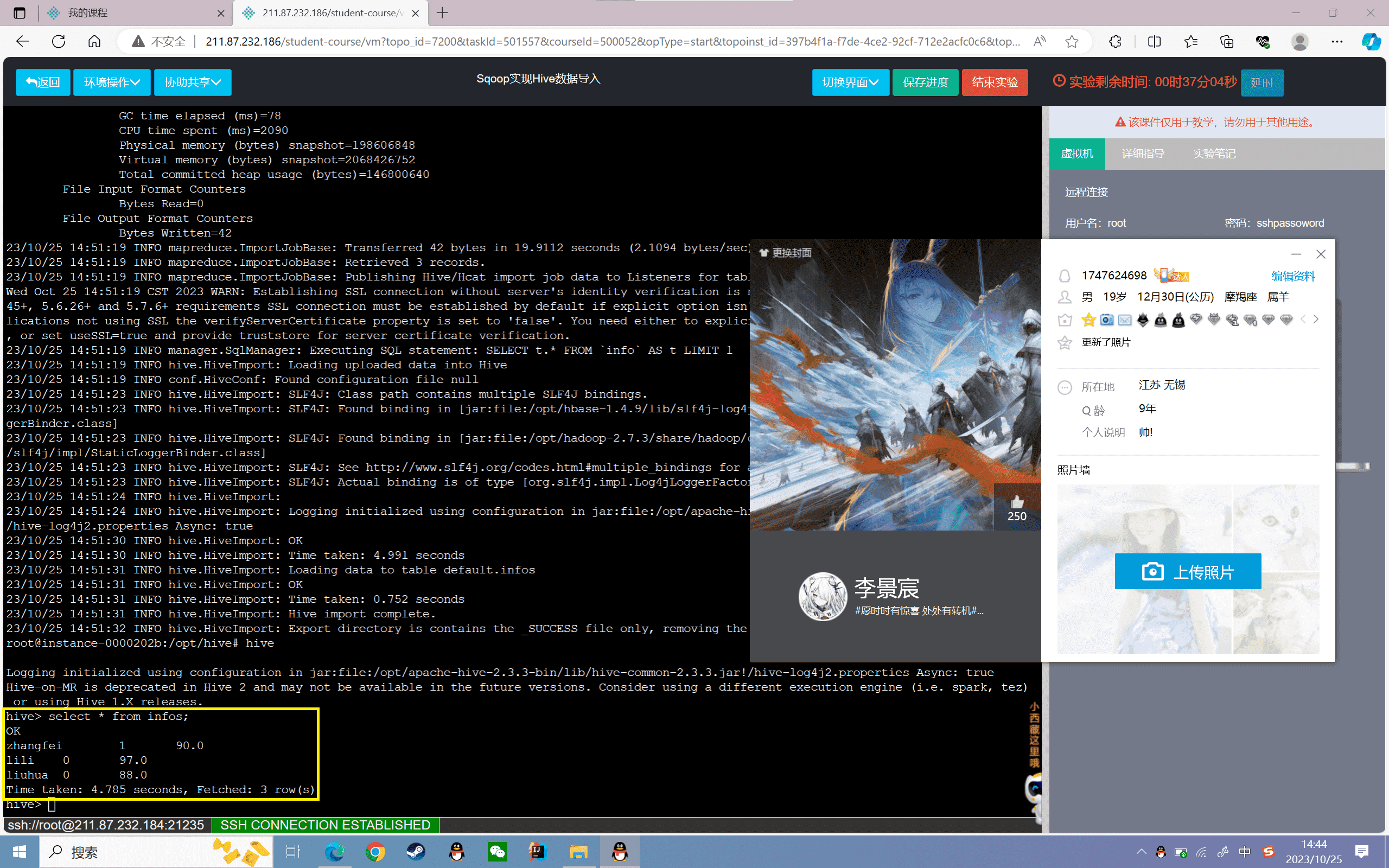
5、查看数据
1 | hive> select * from infos; |
覆盖导入
6、使用Sqoop将Mysql的info表字段信息复制到Hive中info中
1 | sqoop import --connect jdbc:mysql://localhost:3306/data --username root --password root --table info --m 1 --hive-import --hive-table info --hive-overwrite --fields-terminated-by ',' |
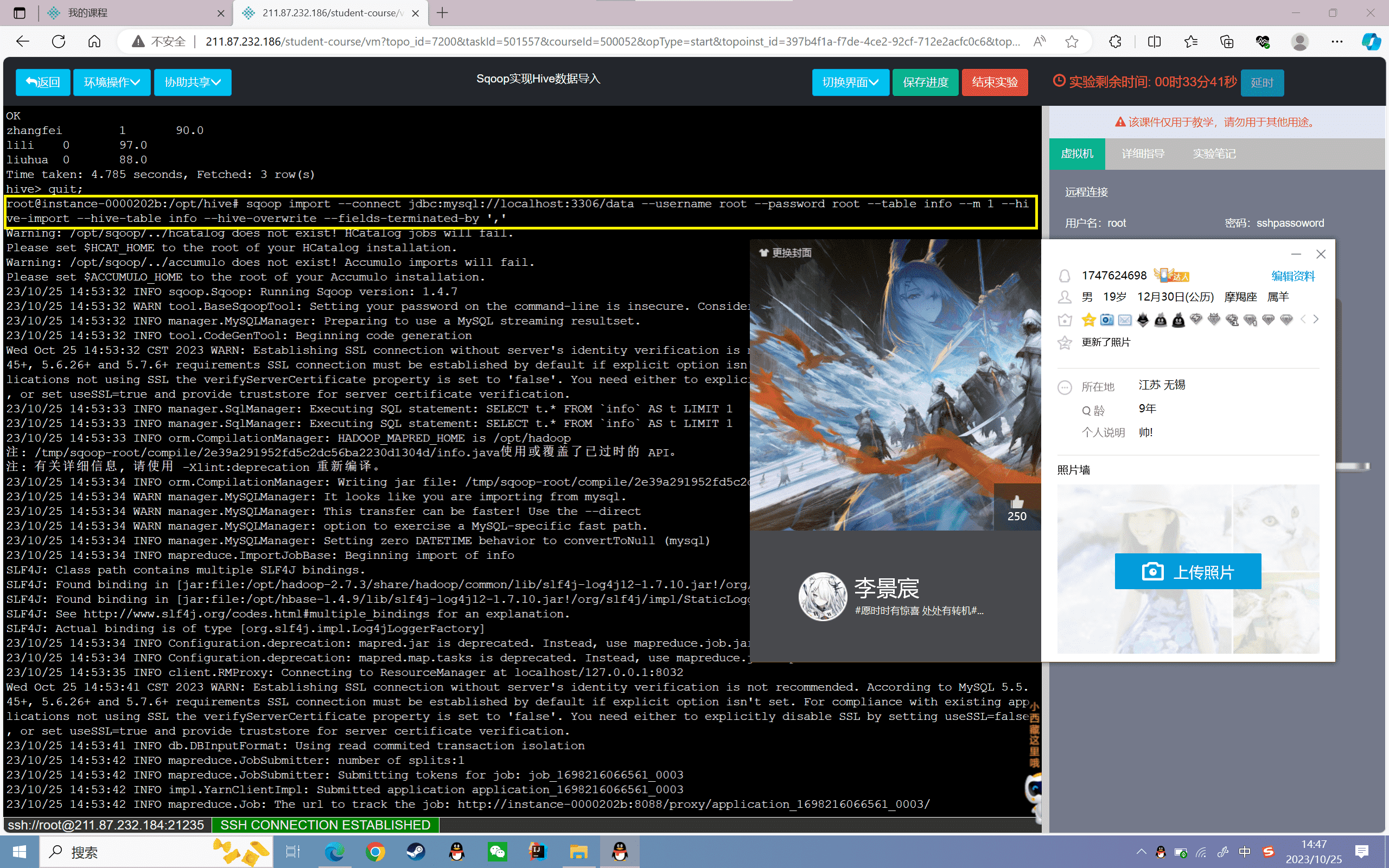
7、查看数据
1 | hive> select * from info; |
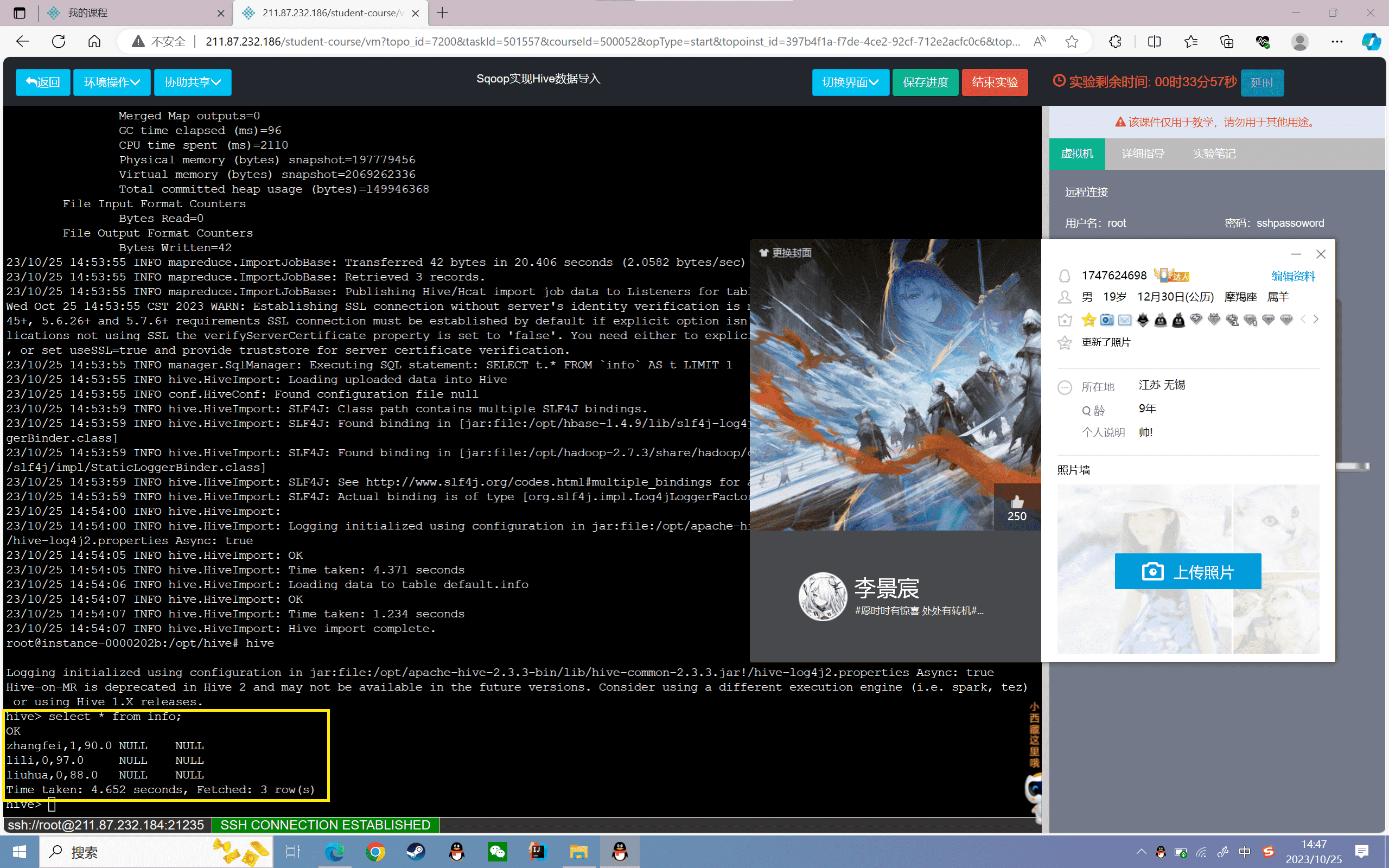
可以发现Hive的数据没有发生变化
使用Sqoop导入Hive分区
1、在MySQL中创建student表(id、name、score)
1 | mysql> use data; |
2、插入数据:
1 | mysql> insert into student(id,name,score)value(1,'xiaoming',75); |
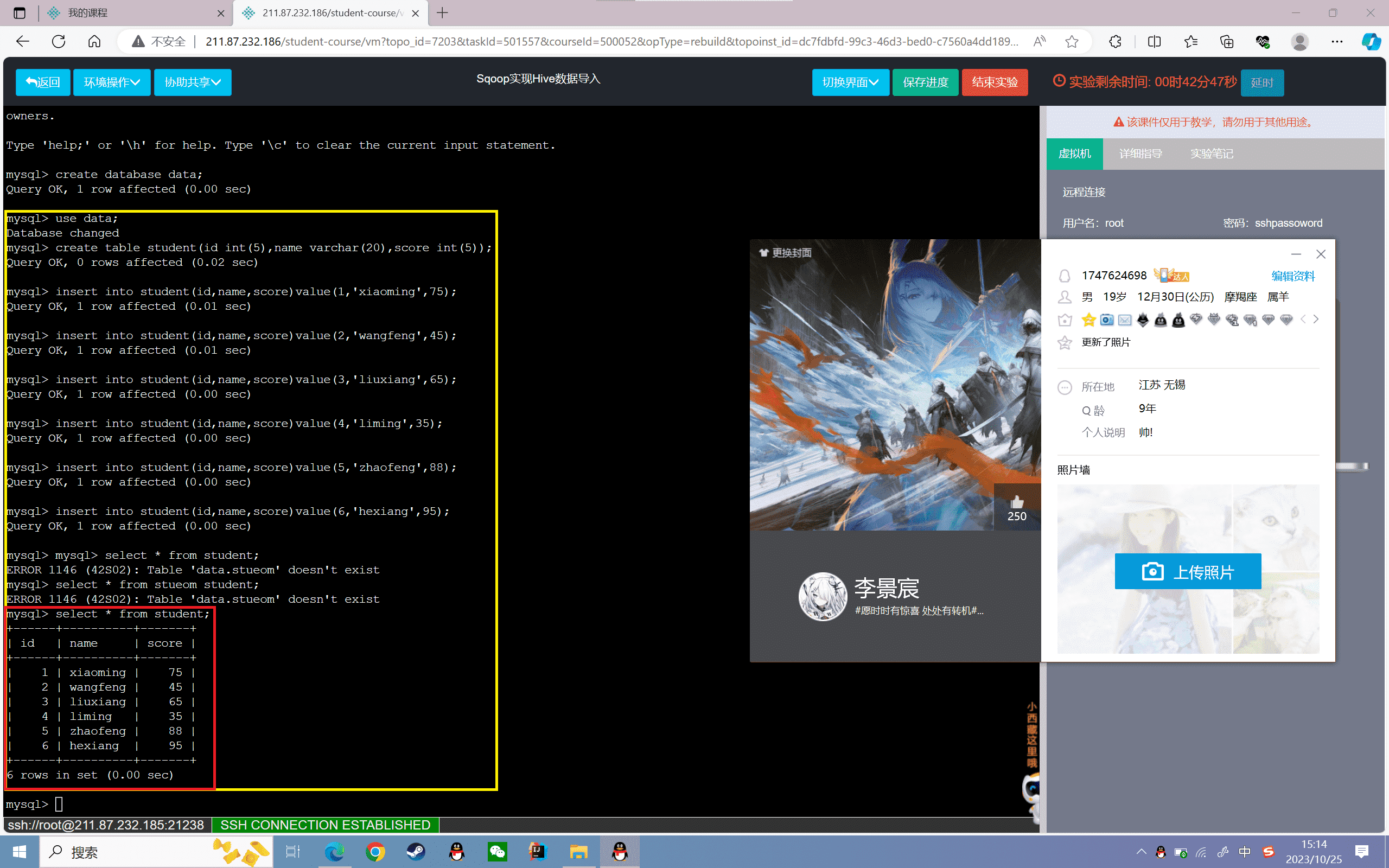
3、将MySQL的student表数据导入Hive的student表的“2019-10-22”分区中
1 | sqoop import --connect jdbc:mysql://localhost:3306/data --username root --password root --table student --m 1 --hive-import --hive-table student --hive-partition-key 'dates' --hive-partition-value '2019-10-22' |
运行后发生如下错误,仔细阅读发现是HIVE_CONF_DIR的配置错误
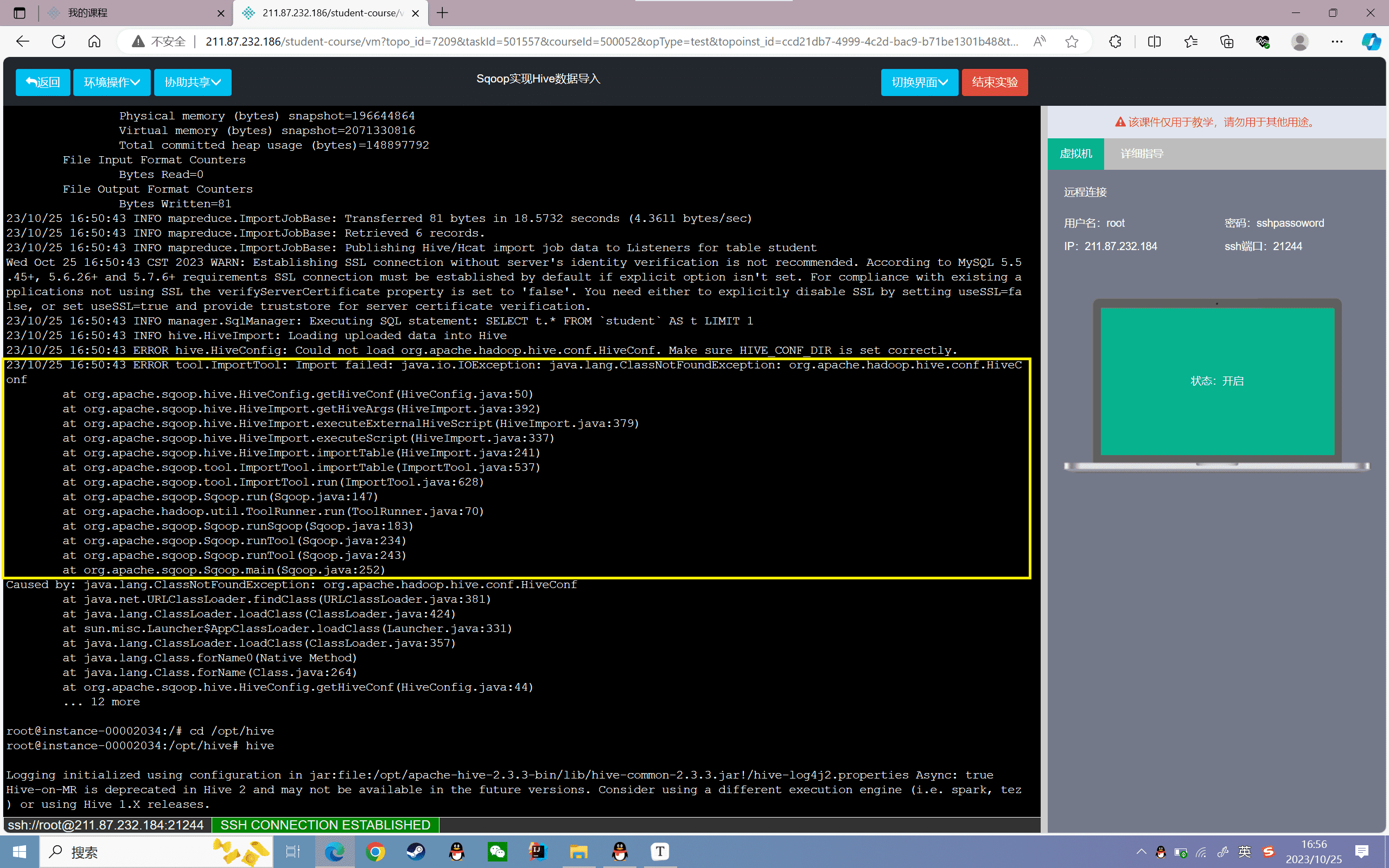
查询资料后得知,报错原因是sqoop缺少hive的相关jar包,需要将将hive/lib中的hive-common-2.3.3.jar拷贝到sqoop的lib目录中
1 | cp /data/software/mysql-connector-java-5.1.45-bin.jar /opt/hive/lib/ |
再次执行发现如下错误:
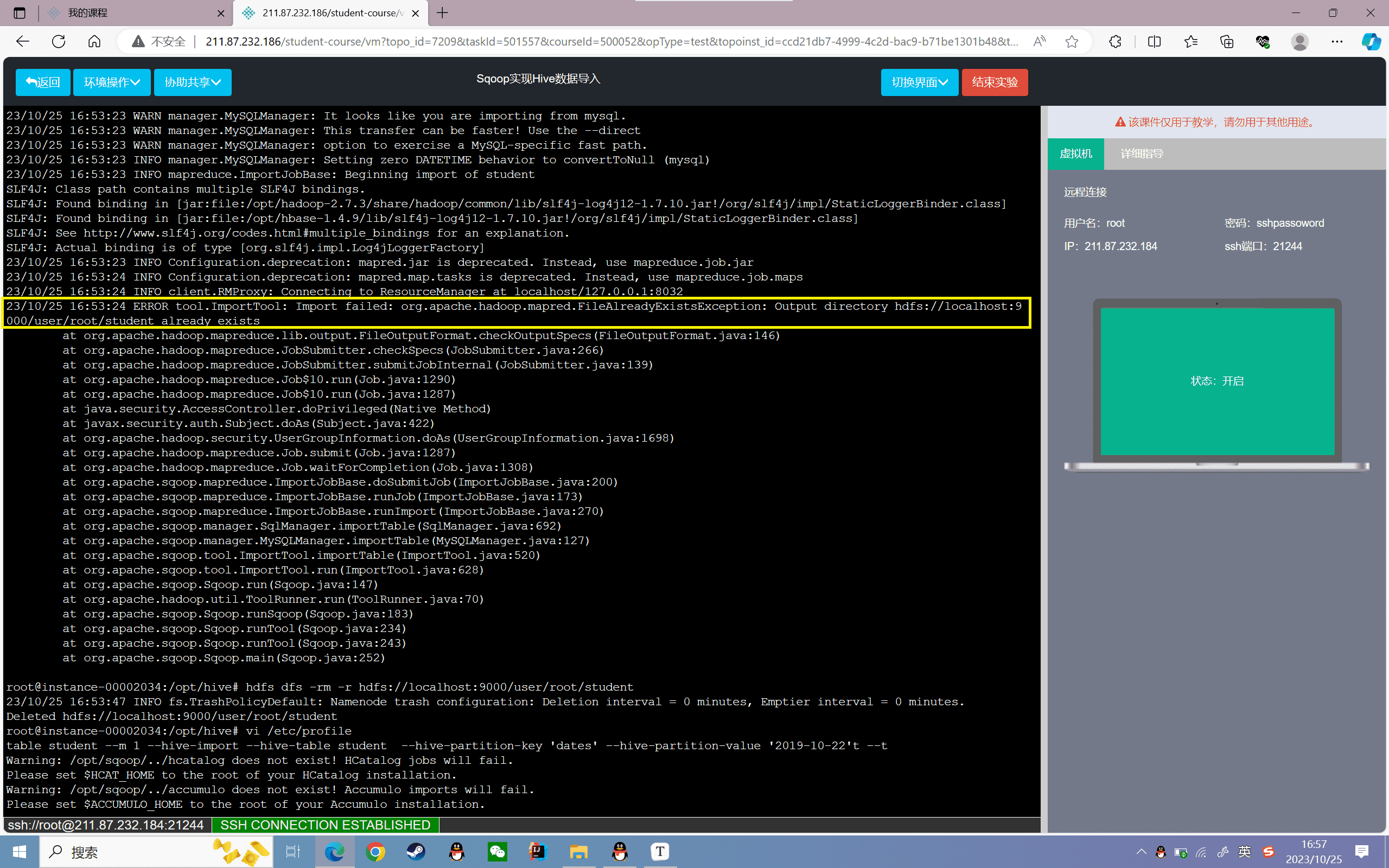
原因是文件已存在,解决办法很简单,直接删掉就行
1 | hdfs dfs -rm -r hdfs://localhost:9000/user/root/student |
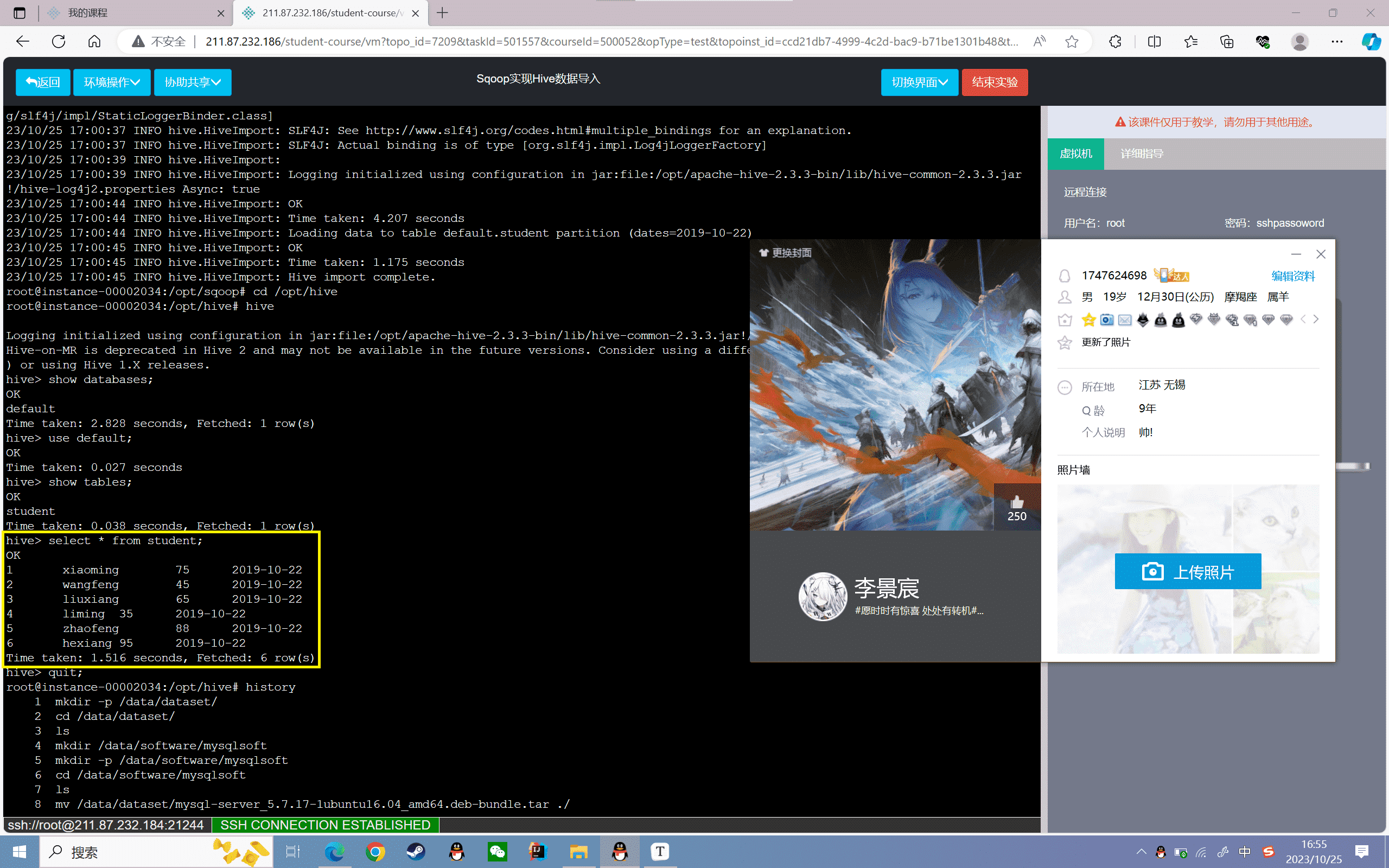
4、查看数据
1 | hive> select * from student; |
实验感悟
实验中,我先创建了MySQL的数据库和表,插入了测试数据。然后通过sqoop create-hive-table可以将MySQL表结构复制到Hive中创建表。
接着就是导入数据了,可以用sqoop import实现直接导入和追加导入。还可以用–hive-overwrite参数实现覆盖导入。
最后我还尝试了导入到Hive分区表中,指定了分区字段和分区值,实现了聚簇存储。
Sqoop数据导入的原理是将命令转换为MapReduce任务,并行导入数据,速度很快。所以可以实现TB级别的大数据迁移。
通过这次实验,我掌握了Sqoop与Hive集成的方法,为大数据分析奠定了基础。还需要针对增量导入、压缩、迁移速度等方面继续优化。总体上,本实验达到了使用Sqoop导入Hive数据的目的,使我能够熟练应用这一重要工具。


