前言 这期来简单分享一下我制作淘宝二次元周边商品知识图谱的过程,简而言之,知识图谱就是将一些错综复杂的关系用可视化表达出来,
知识图谱概念 知识图谱(Knowledge Graph)是人工智能的重要分支技术,它在2012年由谷歌提出,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。
具体分类 知识图谱按照功能和应用场景可以分为通用知识图谱和领域知识图谱。其中通用知识图谱面向的是通用领域,强调知识的广度,形态通常为结构化的百科知识,针对的使用者主要为普通用户;领域知识图谱则面向某一特定领域,强调知识的深度,通常需要基于该行业的数据库进行构建,针对的使用者为行业内的从业人员以及潜在的业内人士等。
实践作用 互联网的终极形态是万物互联,而搜索的终极目标是对万物直接进行搜索。传统的搜索是靠网页之间的超链接实现网页的搜索,而语义搜索是直接对事物进行搜索,比如人、物、机构、地点等,这些事物可以来自文本、图片、视频、音频、物联网设备等。知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,这样搜索引擎就可以直接对事物进行搜索。比如我们想知道“《觉醒年代》的导演是谁?”,那么在进行搜素时,搜索引擎会把这句话进行分解,获得“《觉醒年代》”,“导演”,再与现有的知识库中的词条进行匹配,最后展现在用面前。传统的搜索模式下,我们进行这样的搜索后得到的通常是包含其中关键词的网页链接,我们还需要在多个网页中进行筛选。可以看出基于知识图谱的搜索更加便捷与准确。
构建过程 下面我们来具体看看简单的知识图谱是如何构建的。
数据采集 鉴于一些电商平台都有比较完善的反扒机制,在数次尝试后,选择了淘宝作为我的数据源,此爬虫可以稳定完整的获取信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import reimport requestsimport jsonimport csvimport timewith open ('taobao.csv' , 'w' , encoding='ANSI' , newline='' ) as filename: csvwriter = csv.DictWriter(filename, fieldnames=['标题' , '价格' , '店铺' , '购买人数' , '地点' , '商品详情页' , '店铺链接' , '图片链接' ]) csvwriter.writeheader() for i in range (1 , 100 ): time.sleep(2 ) url = f'https://s.taobao.com/search?q=%E8%88%AA%E5%A4%A9%E6%96%87%E5%88%9B&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221026&ie=utf8&bcoffset=2&ntoffset=2&p4ppushleft=2%2C48&s={i * 44 } ' headers = { 'cookie' :'我的cookie' , 'sec-ch-ua' : '"Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"' , 'sec-ch-ua-mobile' : '?0' , 'sec-ch-ua-platform' : "Windows" , 'sec-fetch-dest' : 'document' , 'sec-fetch-mode' : 'navigate' , 'sec-fetch-site' : 'same-origin' , 'upgrade-insecure-requests' : '1' , 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36' } response = requests.get(url=url, headers=headers) html_data = re.findall('g_page_config = (.*);' , response.text)[0 ] json_data = json.loads(html_data) data = json_data['mods' ]['itemlist' ]['data' ]['auctions' ] for index in data: try : dict = { '标题' : index['raw_title' ], '价格' : index['view_price' ], '店铺' : index['nick' ], '购买人数' : index['view_sales' ], '地点' : index['item_loc' ], '商品详情页' : 'https:' + index['detail_url' ], '店铺链接' : 'https:' + index['shopLink' ], '图片链接' : 'https:' + index['pic_url' ] } csvwriter.writerow(dict ) print (dict ) except Exception as e: print (e)
然后对爬取的数据进行清洗,去掉重复且不完整的信息,得到一张包含了标题 ,价格,店铺,购买人数,地点,商品详情页,店铺链接和图片链接的表格,下面,我们将根据这些信息,构建知识图谱。
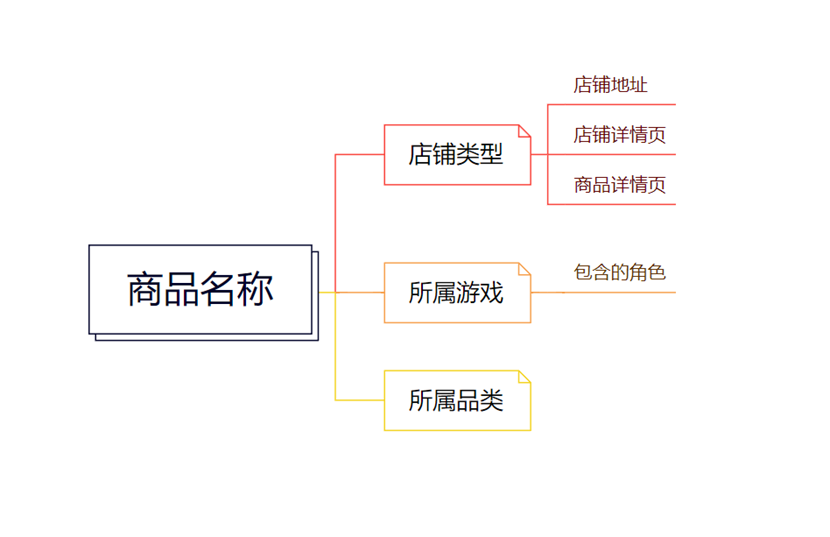
实体抽取 这里将可爬取的商品维度作为实体要素,即商品名称、店铺名称、商品种类、店铺属地等,将这些作为节点进行构建。
关系抽取 就像上图所描述的,商品所属游戏包含游戏角色,那么描述游戏的node和描述角色的node之间就应该用包含属性的relationship来描述。
1 2 3 4 node_game = Node('game' , name=data[i][2 ]) node_character = Node('character' , name=data[i][4 ]) character = Relationship(node_game, '角色' , node_character) graph.create(character)
建模过程 使用py2neo模块进行操作,通过以下代码实现连接neo4j,循环创建节点和关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from py2neo import Graph, Node, Relationshipimport csvgraph = Graph("http://localhost:7474" , auth=("neo4j" , "JC20031230" )) graph.delete_all() with open ('C:\\Users\\Jc\\Desktop\\clear.CSV' , 'r' ) as f: reader = csv.reader(f) data = list (reader) for i in range (1 , len (data)): node_name = Node('product name' , name=data[i][0 ]) node_shop = Node('shop' , name=data[i][1 ]) node_game = Node('game' , name=data[i][2 ]) node_usage = Node('usage' , name=data[i][3 ]) node_character = Node('character' , name=data[i][4 ]) node_location1 = Node('location1' , name=data[i][5 ]) node_location2 = Node('location2' , name=data[i][6 ]) node_url_product = Node('url_product' , name=data[i][7 ]) node_url_shop = Node('url_shop' , name=data[i][8 ]) node_url_picture = Node('url_picture' , name=data[i][9 ]) graph.create(node_name) graph.create(node_shop) graph.create(node_game) graph.create(node_usage) graph.create(node_character) graph.create(node_location1) graph.create(node_location2) graph.create(node_url_picture) graph.create(node_url_product) graph.create(node_url_shop) shop = Relationship(node_name, '店铺类型' , node_shop) game = Relationship(node_name, '游戏' , node_game) usage = Relationship(node_name, '品类' , node_usage) graph.create(shop) graph.create(game) graph.create(usage) location1 = Relationship(node_shop, '地区' , node_location1) graph.create(location1) location2 = Relationship(node_shop, '地区' , node_location2) graph.create(location2) url1 = Relationship(node_shop, '店铺链接' , node_url_shop) url2 = Relationship(node_shop, '图片链接' , node_url_picture) url3 = Relationship(node_shop, '详情页链接' , node_url_product) graph.create(url1) graph.create(url2) graph.create(url3) character = Relationship(node_game, '角色' , node_character) graph.create(character)
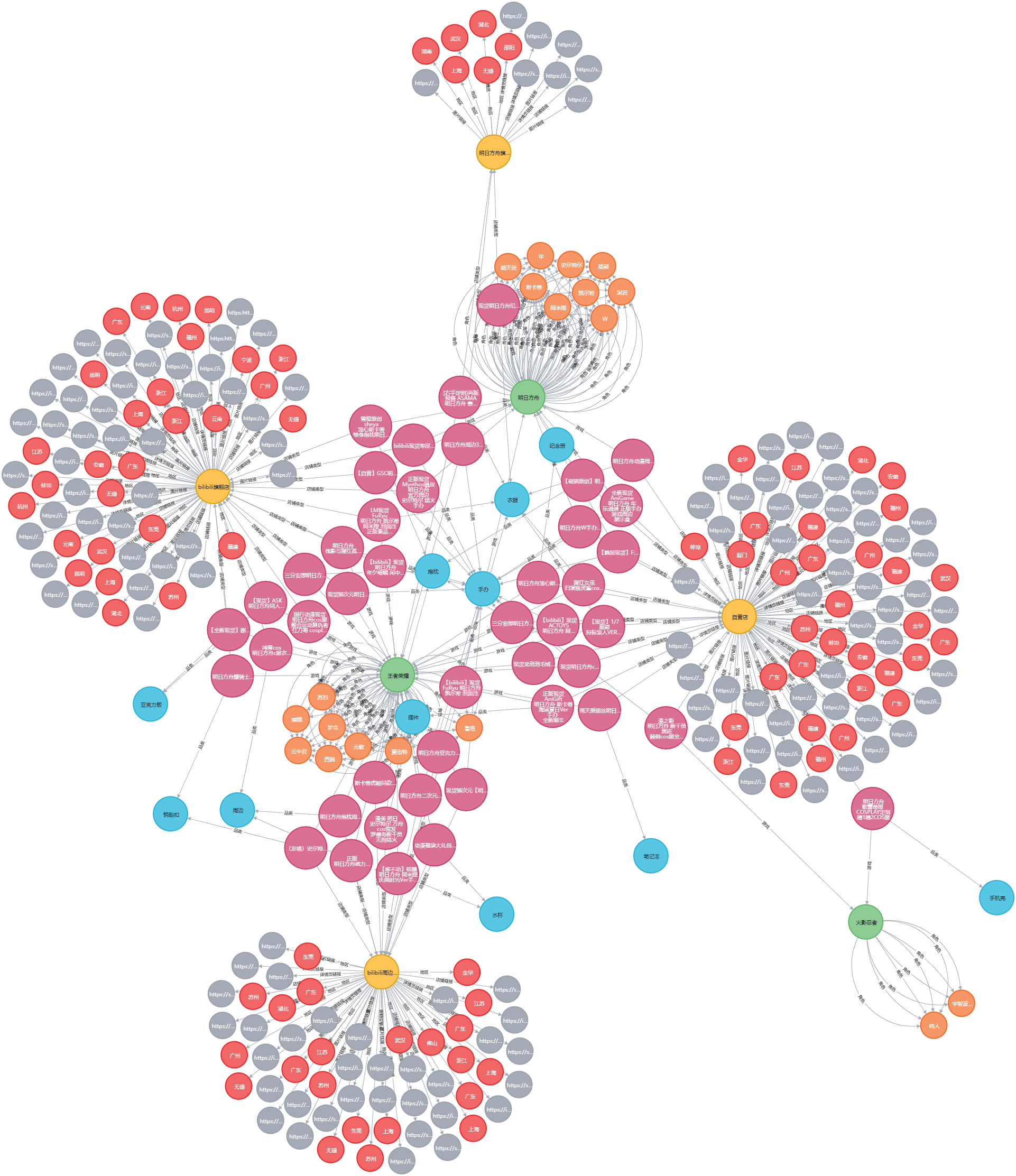
在构建完知识图谱后,我们发现存在不少重复的同名节点,于是使用neo4j-driver进行cypher命令操作,去除重复节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from neo4j import GraphDatabaseuri = "bolt://localhost:7687" driver = GraphDatabase.driver(uri, auth=("neo4j" , "JC20031230" )) with driver.session() as session: session.run("MATCH (n:shop) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL " "apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node" ) session.run("MATCH (n:usage) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL " "apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node" ) session.run("MATCH (n:character) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 " "CALL apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node" ) driver.close()
这样,就完成了最基本的知识图谱的构建